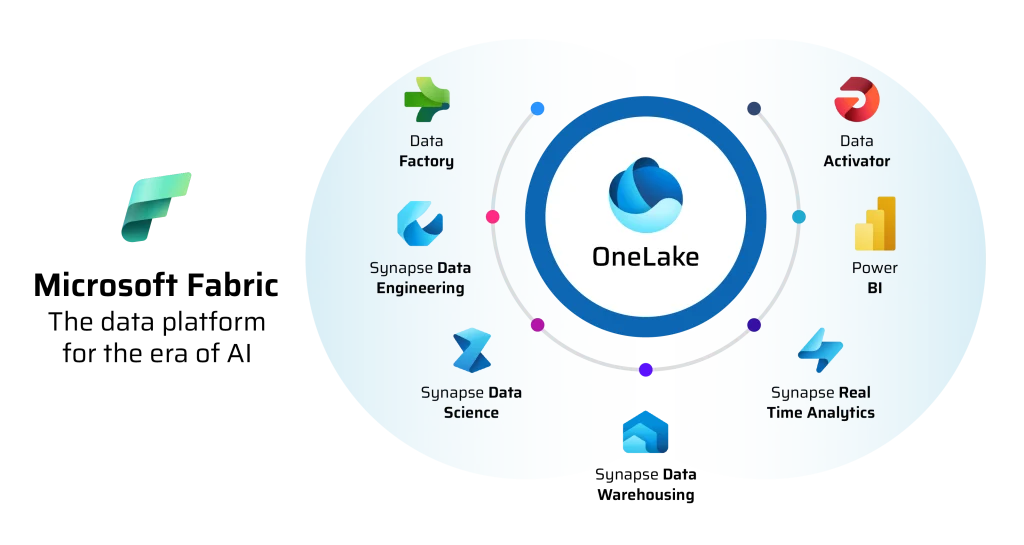
Dans un paysage technologique où les données sont souvent fragmentées entre plusieurs services et formats, Microsoft Fabric s’impose comme la réponse définitive à la complexité de l’analytique moderne. Lancée comme une plateforme SaaS (Software as a Service) unifiée, Fabric regroupe en une seule interface l’ingénierie de données, l’intégration de flux, la data science, l’analyse en temps réel et la business intelligence. Son innovation majeure réside dans OneLake, un “OneDrive pour les données” qui élimine les silos en permettant à tous les outils de travailler sur une copie unique de l’information, réduisant ainsi drastiquement les coûts de stockage et les délais de traitement.
Pour un Data Analyst, un ingénieur de données ou un décideur IT, Microsoft Fabric représente un changement de paradigme. Il ne s’agit plus de “coller” des services disparates (comme Azure Data Factory, Synapse et Power BI), mais d’évoluer dans un environnement intégré où la sécurité et la gouvernance sont natives. Comprendre Microsoft Fabric, c’est s’approprier une technologie qui démocratise l’accès à la donnée et place l’intelligence artificielle au cœur de chaque processus décisionnel, garantissant que votre système d’information reste agile et ultra-performant.
1. Définition et fondements techniques du concept
Pour vulgariser Microsoft Fabric, imaginez un smartphone géant pour vos données. Avant, vous aviez besoin d’un appareil pour téléphoner, d’un autre pour prendre des photos et d’un ordinateur pour vos mails. Fabric réunit toutes ces applications au sein d’un seul appareil avec une batterie partagée (la puissance de calcul) et une mémoire unique (OneLake). Si vous modifiez une photo, elle est à jour partout. C’est cette fluidité qui permet de passer du nettoyage des données à leur visualisation dans Power BI sans jamais changer d’onglet ou déplacer un fichier.
Techniquement, Fabric repose sur plusieurs piliers architecturaux :
- OneLake : Un lac de données logique unique, basé sur le format ouvert Delta Parquet, garantissant l’interopérabilité.
- Calcul multi-moteurs : Des moteurs optimisés pour SQL, Spark ou KQL (temps réel) qui puisent tous dans la même source de données.
- Direct Lake : Une technologie révolutionnaire qui permet à Power BI de lire des milliards de lignes directement dans OneLake sans avoir à importer les données, offrant une vitesse inédite.
L’architecture de Fabric est nativement intégrée au Cloud Azure. Les développeurs peuvent utiliser le langage Python dans des Notebooks Spark pour transformer les données, tout en orchestrant les flux via des pipelines familiers. Pour assurer la portabilité et la cohérence, Microsoft utilise des technologies de conteneurisation proches de Docker en arrière-plan pour isoler les charges de travail. Cette structure simplifie la maintenance applicative et permet d’exécuter des modèles de Data Science massifs directement là où les données résident, maximisant ainsi l’efficacité du Cloud Computing.
2. À quoi sert ce domaine dans le monde professionnel ?
