Le Quick Sort (ou tri rapide) est un algorithme de tri inventé par Tony Hoare en 1959. Il repose sur le paradigme “Diviser pour régner” (Divide and Conquer). C’est l’un des algorithmes les plus performants en pratique, souvent utilisé dans les bibliothèques standards de langages comme C++, Java ou Python pour trier de grands ensembles de données.
Chez DATAROCKSTARS, nous enseignons que le Quick Sort est un exemple parfait d’optimisation algorithmique. Pour un Data Scientist ou un Data Engineer, comprendre la logique récursive et le choix du pivot est essentiel pour appréhender la complexité temporelle et l’efficacité des traitements de données massives.
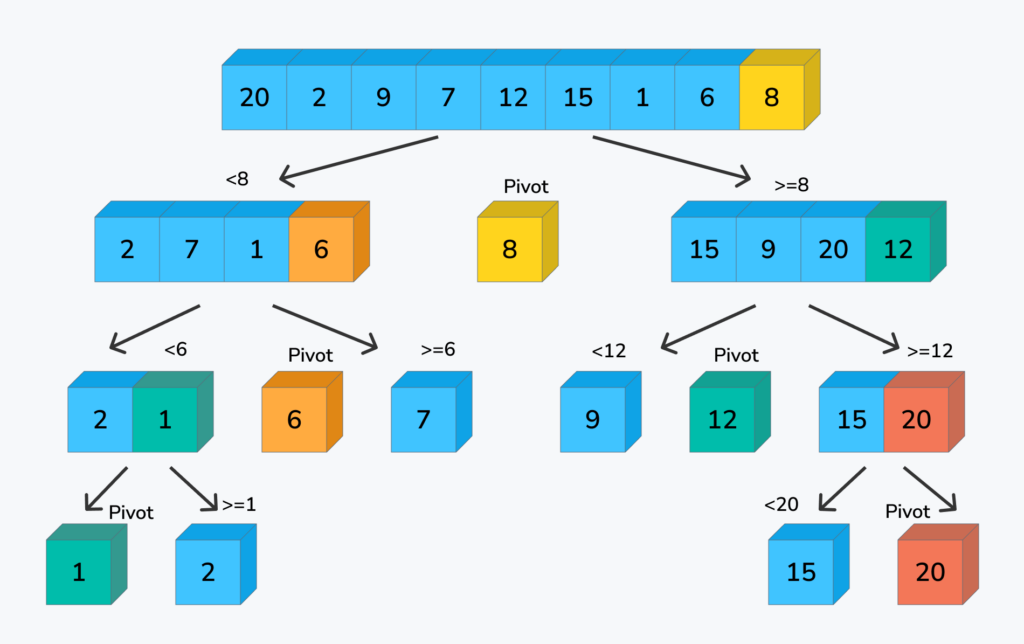
1. Le principe du “Diviser pour régner”
Le Quick Sort transforme un problème complexe en sous-problèmes plus simples à résoudre. Son fonctionnement repose sur trois étapes clés :
Le choix du Pivot : On sélectionne un élément de la liste (le pivot).
Le Partitionnement : On réorganise la liste pour que tous les éléments inférieurs au pivot soient à sa gauche, et tous les éléments supérieurs à sa droite.
La Récursion : On applique récursivement la même opération aux deux sous-listes créées (gauche et droite) jusqu’à ce que la liste entière soit triée.
2. Le partitionnement : L’étape cruciale
Le cœur de l’algorithme réside dans sa capacité à placer le pivot à sa position définitive en un seul passage. Une fois le partitionnement terminé, le pivot ne bougera plus jamais.
L’efficacité du Quick Sort dépend énormément de la manière dont les éléments sont répartis de part et d’autre du pivot. Un bon partitionnement équilibre les deux sous-listes, ce qui permet de diviser la charge de travail par deux à chaque étape.
3. La complexité du Quick Sort
La performance du Quick Sort varie selon la disposition initiale des données et le choix du pivot :
Meilleur cas et Cas moyen : $O(n \log n)$. C’est ici que l’algorithme brille par sa rapidité exceptionnelle sur de gros volumes.
Pire cas : $O(n^2)$. Cela arrive si le pivot choisi est systématiquement le plus petit ou le plus grand élément (par exemple, si on essaie de trier une liste déjà triée en prenant toujours le premier élément comme pivot).
Pour éviter le pire cas, les implémentations modernes utilisent souvent un pivot choisi de manière aléatoire ou la méthode de la “médiane de trois”.
4. Choix du Pivot : Stratégies de Rockstar
Il existe plusieurs stratégies pour sélectionner le pivot :
Premier ou dernier élément : Simple mais risqué sur des listes déjà triées.
Élément central : Plus stable.
Pivot aléatoire : Garantit statistiquement d’éviter le pire cas de $O(n^2)$.
Médiane de trois : On prend la médiane entre le premier, le milieu et le dernier élément pour assurer un meilleur équilibre.
Chez DATAROCKSTARS, nous apprenons à nos étudiants à anticiper ces scénarios pour garantir que leurs pipelines de données restent performants, peu importe la structure des données entrantes.
5. Quick Sort vs Merge Sort
Bien que les deux utilisent le “diviser pour régner”, ils diffèrent sur un point majeur : la mémoire.
Merge Sort : Nécessite un espace mémoire supplémentaire pour fusionner les listes.
Quick Sort : Est un tri “en place” (in-place). Il modifie directement la liste d’origine sans avoir besoin de créer de copies massives. C’est un avantage énorme en termes de gestion des ressources système.
[Image comparing Quick Sort in-place partitioning vs Merge Sort auxiliary array usage]
6. Pourquoi est-il si rapide en pratique ?
Malgré un pire cas théorique en $O(n^2)$, le Quick Sort est souvent plus rapide que le Merge Sort ou le Heap Sort sur des machines réelles. Pourquoi ?
Parce qu’il interagit très bien avec la mémoire cache des processeurs. En travaillant sur des segments locaux de la liste, il limite les transferts de données coûteux entre la RAM et le processeur. C’est cette compréhension “hardware” que nous valorisons chez DATAROCKSTARS.
7. Implémentation type en Python
Voici à quoi ressemble la logique simplifiée du Quick Sort :
Python
def quicksort(arr):
if len(arr) <= 1:
return arr
pivot = arr[len(arr) // 2]
left = [x for x in arr if x < pivot]
middle = [x for x in arr if x == pivot]
right = [x for x in arr if x > pivot]
return quicksort(left) + middle + quicksort(right)
En production, on utilise des versions plus complexes pour optimiser l’espace mémoire (tri in-place), mais cette structure illustre parfaitement la puissance de la récursion.
8. Pourquoi maîtriser les algorithmes avec DATAROCKSTARS
Dans un monde où les outils “No-Code” se multiplient, la maîtrise des algorithmes fondamentaux comme le Quick Sort est ce qui distingue un technicien d’un ingénieur d’élite. Savoir comment les données sont manipulées “sous le capot” permet d’optimiser les coûts cloud et d’accélérer les temps de réponse de vos modèles d’IA.
Chez DATAROCKSTARS, nous transformons ces concepts abstraits en compétences pratiques pour l’industrie. Prêt à optimiser vos performances ? Souhaitez-vous découvrir comment notre Bootcamp Data Scientist & AI Engineer peut vous aider à maîtriser l’ingénierie algorithmique pour propulser votre carrière ?
Merci pour votre lecture ! Si vous souhaitez découvrir nos prochains articles autour de la Data et de l’IA, vous pouvez nous suivre sur Facebook, LinkedIn et Twitter pour être notifié dès la publication d’un nouvel article !