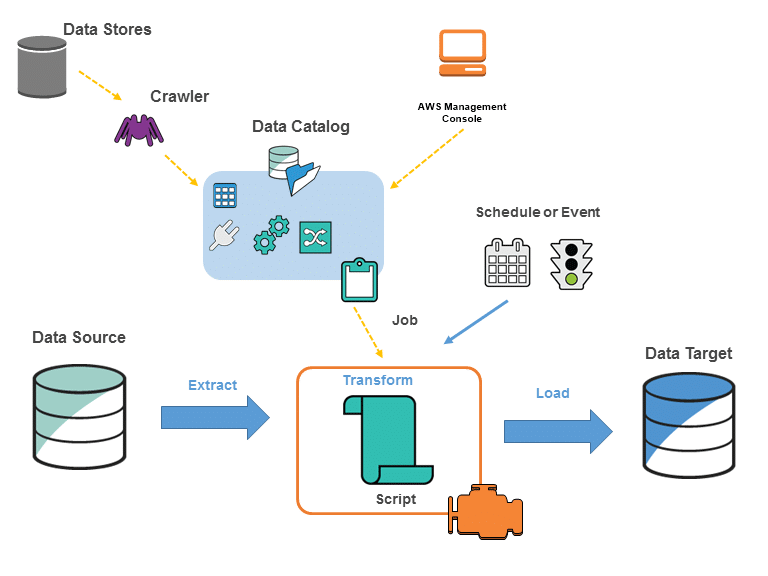
Dans l’écosystème AWS, les données sont le carburant de votre innovation, mais elles sont souvent éparpillées dans des silos disparates, formats hétérogènes et structures complexes. AWS Glue est la réponse native à ce défi : un service d’intégration de données “serverless” conçu pour découvrir, préparer, combiner et déplacer vos données à travers vos systèmes. Contrairement aux solutions ETL traditionnelles qui exigent une gestion fastidieuse de serveurs et de clusters, Glue abstrait toute la couche infrastructure. Pour un ingénieur de données moderne, maîtriser Glue, c’est passer moins de temps à gérer des machines et plus de temps à concevoir des pipelines de haute performance. Chez DATAROCKSTARS, nous observons que la maîtrise d’AWS Glue est devenue une compétence pivot pour tout architecte souhaitant industrialiser ses projets de Data Science ou d’Analytics.
1. La philosophie du Serverless appliquée à l’ETL
Le concept de “Serverless” est au cœur d’AWS Glue. Cela signifie concrètement que vous ne provisionnez aucun serveur, aucun cluster Hadoop ou Spark. Vous définissez simplement votre travail (le job), et AWS alloue les ressources de calcul nécessaires au moment précis où votre tâche s’exécute, puis les libère immédiatement après. C’est une économie de temps et de coûts opérationnels majeure pour les entreprises. Pour les ingénieurs, cela transforme radicalement la manière de travailler : on ne gère plus des capacités de calcul, on gère des flux de logique métier.
Cette approche permet une scalabilité horizontale quasi infinie. Que vous traitiez 1 gigaoctet ou 100 téraoctets de données, Glue ajuste automatiquement la puissance de calcul requise (les DPUs – Data Processing Units). Cette élasticité est indispensable en 2026, où les volumes de données sont imprévisibles. Chez DATAROCKSTARS, nous formons nos étudiants à concevoir ces architectures qui ne tombent jamais en panne de ressources, car comprendre le serverless, c’est aussi savoir optimiser la configuration de ces DPUs pour ne jamais payer pour du calcul inutilisé.
2. Le Glue Data Catalog : La boussole de votre lac de données
L’un des défis majeurs dans un Data Lake, c’est de savoir ce que contiennent réellement vos fichiers. Le Glue Data Catalog agit comme un registre centralisé, un inventaire permanent de vos données. Il stocke les métadonnées (schémas, formats, types de fichiers) de toutes vos sources de données, qu’elles soient dans S3, RDS, Redshift ou des bases tierces. Sans ce catalogue, vous seriez face à un océan de fichiers non identifiés.
