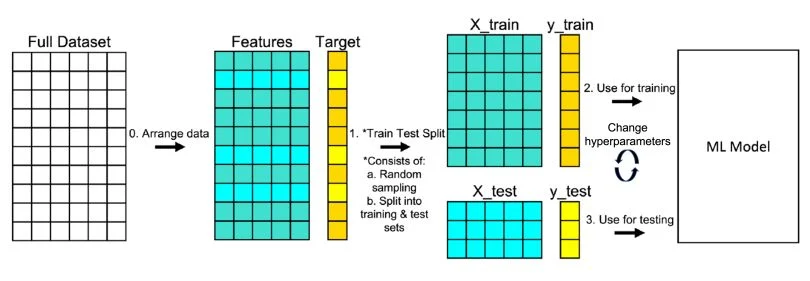
Dans le développement d’un modèle de Machine Learning, la question la plus importante n’est pas “Quelle est la précision du modèle sur mes données ?”, mais plutôt “Quelle sera sa précision sur des données qu’il n’a jamais vues ?”. Pour répondre à cela, nous utilisons une technique fondamentale : le Train-Test Split. Elle consiste à diviser votre jeu de données initial en deux parties distinctes : une pour l’entraînement et une pour le test. Sans cette séparation, vous risquez de tomber dans le piège du sur-apprentissage (overfitting), où votre modèle “apprend par cœur” vos données au lieu de comprendre les tendances générales. Chez DATAROCKSTARS, nous enseignons que la rigueur de cette division est ce qui garantit la fiabilité et la robustesse d’une solution d’IA en production.
1. Le concept : Ne jamais tester avec ce qu’on a appris
Imaginez un étudiant qui prépare un examen en mémorisant les réponses d’un annale. Si l’examen final pose exactement les mêmes questions, l’étudiant aura 20/20, mais saura-t-il résoudre un nouveau problème ? Probablement pas. C’est le même principe pour l’IA.
Le jeu d’entraînement (Train Set) sert à construire le modèle, tandis que le jeu de test (Test Set) sert d’examen final pour évaluer sa capacité de généralisation. Chez DATAROCKSTARS, nous insistons sur l’étanchéité totale entre ces deux jeux : aucune information du Test Set ne doit fuiter dans le processus d’entraînement.
2. Les proportions standards : 80/20 ou 70/30 ?
Le choix de la proportion dépend de la taille de votre dataset. La règle classique est de dédier 80 % des données à l’entraînement et 20 % au test. Si vous avez des millions de lignes, un split 95/5 peut suffire car 5 % représente déjà un échantillon statistiquement significatif.
Dans nos bootcamps, nous apprenons à ajuster ces curseurs. L’objectif est d’avoir assez de données pour que le modèle apprenne les motifs complexes, tout en gardant assez de données de test pour que l’évaluation soit robuste et non soumise au hasard.
3. Le rôle du Random State : Assurer la reproductibilité
Lorsque vous divisez vos données, vous le faites de manière aléatoire pour éviter tout biais (par exemple, si vos données sont triées par date). Cependant, pour pouvoir comparer deux modèles, vous devez utiliser exactement le même split.
C’est là qu’intervient le paramètre random_state. En fixant une graine (un nombre entier), vous garantissez que la division sera identique à chaque exécution du code. Chez DATAROCKSTARS, c’est une règle de “Data Hygiene” que nous imposons : la reproductibilité est la base de toute démarche scientifique sérieuse.
4. Le piège de la fuite de données (Data Leakage)
La fuite de données survient lorsque des informations du Test Set se retrouvent par erreur dans le Train Set (par exemple, si vous normalisez vos données avant le split). Le modèle “voit” alors indirectement les réponses de l’examen final, ce qui donne des résultats de précision artificiellement élevés.
Identifier et prévenir le Data Leakage est une compétence de haut niveau. Dans notre Bootcamp Data Engineer & AIOps, nous formons nos étudiants à construire des pipelines de données (Transformers) qui garantissent que les transformations sont apprises sur le Train Set et appliquées uniquement ensuite au Test Set.
