Dans l’histoire de la vision par ordinateur et de l’intelligence artificielle, l’architecture VGG (Visual Geometry Group) marque un tournant majeur. Présentée par des chercheurs de l’Université d’Oxford en 2014, elle a démontré que la clé de la performance pour la reconnaissance d’images résidait dans la profondeur du réseau et l’utilisation de petits filtres convolutifs. Bien que nous soyons en 2026, VGG reste un modèle de référence, particulièrement utilisé pour le transfert d’apprentissage et l’extraction de caractéristiques.
Chez DATAROCKSTARS, nous enseignons que comprendre VGG est essentiel pour maîtriser les réseaux de neurones convolutifs (CNN). C’est un modèle qui illustre parfaitement comment une architecture rigoureuse et uniforme peut surpasser des systèmes plus complexes et désordonnés. Pour devenir une Rockstar du Deep Learning, il faut saisir l’élégance derrière la répétition des blocs de VGG.
1. L’origine de VGG : Le défi ImageNet
Le modèle VGG a été conçu pour participer au défi ILSVRC 2014 (ImageNet Large Scale Visual Recognition Challenge). L’équipe d’Oxford a voulu explorer l’impact de la profondeur sur la précision du réseau. À l’époque, les modèles comme AlexNet utilisaient des filtres de grande taille, mais VGG a pris le contre-pied en utilisant exclusivement des filtres très petits mais disposés en couches très profondes.
Le résultat a été sans appel : VGG a atteint la deuxième place du concours avec un taux d’erreur top-5 de 7,3 %, prouvant que “plus profond est souvent mieux”. Chez DATAROCKSTARS, nous utilisons ce cas d’école pour montrer comment l’expérimentation sur les hyperparamètres peut mener à des percées technologiques.
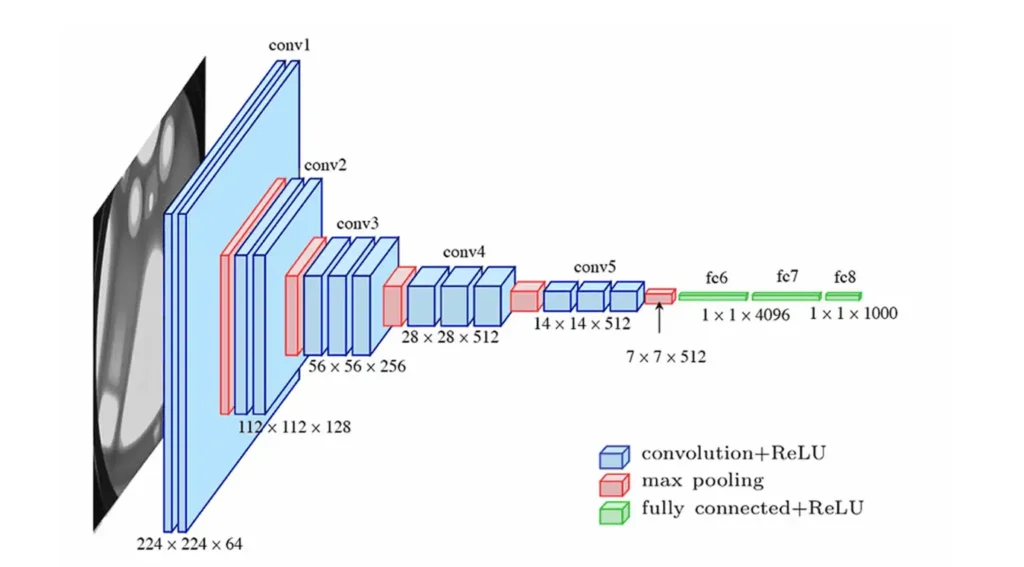
2. L’architecture uniforme : La règle des filtres 3×3
La caractéristique la plus emblématique de VGG est l’utilisation systématique de filtres de convolution de taille $3 \times 3$. Contrairement à ses prédécesseurs qui utilisaient des filtres $11 \times 11$ ou $7 \times 7$, VGG empile plusieurs couches $3 \times 3$ les unes derrière les autres.
Pourquoi ce choix ?
• Champ récepteur : Deux couches $3 \times 3$ successives ont le même “champ de vision” qu’une seule couche $5 \times 5$, mais avec moins de paramètres.
• Non-linéarité : En empilant plusieurs couches, on ajoute des fonctions d’activation (ReLU) supplémentaires, ce qui permet au réseau d’apprendre des fonctions plus complexes.
• Réduction de paramètres : Cela permet de réduire la charge de calcul tout en augmentant la capacité d’apprentissage.
3. VGG-16 vs VGG-19 : Les variantes classiques
Il existe plusieurs versions de VGG, mais les deux plus célèbres sont VGG-16 (16 couches de poids) et VGG-19 (19 couches de poids). Elles suivent toutes la même logique de structure :
Blocs de convolution : Des séries de couches de convolution suivies d’une fonction d’activation ReLU.
Max Pooling : Des couches de réduction spatiale ($2 \times 2$ avec un pas de 2) pour réduire la dimension de l’image.
Couches denses (Fully Connected) : En fin de réseau, trois couches denses terminent le processus pour la classification (souvent vers 1000 classes pour ImageNet).