Le Data Catalog n’est pas seulement un index, c’est le socle sur lequel repose toute votre gouvernance. Il permet aux outils comme Amazon Athena ou Amazon Redshift Spectrum de requêter vos fichiers S3 comme s’il s’agissait de tables SQL classiques. Apprendre à structurer et à maintenir ce catalogue est une compétence que nous approfondissons dans notre Bootcamp Data Engineer & AIOps. Un bon Data Engineer, c’est celui qui rend les données “découvrables” par les Data Scientists sans qu’ils aient à écrire une seule ligne de code pour comprendre la structure d’un fichier.
3. Glue ETL Jobs : L’automatisation par Apache Spark et Python
Sous le capot, AWS Glue exécute des jobs ETL basés sur Apache Spark ou Python (via PySpark). C’est une puissance de feu industrielle. Vous pouvez transformer vos données avec des scripts Python classiques, ou utiliser la puissance distribuée de Spark pour des jointures complexes, des agrégations ou des nettoyages de données à très grande échelle. Glue offre deux options : vous pouvez écrire vos propres scripts, ou laisser Glue générer automatiquement du code basé sur vos sources et vos destinations.
Chez DATAROCKSTARS, nous apprenons à nos étudiants à privilégier l’écriture de scripts personnalisés pour garder un contrôle total sur la logique métier. Savoir optimiser un script Spark — par exemple, en gérant correctement les partitions ou en évitant les “shuffles” coûteux en réseau — est ce qui fait la différence entre un job qui tourne en 5 minutes et un job qui bloque votre pipeline pendant 5 heures. C’est cette expertise en ingénierie de performance que vous développerez avec nous.
4. Glue Crawlers : Les explorateurs automatiques
Comment maintenir le Data Catalog à jour sans intervention humaine ? Grâce aux Glue Crawlers. Ce sont des agents autonomes qui scannent vos sources de données, détectent automatiquement les changements de schéma (ajout d’une colonne, changement de type), et mettent à jour votre Data Catalog en temps réel. C’est l’automatisation de la découverte de données.
Les Crawlers sont vitaux dans des environnements où les données arrivent en flux continu. Ils évitent cette tâche ingrate et répétitive de mise à jour manuelle des métadonnées. Cependant, un Crawler mal configuré peut polluer votre catalogue avec des tables erronées. Chez DATAROCKSTARS, nous formons aux bonnes pratiques de configuration : comment définir des filtres d’inclusion/exclusion précis, comment gérer les partitions de dossiers dans S3, et comment s’assurer que le catalogue reste une source de vérité propre et fiable pour toute l’organisation.
5. AWS Glue DataBrew : Le nettoyage visuel sans code
Parfois, écrire du code pour nettoyer une donnée simple (comme renommer des colonnes, gérer les valeurs manquantes ou formater des dates) est trop lourd. Pour ces tâches, AWS propose Glue DataBrew. C’est une interface visuelle (no-code) qui vous permet de nettoyer et de préparer vos données avec plus de 250 transformations prédéfinies.
DataBrew est une excellente porte d’entrée pour les analystes métiers qui n’ont pas un profil d’ingénieur. Il permet de prototyper des transformations rapidement. Cependant, chez DATAROCKSTARS, nous insistons sur le fait que la reproductibilité nécessite du code. Nous apprenons à nos étudiants à utiliser DataBrew pour l’exploration, mais à migrer vers des Glue Jobs versionnés en Git pour la mise en production réelle. La distinction entre exploration visuelle et industrialisation logicielle est fondamentale pour la pérennité de vos projets data.
6. Intégration avec AWS Lake Formation : Sécurité et Gouvernance
L’utilisation de Glue ne se fait jamais isolément. Il est profondément intégré à AWS Lake Formation. Si Glue est le moteur de transformation, Lake Formation est le gardien de la sécurité. Il permet de définir des accès ultra-précis : “l’utilisateur X ne peut voir que les colonnes ‘Prix’ et ‘ID Produit’ de la table ‘Ventes'”. Glue respecte ces politiques lors de l’exécution des jobs ou lors de la lecture des données.
C’est une brique indispensable pour la conformité (RGPD, etc.). Dans nos formations en cybersécurité, nous expliquons comment cette intégration permet de construire des Data Lakes sécurisés. Un Data Engineer qui ignore comment sécuriser ses données via Lake Formation est un risque majeur pour son entreprise. Chez DATAROCKSTARS, nous formons des professionnels responsables qui intègrent la sécurité dès la conception du pipeline.
