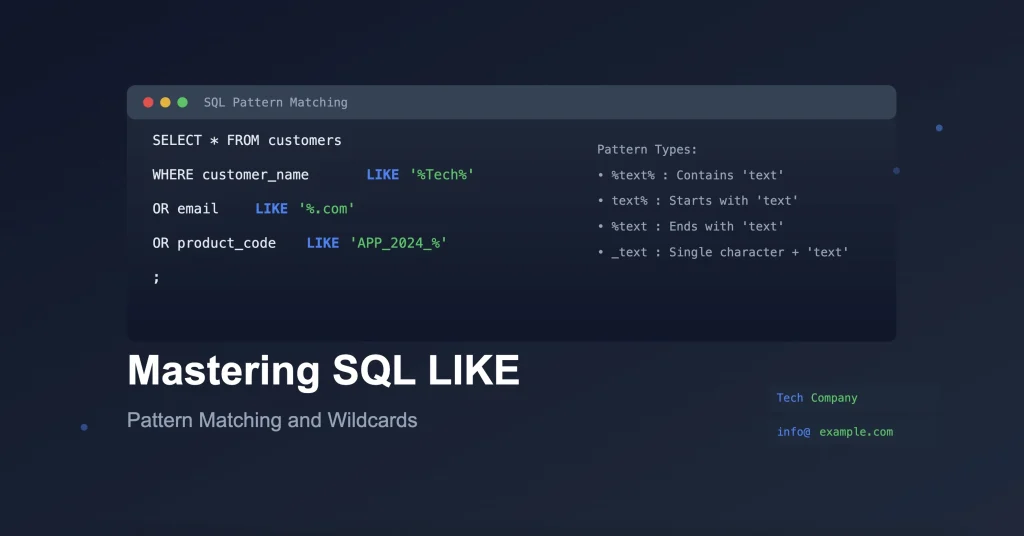
Dans l’immensité du système d’information en 2026, la recherche exacte ne suffit plus. L’opérateur sql like est l’outil fondamental qui permet d’effectuer des recherches par “pattern matching” (correspondance de motifs) dans des colonnes de texte. Contrairement à l’opérateur d’égalité stricte, LIKE utilise des caractères génériques pour filtrer les résultats selon des modèles partiels. Qu’il s’agisse de retrouver un client dont on ne connaît que le début du nom, de filtrer des logs de cybersécurité ou de segmenter des catégories de produits dans un datawarehouse, LIKE offre une flexibilité indispensable pour explorer le patrimoine informationnel. C’est le pont entre la donnée brute et l’information utile au sein du Cloud Computing.
Pour les talents formés chez DATAROCKSTARS, maîtriser la recherche textuelle est une compétence de base pour tout analyste. Que vous soyez futur Data Scientist ou Analyste, savoir manipuler le langage SQL pour extraire des motifs spécifiques est une compétence clé des métiers data qui recrutent. Ce dossier approfondi explore les 10 dimensions de l’opérateur SQL LIKE.
1. Le caractère générique % (Pourcentage)
Le symbole % est le joker le plus utilisé en SQL. Il représente n’importe quelle séquence de caractères, y compris une séquence vide. Placé à la fin d’une chaîne ('Data%'), il permet de trouver tous les mots commençant par “Data”. Placé au début ('%stars'), il trouve ceux qui se terminent par “stars”. Utilisé de part et d’autre ('%rock%'), il identifie n’importe quelle occurrence du motif au sein du texte. Cette puissance de filtrage est un aspect vital pour tout savoir sur l’exploration de bases de données massives sur le Cloud Computing, permettant de naviguer dans le patrimoine informationnel avec une agilité totale.
2. Le caractère générique _ (Souligné)
Moins connu mais tout aussi précis, le symbole _ représente exactement un seul caractère. Il est idéal pour les recherches où la structure du texte est fixe mais dont une valeur varie. Par exemple, 'P_thon' trouverait “Python” ou “Pithon”. En 2026, cet opérateur est massivement utilisé dans le Data Management pour filtrer des codes produits, des numéros de série ou des identifiants normalisés au sein du système d’information. Sa précision chirurgicale permet d’éviter les faux positifs que le joker % pourrait engendrer lors d’analyses de Data Science rigoureuses.
3. La sensibilité à la casse (Case Sensitivity)
Le comportement de LIKE concernant les majuscules et minuscules dépend fortement du système de gestion de base de données (SGBD) utilisé (PostgreSQL, MySQL, SQL Server) et de sa configuration de “collation”. Dans certains environnements, 'PRODUIT' ne correspondra pas à 'produit'. Pour pallier ce problème, les experts utilisent souvent des fonctions de transformation comme UPPER() ou LOWER(), ou l’opérateur spécifique ILIKE sur PostgreSQL. Comprendre cette nuance est une étape de maintenance applicative cruciale pour garantir que vos requêtes de cybersécurité ne ratent aucun événement suspect à cause d’une simple différence de casse.
4. L’utilisation de la clause NOT LIKE
Parfois, la valeur d’une analyse réside dans ce qui ne correspond pas au motif. L’opérateur NOT LIKE permet d’exclure tous les enregistrements qui suivent un modèle spécifique. C’est un outil de nettoyage de données surpuissant dans le patrimoine informationnel. Par exemple, pour isoler les emails qui n’appartiennent pas à un domaine spécifique ou pour écarter des logs de routine dans un système d’information, NOT LIKE affine les résultats pour ne laisser que la donnée pertinente. Chez DATAROCKSTARS, nous apprenons à nos étudiants à utiliser l’exclusion pour réduire le bruit dans leurs pipelines de Data Science.