5. Stratification : Préserver l’équilibre des classes
Si vous travaillez sur un problème de classification déséquilibré (par exemple, détecter une fraude qui n’arrive que dans 1 % des cas), un split aléatoire classique pourrait vider le Test Set de tous les cas de fraude.
La stratification permet de conserver la proportion des classes dans chaque sous-ensemble. Chez DATAROCKSTARS, nous apprenons à utiliser le paramètre stratify de Scikit-Learn pour s’assurer que l’évaluation est représentative de la réalité du terrain, évitant ainsi des modèles aveugles aux événements rares mais critiques.
6. Train-Validation-Test : Le split en trois étapes
Pour les projets complexes où vous devez ajuster des hyperparamètres, deux jeux de données ne suffisent plus. On crée alors un troisième jeu : le Validation Set.
- Train : Pour entraîner le modèle.
- Validation : Pour tester différentes versions du modèle et choisir la meilleure.
- Test : Pour l’évaluation finale et définitive.
Cette structure évite de “sur-ajuster” votre modèle au Test Set à force de faire des essais-erreurs. C’est la méthodologie standard que nous appliquons dans nos projets industriels.
7. Cross-Validation : Pousser la validation au niveau supérieur
Parfois, un seul split ne suffit pas, surtout sur de petits datasets. On utilise alors la K-Fold Cross-Validation. On divise les données en K parties, et on entraîne le modèle K fois, en utilisant à chaque fois une partie différente comme jeu de test.
Cela donne une vision beaucoup plus stable de la performance du modèle. Chez DATAROCKSTARS, nous considérons la Cross-Validation comme l’outil ultime pour valider la robustesse d’un algorithme avant son déploiement.
8. L’implémentation pratique avec Scikit-Learn
En Python, l’outil de référence est la fonction train_test_split de la bibliothèque sklearn.model_selection. Elle permet de réaliser l’opération en une seule ligne de code, tout en gérant l’aléatoire et la stratification.
Maîtriser les paramètres de cette fonction (test_size, random_state, shuffle) est le b.a.-ba du Data Scientist. Dans nos exercices pratiques, nous vous faisons manipuler ces options pour comprendre leur impact direct sur la qualité de vos prédictions.
9. Le split temporel : Le cas particulier des Time Series
Attention ! Si vos données sont temporelles (cours de bourse, météo), vous ne pouvez pas utiliser un split aléatoire. On ne peut pas prédire le passé avec le futur. Vous devez utiliser un split chronologique : on entraîne sur les données passées et on teste sur les données futures.
Ne pas respecter cette règle est l’erreur numéro un des débutants en analyse de séries temporelles. Chez DATAROCKSTARS, nous dédions des modules spécifiques à cette problématique pour que vos modèles respectent toujours la flèche du temps.
10. Pourquoi maîtriser le Train-Test Split avec DATAROCKSTARS
Le Train-Test Split n’est pas qu’une ligne de code, c’est une philosophie de travail. Savoir valider correctement son travail est ce qui distingue un bricoleur d’un ingénieur IA d’élite. Les entreprises recherchent des profils capables de garantir que leurs modèles fonctionneront dans le monde réel, pas seulement dans un notebook.
Chez DATAROCKSTARS, nous vous donnons la rigueur méthodologique pour construire des systèmes d’intelligence artificielle fiables et éthiques. Rejoignez nos cursus pour maîtriser tout le cycle de vie de la donnée, de la collecte à la validation finale. Souhaitez-vous découvrir comment notre Bootcamp Data Scientist & AI peut vous aider à transformer vos données en prédictions infaillibles ?
Merci pour votre lecture ! Si vous souhaitez découvrir nos prochains articles autour de la Data et de l’IA, vous pouvez nous suivre sur Facebook, LinkedIn et Twitter pour être notifié dès la publication d’un nouvel article !