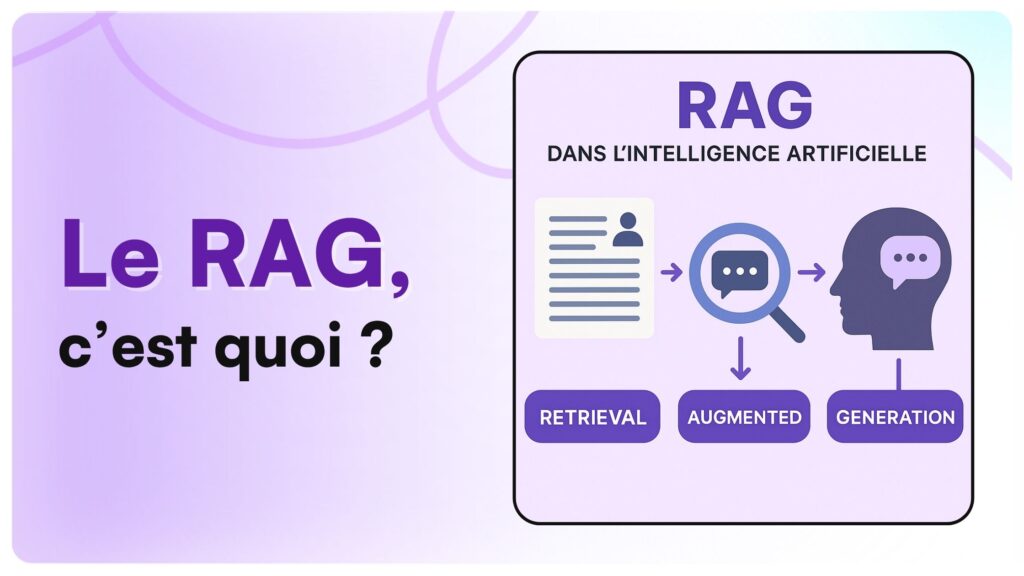
Le RAG (Retrieval-Augmented Generation) est devenu le standard industriel pour déployer des Large Language Models (LLM) en entreprise. Si les modèles comme GPT-4 sont impressionnants par leur culture générale, ils souffrent de deux limites majeures : ils ne connaissent pas vos données privées et ils peuvent “halluciner” en inventant des faits. Le RAG résout ces problèmes en agissant comme un pont entre la puissance de raisonnement du modèle et votre propre base de connaissances. Au lieu de compter sur la mémoire interne du modèle, le système va chercher l’information pertinente dans vos documents avant de générer une réponse. Chez DATAROCKSTARS, nous considérons le RAG comme la brique fondamentale de l’IA appliquée, permettant de transformer un simple chatbot en un expert métier infaillible.
1. Le concept : “Examen à livre ouvert” pour l’IA
Pour comprendre le RAG, imaginez la différence entre un étudiant qui passe un examen de mémoire et un étudiant qui a le droit d’utiliser ses manuels. Le LLM classique est l’étudiant de mémoire : il peut se tromper sur les détails. Le RAG est l’étudiant avec ses livres : il cherche la réponse dans la documentation fournie et la reformule.
Cette approche garantit que l’IA reste ancrée dans la réalité de vos données. Si l’information n’est pas dans vos documents, le système peut être configuré pour dire “Je ne sais pas” plutôt que d’inventer une réponse. Cette fiabilité est ce que nous enseignons en priorité dans notre Bootcamp Data Scientist & AI, car la confiance est le premier critère d’adoption de l’IA par les métiers.
2. Étape 1 : L’ingestion et la vectorisation des données
Avant de pouvoir interroger vos données, il faut les préparer. Le texte est découpé en petits morceaux (chunks), puis transformé en vecteurs mathématiques grâce à un modèle d’embedding. Ces vecteurs capturent le sens sémantique des phrases : deux phrases ayant un sens proche seront proches dans cet espace mathématique.
Ces vecteurs sont ensuite stockés dans une base de données vectorielle (comme Pinecone, Weaviate ou ChromaDB). Chez DATAROCKSTARS, nous apprenons à nos étudiants à choisir la bonne stratégie de découpage (chunking strategy), car c’est la qualité de cette préparation qui détermine la précision future de l’IA.
3. Étape 2 : Le Retrieval (La récupération)
Quand un utilisateur pose une question, le système ne l’envoie pas directement au LLM. Il transforme d’abord la question en vecteur et cherche les morceaux de documents les plus similaires dans la base de données vectorielle. C’est l’étape de recherche sémantique.
Cette étape est cruciale car elle permet de fournir au modèle uniquement les informations pertinentes, économisant ainsi des tokens et évitant de noyer le modèle dans des données inutiles. Maîtriser les algorithmes de recherche de similarité est une compétence de pointe que nous développons dans notre Bootcamp Data Engineer & AIOps.