5. Le caractère d’échappement (ESCAPE)
Comment faire si vous devez rechercher précisément le caractère % ou _ dans votre texte ? SQL propose la clause ESCAPE. En définissant un caractère spécial (souvent le backslash \), vous indiquez au moteur SQL que le symbole suivant doit être traité comme un texte littéral et non comme un joker. Cette technicité est indispensable pour la maintenance applicative des bases de données techniques contenant des formules mathématiques ou des chemins de fichiers sur le Cloud Computing. Maîtriser l’échappement prouve une compréhension profonde de la grammaire du langage SQL et sécurise le traitement du patrimoine informationnel.
6. Performance et Indexation : Le piège du % en début
L’utilisation de LIKE peut avoir un impact lourd sur les performances. Si vous commencez votre motif par un joker ('%motif'), la base de données ne peut pas utiliser les index standards (B-Tree) et doit scanner l’intégralité de la table (full table scan). Sur des milliards de lignes dans le Cloud Computing, cela peut paralyser le système d’information. Pour optimiser ces requêtes, les Data Engineers formés chez DATAROCKSTARS privilégient les recherches commençant par du texte fixe ou utilisent des index de type “Trigram” pour accélérer les recherches floues au sein du patrimoine informationnel.
7. LIKE vs REGEXP (Expressions Régulières)
Bien que LIKE soit simple et efficace, il est limité pour les motifs très complexes. Pour des recherches impliquant des alternatives (OU), des répétitions ou des classes de caractères, on préférera les expressions régulières (REGEXP ou SIMILAR TO). Cependant, LIKE reste privilégié pour 90% des besoins quotidiens en Data Management en raison de sa syntaxe intuitive et de sa compatibilité universelle entre les différents SGBD. Savoir quand s’arrêter avec LIKE pour passer aux expressions régulières est une marque de maturité technique indispensable pour tout spécialiste de l’intelligence artificielle.
8. Combinaison avec les opérateurs logiques AND et OR
L’opérateur LIKE gagne en puissance lorsqu’il est combiné avec AND ou OR. Vous pouvez ainsi rechercher des motifs multiples au sein d’une même requête : WHERE nom LIKE 'A%' AND prenom LIKE '%e'. Cette granularité est essentielle pour segmenter finement le patrimoine informationnel des entreprises. En 2026, cette technique est à la base de nombreux filtres dans les interfaces d’intelligence artificielle et les Agents IA & Automations, permettant de raffiner les résultats de recherche de manière itérative au sein du système d’information.
9. LIKE et les jointures de tables
Une pratique avancée consiste à utiliser LIKE au sein d’une condition de jointure (JOIN). Bien que rare et coûteux en ressources sur le Cloud Computing, cela permet de lier des tables qui ne partagent pas de clés primaires identiques mais des motifs textuels communs (ex: lier un log d’erreur à une table de documentation via un code partiel). Cette approche de “Fuzzy Joining” est un aspect vital pour tout savoir sur l’intégration de données hétérogènes. Elle permet de réconcilier des morceaux du patrimoine informationnel issus de sources différentes sans nécessiter de fastidieux nettoyages préalables.
10. L’avenir : De LIKE à la recherche vectorielle
En 2026, si LIKE reste le standard pour les correspondances de caractères, il est complété par la recherche vectorielle (Vector Search) propulsée par l’intelligence artificielle. Là où LIKE cherche des lettres, les vecteurs cherchent du sens. Cependant, pour la validation de données brutes, le filtrage technique et la maintenance des bases SQL, LIKE demeure l’outil de référence absolu. Sa simplicité en fait le premier garde-fou de la qualité des données. Comprendre comment LIKE structure encore aujourd’hui l’accès au patrimoine informationnel est le prérequis pour appréhender les technologies de recherche sémantique de demain.
Conclusion : Pourquoi maîtriser SQL LIKE avec DATAROCKSTARS ? L’opérateur SQL LIKE est le scalpel de l’analyste de données. En 2026, savoir naviguer dans les chaînes de caractères avec précision est ce qui permet de transformer un bruit textuel en une information stratégique exploitable. Maîtriser LIKE, c’est s’assurer que vous pouvez retrouver n’importe quelle aiguille dans la botte de foin numérique de votre entreprise, garantissant ainsi la réactivité de votre système d’information.
Chez DATAROCKSTARS, nous vous formons à cette rigueur analytique. En rejoignant nos cursus, vous apprenez à manipuler les bases de données les plus complexes, à optimiser vos requêtes pour le Cloud Computing et à sécuriser vos recherches au sein du patrimoine informationnel. Ne vous contentez pas de regarder les données : apprenez à les filtrer avec intelligence pour devenir un leader de la révolution technologique.
Aspirez-vous à maîtriser les rouages des modèles de langage et à concevoir des solutions d’IA ultra-performantes ? Notre formation Data Analyst & AI vous apprend à exploiter l’écosystème Python et le traitement intelligent des flux sémantiques, afin de propulser votre expertise vers les frontières de l’innovation moderne.
Merci pour votre lecture ! Si vous souhaitez découvrir nos prochains articles autour de la Data et de l’IA, vous pouvez nous suivre sur Facebook, LinkedIn et Twitter pour être notifié dès la publication d’un nouvel article !