Microsoft Fabric est le moteur de l’agilité analytique à l’échelle de l’entreprise. Dans le secteur du Retail, il permet une vision client à 360°. Exemple concret : Une enseigne de grande distribution centralise ses tickets de caisse, ses stocks et ses données de fidélité dans OneLake. Grâce à l’intégration native, le service marketing peut lancer une analyse de segmentation via des briques de Machine Learning et visualiser immédiatement l’impact sur un dashboard Power BI, sans attendre que l’IT réalise des transferts de données complexes.
Dans le domaine de la Finance, il sécurise et accélère le reporting réglementaire. Cas d’usage technologique : Une banque utilise Fabric pour ingérer des millions de transactions en temps réel. Le moteur “Real-Time Analytics” détecte les anomalies via des algorithmes de détection de fraude, tandis que le “Data Warehouse” prépare les rapports financiers consolidés. Cette centralisation est un aspect vital pour tout savoir sur la cybersécurité et la conformité, car toutes les données sont régies par une politique de gouvernance unique (Microsoft Purview).
Pour l’Industrie, il optimise la maintenance prédictive. Exemple en entreprise : Une usine connecte ses capteurs IoT à Fabric. Les données sont traitées par le moteur Spark pour identifier des signaux faibles de panne via du NLP appliqué aux logs techniques. L’alerte est ensuite envoyée directement sur les tablettes des techniciens. En utilisant les capacités de Data Science de la plateforme, l’entreprise réduit ses arrêts de production et améliore la résilience de son système d’information.
3. Classement des 10 composants essentiels de Fabric
- OneLake : Le socle de stockage unique et partagé pour toute l’organisation.
- Data Factory : L’outil d’intégration pour connecter des centaines de sources de données (APIs, SQL, Cloud).
- Data Engineering : Environnement basé sur Spark pour la transformation de données à grande échelle.
- Data Warehouse : Un entrepôt de données SQL performant avec une séparation complète du stockage et du calcul.
- Data Science : Des outils intégrés pour bâtir, entraîner et déployer des modèles d’IA.
- Real-Time Analytics : Moteur optimisé pour l’analyse de flux de données massifs en temps réel (logs, télémétrie).
- Power BI : La référence mondiale de la dataviz, intégrée nativement pour une lecture sans latence.
- Copilot pour Fabric : L’assistant d’IA générative qui aide à écrire du code SQL, Python ou des mesures DAX.
- Data Activator : Un outil “no-code” pour déclencher des actions automatiques basées sur des seuils de données.
- Microsoft Purview : La couche de gouvernance et de protection des données transversale à tous les services.
4. Guide de choix selon votre projet professionnel
Microsoft Fabric s’adapte à différents profils techniques en offrant des expériences sur mesure (Persona-based experiences).
| Profil | Expérience privilégiée | Outils à privilégier | Objectif métier |
| Data Engineer | Data Engineering / Factory | Spark, Python, Pipelines | Construire des pipelines de données robustes |
| Data Analyst | Power BI / Data Warehouse | SQL, DAX, Direct Lake | Créer des rapports temps réel ultra-rapides |
| Data Scientist | Data Science | Notebooks, MLflow, Synapse | Déployer des modèles prédictifs métiers data qui recrutent |
| Business User | Power BI / Data Activator | Copilot, Dashboards | Prendre des décisions basées sur la donnée |
Pour ceux qui souhaitent devenir des experts de cette plateforme, les bootcamps en data engineering et analytics sont essentiels. Maîtriser Microsoft Fabric demande une compréhension de l’ensemble de la chaîne de valeur de la donnée. Obtenir une certification sur Fabric est aujourd’hui un atout majeur car les entreprises cherchent massivement à migrer leurs anciens systèmes fragmentés vers cette solution unifiée pour réduire leur dette technique.
5. L’impact de l’intelligence artificielle (Copilot) sur Fabric
L’IA n’est pas une option dans Fabric, elle en est le cœur. Cas technologique : Avec l’intégration de “Copilot”, l’intelligence artificielle générative assiste l’utilisateur à chaque étape. Un ingénieur peut demander : “Crée-moi un pipeline pour ingérer les ventes de mon API et nettoie les valeurs nulles”, et Copilot génère le code Python et les briques de transformation. Cela permet de se concentrer sur la stratégie plutôt que sur la syntaxe.
En entreprise, l’IA facilite la découverte de données (“Data Discovery”). Exemple en entreprise : Un utilisateur peut interroger OneLake en langage naturel : “Montre-moi les produits dont la marge a baissé de plus de 10 % ce mois-ci”. L’IA analyse les pétaoctets de données dans OneLake et génère instantanément la visualisation adéquate. Cette démocratisation de la Data Science permet à chaque collaborateur de devenir autonome dans ses analyses.
Enfin, l’IA optimise les performances de la plateforme. Des algorithmes de machine learning surveillent les requêtes SQL et Spark pour ajuster automatiquement les ressources de calcul nécessaires. Pour maîtriser ces nouveaux outils, il est crucial de comprendre comment l’IA s’interface avec les moteurs de Fabric pour transformer un simple lac de données en un système intelligent capable d’auto-optimisation.