Dans notre Bootcamp Data Scientist & AI Engineer, nous apprenons à manipuler ces couches pour comprendre comment l’information visuelle est compressée et transformée en prédiction.
4. L’importance du Max Pooling et du doublement des filtres
L’architecture VGG suit une progression logique très élégante. À chaque fois qu’une couche de Max Pooling divise la résolution de l’image par deux, le nombre de filtres (la profondeur du volume de données) est doublé.
On commence généralement avec 64 filtres, puis 128, 256, et enfin 512 dans les couches les plus profondes. Cette stratégie permet de compenser la perte d’information spatiale par une augmentation de la richesse des caractéristiques extraites. C’est un concept fondamental du Data Engineering appliqué au Deep Learning que nous approfondissons dans nos cursus.
5. Le transfert d’apprentissage (Transfer Learning) avec VGG
L’une des utilisations les plus courantes de VGG aujourd’hui n’est pas d’entraîner le modèle de zéro, mais d’utiliser le Transfer Learning. Puisque VGG a déjà appris à reconnaître des millions de formes (bords, textures, objets) sur ImageNet, nous pouvons récupérer ces connaissances.
• Extraction de caractéristiques : On utilise le corps de VGG pour transformer une image en un vecteur de données riche, puis on entraîne seulement une petite couche finale pour notre besoin spécifique (ex: détecter des maladies sur des feuilles de plantes).
• Fine-tuning : On ajuste légèrement les poids des dernières couches de VGG pour les adapter à un nouveau domaine.
Chez DATAROCKSTARS, nous montrons comment cette technique permet d’obtenir des résultats d’élite même avec très peu de données.
6. Les limites de VGG : Mémoire et Paramètres
Malgré son efficacité, VGG possède deux inconvénients majeurs qui ont mené à l’apparition de modèles comme ResNet ou Inception :
• Le poids du modèle : VGG est extrêmement lourd. VGG-16 pèse environ 528 Mo et possède plus de 138 millions de paramètres. La majorité de ces paramètres se trouve dans les couches denses finales.
• La lenteur : En raison de sa profondeur et du nombre de filtres, l’inférence (le temps de prédiction) est plus lente que sur des architectures plus modernes et optimisées.
Savoir choisir entre la simplicité de VGG et l’efficacité d’un modèle plus récent est une compétence d’architecte IA que nous développons chez DATAROCKSTARS.
7. Pré-traitement des données pour VGG
Pour utiliser VGG correctement, les données doivent être préparées selon un standard précis :
• Taille d’entrée : Les images doivent être redimensionnées en $224 \times 224$ pixels.
• Normalisation : On soustrait la valeur moyenne des pixels RVB calculée sur l’ensemble du jeu d’entraînement ImageNet.
Ignorer ces étapes de pré-traitement rendrait le modèle totalement inefficace. Dans nos bootcamps, nous insistons sur ces détails techniques car ils constituent 80 % du succès d’un projet d’IA.
8. VGG dans le domaine de la Création (Style Transfer)
VGG-19 est particulièrement célèbre pour avoir permis l’éclosion du Neural Style Transfer. En utilisant les représentations internes des couches de VGG, on peut séparer le “contenu” d’une photo de son “style” artistique (comme un tableau de Van Gogh) pour les fusionner.
[Image showing Neural Style Transfer results using VGG-19 with content and style images]
Cette application démontre que les couches de VGG ne voient pas seulement des pixels, mais capturent l’essence visuelle d’une image. Chez DATAROCKSTARS, nous explorons ces aspects créatifs pour montrer l’étendue des possibilités offertes par le Deep Learning.
9. Implémentation de VGG avec Keras et PyTorch
En 2026, l’utilisation de VGG est simplifiée par les frameworks modernes. En une seule ligne de code, vous pouvez importer le modèle avec ses poids pré-entraînés.
Python
from tensorflow.keras.applications import VGG16
model = VGG16(weights='imagenet', include_top=True)
Savoir manipuler ces bibliothèques est le quotidien de nos étudiants. Nous vous apprenons à modifier ces architectures, par exemple en supprimant la “tête” (les couches denses) pour connecter VGG à vos propres réseaux neuronaux.
10. Pourquoi maîtriser VGG avec DATAROCKSTARS
VGG est le socle de la vision par ordinateur moderne. Comprendre comment ses couches de convolution et de pooling collaborent pour “voir” est une étape indispensable pour quiconque souhaite faire carrière dans l’IA. C’est un modèle qui pardonne peu les erreurs de structure mais qui offre une puissance d’analyse exceptionnelle.
Chez DATAROCKSTARS, nous vous donnons les bases théoriques et la pratique intensive pour dompter ces réseaux de neurones profonds. Prêt à voir le monde à travers les yeux de l’IA ? Souhaitez-vous découvrir comment notre Bootcamp Data Scientist & AI Engineer peut vous aider à maîtriser VGG et à propulser vos projets de Computer Vision au sommet ?
Merci pour votre lecture ! Si vous souhaitez découvrir nos prochains articles autour de la Data et de l’IA, vous pouvez nous suivre sur Facebook, LinkedIn et Twitter pour être notifié dès la publication d’un nouvel article !