4. Étape 3 : L’Augmentation et la Génération
Une fois les documents pertinents récupérés, ils sont insérés dans le “prompt” envoyé au LLM. Le prompt ressemble alors à ceci : “En utilisant uniquement les informations suivantes : [Extraits de vos documents], réponds à la question : [Question utilisateur]”.
Le LLM utilise alors ses capacités de synthèse pour rédiger une réponse fluide et structurée basée sur les faits fournis. C’est l’étape finale du pipeline RAG. Chez DATAROCKSTARS, nous insistons sur l’importance du “system prompting” pour forcer le modèle à citer ses sources, garantissant ainsi une transparence totale pour l’utilisateur final.
5. RAG vs Fine-tuning : Quand choisir quoi ?
Beaucoup d’entreprises pensent qu’elles doivent ré-entraîner (fine-tuner) un modèle pour qu’il connaisse leurs données. C’est souvent une erreur coûteuse. Le Fine-tuning est excellent pour apprendre un nouveau style ou un jargon spécifique, mais il est médiocre pour injecter des connaissances factuelles qui changent souvent.
Le RAG est beaucoup plus flexible : si un document change, il suffit de mettre à jour son vecteur dans la base de données, et l’IA est instantanément à jour. Pour un architecte formé par DATAROCKSTARS, le RAG est presque toujours la solution de départ pour les projets d’IA documentaire en raison de son coût réduit et de sa maintenance simplifiée.
6. La gestion des hallucinations : Le garde-fou du RAG
Le RAG réduit drastiquement les hallucinations car le modèle est contraint par le contexte fourni. Si vous demandez à un système RAG le prix d’un produit qui n’est pas dans votre catalogue, il ne l’inventera pas s’il a reçu l’ordre strict de ne pas sortir du contexte.
C’est une avancée majeure pour la cybersécurité et la conformité. Dans nos formations en cybersécurité, nous expliquons comment le RAG permet de contrôler les flux d’information et d’éviter que l’IA ne devienne un vecteur de désinformation interne. La rigueur du pipeline RAG est votre meilleure protection juridique.
7. Les défis du RAG : Qualité des données et Latence
Le RAG n’est pas magique. Si vos documents sont mal structurés ou contradictoires, la réponse sera médiocre. De plus, le processus de recherche + génération ajoute de la latence par rapport à une simple requête LLM. L’optimisation de ces pipelines est un défi d’ingénierie complexe.
Nous formons nos ingénieurs à optimiser ces performances : mise en cache des requêtes fréquentes, utilisation de modèles d’embedding légers et parallélisation des recherches. Chez DATAROCKSTARS, nous vous apprenons à construire des systèmes qui ne sont pas seulement intelligents, mais aussi rapides et scalables en production.
8. L’évolution vers le “GraphRAG”
Le RAG classique cherche des morceaux de texte. Le GraphRAG va plus loin en utilisant des bases de données de graphes (comme Neo4j) pour comprendre les relations entre les entités (personnes, lieux, concepts). Cela permet de répondre à des questions transversales comme “Quels sont les points communs entre tous nos projets réalisés pour ce client ?”.
Cette technique représente la pointe de la recherche en IA actuelle. Dans nos cursus avancés, nous explorons comment combiner les vecteurs et les graphes pour offrir une intelligence contextuelle encore plus profonde. Maîtriser le GraphRAG, c’est se positionner comme un expert d’élite sur le marché de l’IA.
9. Les outils du marché : LangChain et LlamaIndex
Pour construire ces pipelines, deux frameworks dominent le marché : LangChain et LlamaIndex. Ils offrent des connecteurs pour toutes les sources de données (S3, Notion, Slack) et toutes les bases vectorielles. Ils facilitent l’orchestration des différentes étapes du RAG.
Chez DATAROCKSTARS, nous pratiquons intensivement sur ces outils. Apprendre à utiliser ces frameworks de manière professionnelle vous permet de construire des prototypes fonctionnels en quelques jours et de les industrialiser avec confiance. La maîtrise de ces outils est le ticket d’entrée pour les rôles de “AI Engineer” les mieux rémunérés.
10. Pourquoi se former au RAG avec DATAROCKSTARS
Le RAG est la compétence la plus demandée par les entreprises qui veulent réellement utiliser l’IA générative pour autre chose que du gadget. Savoir construire, sécuriser et optimiser un système RAG vous place au cœur de la stratégie technologique des organisations.
Chez DATAROCKSTARS, nous vous donnons les clés de cette architecture. Vous ne serez pas un simple spectateur de la révolution IA, vous en serez l’architecte. Rejoignez nos cursus pour maîtriser le cycle de vie complet d’une application RAG, de l’ingestion des données au déploiement en production. Souhaitez-vous découvrir comment notre Bootcamp Data Scientist & AI peut vous aider à dompter ces technologies et à transformer les données de votre entreprise en intelligence actionnable ?
Merci pour votre lecture ! Si vous souhaitez découvrir nos prochains articles autour de la Data et de l’IA, vous pouvez nous suivre sur Facebook, LinkedIn et Twitter pour être notifié dès la publication d’un nouvel article !