Dans l’analyse de données en 2026, la moyenne seule est une information incomplète, voire trompeuse. Pour comprendre la réalité d’un phénomène, il faut savoir calculer ecart type (standard deviation). Cette statistique mesure la dispersion des données autour de leur moyenne : un écart-type faible indique que les données sont regroupées, tandis qu’un écart-type élevé révèle une forte volatilité. Que vous analysiez les performances de serveurs sur le Cloud Computing, la fiabilité d’un algorithme d’intelligence artificielle ou les risques financiers dans un système d’information, l’écart-type est l’indicateur de stabilité par excellence. C’est l’outil qui permet de quantifier l’incertitude au sein du patrimoine informationnel de l’entreprise.
Pour les talents formés chez DATAROCKSTARS, la maîtrise de la dispersion est le fondement de la statistique décisionnelle. Que vous soyez futur Data Scientist ou Analyste, savoir interpréter cet indicateur est une compétence clé des métiers data qui recrutent. Ce dossier approfondi explore les 10 dimensions du calcul de l’écart-type.
1. La définition mathématique et l’intuition
L’écart-type, souvent noté par la lettre grecque sigma ($\sigma$), est défini comme la racine carrée de la variance. Mathématiquement, il représente la “moyenne des écarts à la moyenne”. En 2026, l’intuition reste la même : il s’agit de savoir si vos points de données “obéissent” à la moyenne ou s’ils s’en échappent de manière erratique. Cette compréhension est un aspect vital pour tout savoir sur la distribution des données. Sans cette notion, un expert en Data Science ne pourrait pas distinguer un processus stable d’un système au bord de la rupture au sein du patrimoine informationnel.
2. Le calcul de la Variance : L’étape intermédiaire
Avant d’obtenir l’écart-type, il faut calculer la variance. On soustrait la moyenne à chaque donnée, on élève le résultat au carré (pour éviter les valeurs négatives), puis on fait la moyenne de ces carrés. Cette étape permet d’amplifier les écarts importants, ce qui est crucial en cybersécurité pour détecter des anomalies de comportement qui s’éloignent radicalement de la norme. La variance donne une mesure de dispersion, mais son unité est au carré, ce qui rend son interprétation moins intuitive que celle de l’écart-type pour le système d’information décisionnel.
3. La racine carrée : Revenir à l’unité d’origine
L’intérêt majeur de l’écart-type réside dans le fait qu’il s’exprime dans la même unité que les données d’origine (euros, secondes, octets). En prenant la racine carrée de la variance, on “redescend” à une échelle comparable à la moyenne. Cette propriété facilite grandement la communication des résultats de Data Management aux décideurs, leur permettant de visualiser concrètement la marge d’erreur ou la variabilité des processus sur le Cloud Computing.
4. Écart-type de population vs échantillon (Bessel’s correction)
Une subtilité mathématique capitale existe : si vous calculez l’écart-type d’un échantillon (une partie des données) pour estimer celui d’une population totale, vous devez diviser par $n-1$ au lieu de $n$. C’est la correction de Bessel. En 2026, cette distinction est automatisée dans les bibliothèques du langage Python, mais le Data Scientist doit comprendre pourquoi elle existe pour éviter de sous-estimer le risque. Cette rigueur méthodologique garantit que le patrimoine informationnel produit est statistiquement valide et non biaisé.
5. L’implémentation sur Excel : Les fonctions STDEV
Pour la plupart des analystes, le calcul se fait via un tableur. Excel propose les fonctions ECART.TYPE.PE (population) et ECART.TYPE.ST (échantillon). Savoir quelle fonction utiliser est le premier pas vers une analyse de Data Management rigoureuse. Couplé aux graphiques en barres d’erreur, l’écart-type permet de transformer une feuille de calcul statique en un outil d’aide à la décision dynamique, capable de mettre en lumière les zones d’incertitude du système d’information.
6. L’automatisation avec Python (Numpy et Pandas)
Dans le monde du Big Data et du Cloud Computing, le calcul manuel est impossible. En langage Python, une simple commande comme df.std() ou numpy.std() traite des millions de lignes en une fraction de seconde. Les experts de DATAROCKSTARS apprennent à intégrer ces calculs dans des pipelines automatisés d’intelligence artificielle pour surveiller la dérive des modèles (model drift) et garantir la maintenance applicative des systèmes prédictifs en temps réel.
