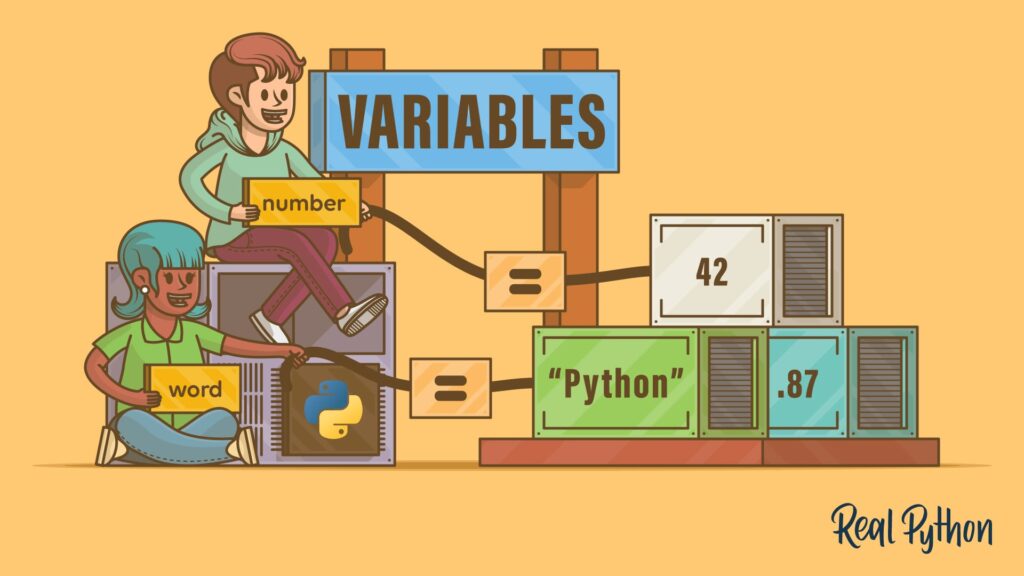
Dans l’écosystème du langage Python, une variable est un identifiant associé à une valeur stockée dans la mémoire de l’ordinateur. Contrairement à d’autres langages plus rigides, Python utilise un typage dynamique, ce qui signifie que vous n’avez pas besoin de déclarer explicitement le type de donnée (entier, texte, liste) lors de la création de la variable. Dans un système d’information moderne, la variable est l’unité élémentaire qui permet de capturer, transformer et acheminer le patrimoine informationnel vers des modèles de Data Science ou des services de Cloud Computing.
Pour les talents formés chez DATAROCKSTARS, la maîtrise des variables est la première étape vers l’automatisation. Que vous soyez futur Data Engineer ou développeur d’intelligence artificielle, comprendre comment Python gère ces objets est une compétence clé des métiers data qui recrutent.
1. Déclaration et affectation dynamique
En Python, l’affectation se fait simplement avec l’opérateur =. Vous pouvez changer le contenu et le type d’une variable à tout moment. Cette souplesse permet au système d’information d’être extrêmement agile lors du traitement de flux de données hétérogènes. C’est l’aspect vital pour tout savoir sur la rapidité de prototypage : une variable peut contenir un chiffre, puis devenir une chaîne de caractères sans erreur de compilation.
2. Les types de données scalaires essentiels
Python propose plusieurs types de base pour structurer votre patrimoine informationnel :
- int : Pour les nombres entiers (ex:
age = 25). - float : Pour les nombres décimaux (ex:
prix = 19.99). - str : Pour les chaînes de caractères (ex:
nom = "Gemini"). - bool : Pour les valeurs logiques (True/False).
Ces types permettent de définir précisément la nature des données manipulées au sein du système d’information sur le Cloud Computing.
3. Nommage et bonnes pratiques (Snake Case)
Le nom d’une variable doit être explicite pour garantir la maintenance applicative. La convention en Python est le snake_case (ex: chiffre_affaires_annuel). Un nommage clair transforme votre code en une documentation vivante de votre patrimoine informationnel technique, facilitant la collaboration entre les équipes de Data Science et les Ops.
4. Mutabilité et immuabilité des objets
Certains types de variables sont immuables (comme les chaînes de caractères ou les tuples), tandis que d’autres sont mutables (comme les listes). Comprendre cette distinction est crucial pour le Data Management, car cela influence la manière dont les données sont copiées et modifiées en mémoire au sein du système d’information.
5. Portée des variables (Scope) : Global vs Local
Une variable définie à l’intérieur d’une fonction est locale et n’existe pas en dehors. Une variable définie à la racine du script est globale. Cette hiérarchie protège votre patrimoine informationnel contre les modifications accidentelles et structure la logique de vos Agents IA & Automations sur le Cloud Computing.
6. Structures de données complexes : Listes et Dictionnaires
Python excelle dans la gestion de collections. Une variable peut contenir une liste d’éléments ou un dictionnaire (clés/valeurs). Ces structures sont le pivot indispensable pour organiser le patrimoine informationnel massif utilisé en Data Science, permettant de regrouper des milliers d’observations dans une seule entité logique au sein du système d’information.
7. Gestion de la mémoire et ramasse-miettes (Garbage Collector)
Python gère automatiquement la mémoire. Lorsqu’une variable n’est plus référencée, son espace est libéré. Cette gestion transparente est un atout majeur pour le Cloud Computing, car elle évite les fuites de mémoire lors du traitement de gros volumes de données au sein du patrimoine informationnel de l’entreprise.
8. Formatage des variables (f-strings)
L’affichage et la manipulation des variables textuelles sont simplifiés par les f-strings (ex: f"Bonjour {utilisateur}"). Cette fonctionnalité permet au système d’information de générer des rapports dynamiques et des messages personnalisés, valorisant le patrimoine informationnel destiné aux utilisateurs finaux.
9. Variables et bibliothèques de Data Science (NumPy, Pandas)
Dans le domaine de la Data Science, les variables prennent souvent la forme de DataFrames ou de matrices. Ces objets spécialisés permettent de manipuler des millions de lignes de données avec une efficacité redoutable sur le Cloud Computing, transformant le patrimoine informationnel brut en insights stratégiques pour le système d’information.
10. L’avenir : Typing hints et robustesse du code
Bien que Python soit dynamique, l’usage des type hints (annotations de type) se généralise en 2026. Cela permet de rendre le code plus robuste et facilite le travail des Agents IA & Automations lors de la génération automatique de code. C’est le sommet de la qualité logicielle pour un patrimoine informationnel technique sécurisé et pérenne.
La maîtrise des variables est l’alphabet de la programmation moderne. Posséder cette compétence technique permet de structurer vos algorithmes, de sécuriser vos flux de données et de valoriser le patrimoine informationnel de votre organisation. C’est la compétence pivot qui transforme une idée en une solution logicielle performante.
Chez DATAROCKSTARS, nous vous formons à l’art du code propre et efficace. En rejoignant nos cursus, vous apprenez à manipuler les données avec élégance, à automatiser vos tâches et à bâtir des solutions d’intelligence artificielle fondées sur un socle technique irréprochable.
Souhaitez-vous découvrir comment notre formation Data Scientist & AI Engineer peut vous aider à maîtriser Python pour propulser vos projets ?
Merci pour votre lecture ! Si vous souhaitez découvrir nos prochains articles autour de la Data et de l’IA, vous pouvez nous suivre sur Facebook, LinkedIn et Twitter pour être notifié dès la publication d’un nouvel article !