6. Comprendre les paradigmes et concepts avancés
Un concept fondamental dans Fabric est le “Shortcutting”. Il s’agit de la capacité de OneLake à pointer vers des données stockées dans AWS S3 ou Google Cloud Storage sans les copier physiquement. Cela permet de créer un lac de données virtuel mondial, où l’utilisateur accède à toutes les informations de l’entreprise comme si elles étaient locales, tout en respectant les politiques de cybersécurité et de localisation des données.
Un autre paradigme avancé est le format Delta Lake. Fabric utilise par défaut ce format de stockage ouvert qui apporte les transactions ACID (fiabilité) aux lacs de données. Cela signifie que même si une mise à jour de données échoue au milieu d’un processus Spark, votre base de données reste cohérente. Ce niveau de robustesse est indispensable pour les applications de système d’information critiques où l’erreur n’est pas permise.
L’utilisation de Git Integration permet également aux développeurs de gérer leurs workflows Fabric comme du code logiciel. On peut versionner ses rapports Power BI, ses notebooks et ses pipelines, facilitant ainsi le travail collaboratif et les déploiements continus (CI/CD). Cette approche “DataOps” est un aspect vital pour tout savoir sur l’ingénierie moderne : la donnée est traitée avec la même rigueur qu’une application logicielle.
7. L’évolution historique : de SQL Server à Microsoft Fabric
Le parcours de Microsoft dans la donnée est une quête permanente d’unification :
- Années 2000 : Domination de SQL Server pour les données structurées locales.
- 2010-2015 : Émergence d’Azure SQL et des premiers services Cloud.
- 2019 : Lancement d’Azure Synapse Analytics pour tenter de fusionner le Big Data et le Data Warehouse.
- 2023 : Lancement officiel de Microsoft Fabric. C’est la rupture technologique : on abandonne la gestion par serveurs pour une expérience SaaS totalement unifiée.
- Aujourd’hui : Fabric devient le standard pour les entreprises souhaitant bâtir une “AI-Ready” data culture, intégrant nativement Copilot et OneLake.
8. Idées reçues, limites et défis techniques
L’idée reçue la plus courante est que “Fabric va remplacer tous les autres outils Azure”. C’est faux : Azure Databricks ou Azure SQL restent pertinents pour des besoins de personnalisation extrême. Fabric est une plateforme d’unification, pas une prison technologique. Le défi est de savoir quand rester sur une approche “Best-of-breed” (meilleurs outils séparés) et quand passer à l’approche intégrée de Fabric pour gagner en vitesse.
Une limite technique majeure est la maturité de certains connecteurs. Bien que Fabric soit puissant, la migration de systèmes “Legacy” (vieux serveurs locaux) vers le Cloud demande une planification minutieuse. Exemple en entreprise : Une société peut rencontrer des difficultés pour synchroniser ses données SQL locales avec OneLake si sa bande passante est limitée. Le défi est donc de mettre en place une stratégie hybride intelligente.
Enfin, la maîtrise des coûts est un défi. Puisque Fabric partage une capacité de calcul unique (“Capacity”) pour tous les services, une mauvaise requête Spark lancée par un Data Scientist peut ralentir les rapports Power BI de la direction. Une veille technologique et une gouvernance stricte des ressources sont indispensables pour s’assurer que l’agilité offerte par Fabric ne se transforme pas en surcoûts imprévus pour le système d’information.
9. Conclusion et perspectives d’avenir
Microsoft Fabric en 2026 est bien plus qu’une plateforme analytique ; c’est le système nerveux de l’entreprise intelligente. En supprimant les barrières entre les outils et les formats, il permet enfin de réaliser la promesse d’une entreprise véritablement “data-driven”. C’est l’outil de ceux qui veulent transformer leur patrimoine de données en un avantage concurrentiel immédiat grâce à la puissance de l’IA.
L’avenir se dessine vers une intégration encore plus poussée avec le “Digital Twin” et l’IoT, où Fabric analysera en continu les flux du monde physique pour suggérer des actions proactives via l’IA. Nous nous dirigeons vers une informatique “zéro latence” entre l’événement et l’insight. Maîtriser Microsoft Fabric aujourd’hui, c’est s’assurer de piloter les révolutions technologiques qui définiront l’économie de la donnée dans les décennies à venir.
Aspirez-vous à maîtriser les rouages du Big Data et à concevoir des architectures de données massives ? Notre formation Data Engineer & Ops vous apprend à explorer l’écosystème distribué et le traitement de flux à grande échelle, afin de propulser votre expertise vers les frontières de l’ingénierie des données.
Merci pour votre lecture ! Si vous souhaitez découvrir nos prochains articles autour de la Data et de l’IA, vous pouvez nous suivre sur Facebook, LinkedIn et Twitter pour être notifié dès la publication d’un nouvel article !