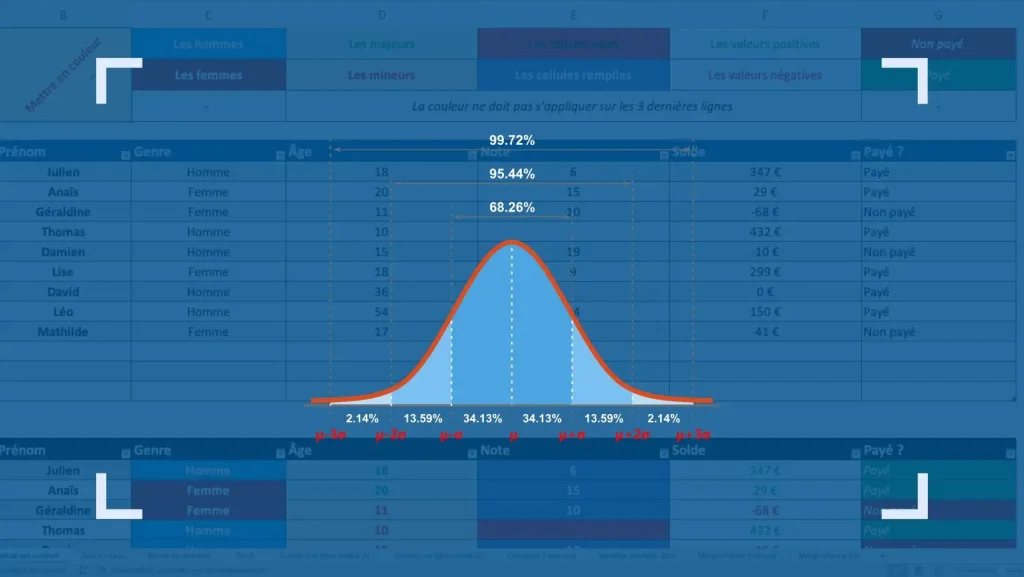
7. La règle des 68-95-99.7 (Loi Normale)
Dans une distribution normale, environ 68% des données se situent à moins d’un écart-type de la moyenne, 95% à moins de deux, et 99.7% à moins de trois. Cette règle est le socle de la qualité industrielle (Six Sigma). En cybersécurité, toute donnée se situant au-delà de 3 sigmas est immédiatement considérée comme une anomalie potentielle à investiguer. Cette application pratique transforme l’écart-type en un véritable gardien du patrimoine informationnel de l’entreprise.
8. Interprétation en Finance et Gestion du Risque
En finance, l’écart-type est le synonyme mathématique de la volatilité. Un actif avec un écart-type élevé est considéré comme risqué car ses rendements sont imprévisibles. Maîtriser ce calcul permet aux analystes de construire des portefeuilles équilibrés et de sécuriser les investissements sur le Cloud Computing. Cette vision quantitative du risque est indispensable pour la pérennité du système d’information financier d’une organisation moderne.
9. Limites et pièges de l’écart-type
L’écart-type est extrêmement sensible aux valeurs aberrantes (outliers). Une seule donnée extrême peut gonfler l’indicateur et donner une fausse impression de dispersion globale. C’est pourquoi, chez DATAROCKSTARS, nous enseignons à toujours coupler l’écart-type avec d’autres mesures comme l’écart interquartile ou la médiane. Cette approche critique du Data Management est ce qui distingue un technicien d’un véritable stratège de la donnée.
10. Conclusion : Pourquoi maîtriser l’Écart-Type avec DATAROCKSTARS ?
Calculer l’écart-type, c’est apprendre à lire entre les lignes des moyennes. En 2026, l’excellence d’un profil data repose sur sa capacité à quantifier l’incertain et à apporter de la nuance dans un monde de chiffres bruts. Maîtriser cet indicateur, c’est s’assurer que vos conclusions sont robustes, que vos modèles d’IA sont fiables et que votre compréhension du patrimoine informationnel est totale.
Chez DATAROCKSTARS, nous vous formons à cette rigueur analytique indispensable. En rejoignant nos cursus, vous apprenez à transformer ces concepts mathématiques en leviers de performance pour vos projets de Data Science, de cybersécurité et d’intelligence artificielle. Ne vous laissez pas tromper par les apparences : apprenez à mesurer la réalité profonde de vos données pour devenir un leader de la révolution technologique.
Aspirez-vous à maîtriser les rouages des modèles de langage et à concevoir des solutions d’IA ultra-performantes ? Notre formation Data Scientist & AI Engineer vous apprend à exploiter l’écosystème Python et le traitement intelligent des flux sémantiques, afin de propulser votre expertise vers les frontières de l’innovation moderne.
Merci pour votre lecture ! Si vous souhaitez découvrir nos prochains articles autour de la Data et de l’IA, vous pouvez nous suivre sur Facebook, LinkedIn et Twitter pour être notifié dès la publication d’un nouvel article !