7. Performance et optimisation des DPUs (Data Processing Units)
La performance des jobs Glue dépend de votre compréhension des DPUs. Un DPU représente une unité de ressources CPU, RAM et réseau. Si vous sous-estimez vos besoins, votre job sera lent ou échouera par manque de mémoire (OOM – Out of Memory). Si vous les surestimez, vous gaspillez votre budget. Trouver l’équilibre est un art.
Nous apprenons à nos étudiants à monitorer l’utilisation des DPUs via les CloudWatch Metrics. Est-ce que votre job sature la mémoire ? Est-ce qu’il est limité par le réseau ? L’optimisation des jobs Spark est un domaine passionnant. Savoir si vous devez utiliser des workers G.1X, G.2X ou G.4X est crucial pour vos coûts cloud. Ce niveau d’expertise, alliant technique et gestion financière (FinOps), est ce qui fait de nos diplômés des profils très recherchés par les entreprises.
8. Glue et le Data Lake : Une architecture de référence
Glue est l’épine dorsale de toute architecture Data Lake moderne sur AWS. Dans un schéma classique : les données sont ingérées dans S3 (via Kinesis, DMS, ou des API), Glue Crawlers les catalogue, Glue Jobs les nettoie et les transforme, et enfin elles sont stockées en format optimisé (Parquet ou Iceberg). C’est le flux standard.
Pour les ingénieurs DATAROCKSTARS, ce flux n’a aucun secret. Nous vous apprenons à structurer vos couches de données : “Bronze” (brute), “Silver” (nettoyée/normalisée) et “Gold” (agrégée/prête pour la BI). Maîtriser cette architecture est essentiel pour fournir des données de haute qualité aux Data Scientists. Vous ne vous contentez pas de déplacer des données, vous construisez la plateforme sur laquelle reposera toute l’intelligence de l’entreprise.
9. Glue et l’Intelligence Artificielle : Préparer la donnée pour l’IA
L’IA n’est performante que si ses données d’entraînement sont pertinentes. AWS Glue joue un rôle crucial ici : il prépare les datasets qui serviront à entraîner vos modèles, que ce soit pour le Machine Learning classique (SageMaker) ou pour l’IA générative (RAG). Par exemple, Glue peut extraire des textes de documents PDF, les nettoyer, les diviser en morceaux (chunks) et les charger dans une base de données vectorielle.
Cette étape de préparation pour l’IA est le domaine d’expertise de nos Bootcamps Data Scientist & AI. Le MLE (Machine Learning Engineer) doit être capable d’automatiser ces pipelines de préparation. Glue est l’outil parfait pour cela, car il permet de traiter des documents à grande échelle de manière distribuée. C’est l’un des use-cases les plus stimulants en 2026, et vous serez aux avant-postes pour construire ces systèmes.
10. Pourquoi choisir DATAROCKSTARS pour devenir expert Glue
La demande pour des ingénieurs capables de dompter AWS Glue, de sécuriser les pipelines et d’optimiser les coûts cloud est massive. Mais le marché manque de talents qui ont une vision globale, capables de connecter Glue avec Lake Formation, SageMaker et les architectures modernes de Data Mesh. C’est cette vision d’expert que nous transmettons chez DATAROCKSTARS.
Nos cursus ne se contentent pas de survoler les services AWS ; nous plongeons dans les problématiques réelles des entreprises. Vous construirez des projets, vous ferez face à des erreurs de configuration, vous apprendrez à optimiser des scripts Spark réels. C’est cet apprentissage par la pratique qui garantit votre employabilité et votre succès. Votre carrière mérite un socle technique solide. Rejoignez nos cursus pour acquérir cette maîtrise indispensable et propulser votre profil parmi les meilleurs. Souhaitez-vous découvrir comment notre Bootcamp Data Engineer & AIOps peut vous faire devenir l’expert cloud incontournable des entreprises innovantes ?
Merci pour votre lecture ! Si vous souhaitez découvrir nos prochains articles autour de la Data et de l’IA, vous pouvez nous suivre sur Facebook, LinkedIn et Twitter pour être notifié dès la publication d’un nouvel article !