Le versionning (ou gestion de versions) est un système qui enregistre les modifications apportées à un fichier ou à un ensemble de fichiers au fil du temps, permettant ainsi de retrouver des versions spécifiques ultérieurement. Dans un système d’information moderne, c’est le filet de sécurité absolu. Qu’il s’agisse de code source en langage Python, de modèles de Data Science ou de configurations sur le Cloud Computing, le versionning permet de collaborer sans risque de perte. Il transforme le patrimoine informationnel technique en un historique vivant, où chaque changement est documenté, réversible et auditable.
Pour les talents formés chez DATAROCKSTARS, le versionning est une hygiène de travail non négociable. Que vous soyez futur Data Engineer ou Développeur, maîtriser des outils comme Git est une compétence clé des métiers data qui recrutent.
1. La traçabilité totale du patrimoine informationnel
Le premier bénéfice du versionning est de savoir qui a fait quoi, quand et pourquoi. Chaque “commit” (enregistrement) est accompagné d’un message explicatif. Cette transparence est un aspect vital pour tout savoir sur l’évolution d’un projet. Elle permet de maintenir la cohérence du système d’information en conservant une trace indélébile de chaque décision technique prise sur le Cloud Computing.
2. Le droit à l’erreur et le retour en arrière (Rollback)
L’erreur est humaine, mais en informatique, elle peut être fatale sans versionning. Si une mise à jour corrompt une base de données SQL ou fait planter un algorithme d’intelligence artificielle, le versionning permet de revenir instantanément à l’état stable précédent. Cette capacité de “rollback” assure la maintenance applicative et protège le patrimoine informationnel contre les régressions critiques.
3. Le travail collaboratif et la gestion des conflits
Le versionning permet à plusieurs ingénieurs de travailler simultanément sur le même fichier. Grâce aux mécanismes de “merge” (fusion), le système identifie les modifications divergentes. Pour le Data Management, c’est la fin des fichiers nommés “rapport_v1_final_V2”. Le patrimoine informationnel technique est centralisé, et les conflits sont résolus de manière structurée au sein du système d’information.
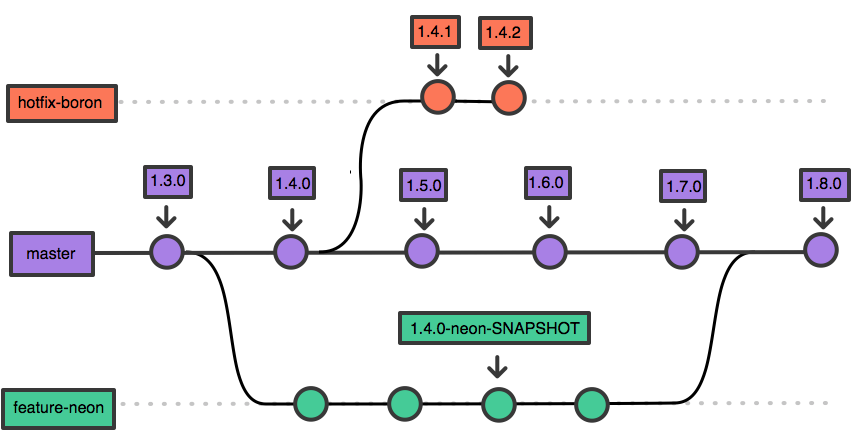
4. Les branches : des laboratoires isolés pour l’innovation
Une “branche” est une copie virtuelle du projet où l’on peut tester une nouvelle fonctionnalité ou un modèle de Data Science sans impacter la version de production. Si le test est concluant, on fusionne la branche avec le tronc principal. Cette isolation sur le Cloud Computing permet d’innover en continu tout en garantissant la stabilité du système d’information principal de l’entreprise.
5. Git : le standard universel du versionning
Git est l’outil de versionning décentralisé le plus utilisé au monde. Contrairement aux anciens systèmes, chaque collaborateur possède une copie intégrale du patrimoine informationnel sur sa machine. Cette architecture robuste facilite le travail hors-ligne et renforce la cybersécurité, car le code est répliqué sur plusieurs nœuds. Sa maîtrise est le socle de toute carrière en Data Science et en développement moderne.
6. Versionning de données (DVC) et reproductibilité
En Data Science, on ne versionne pas que le code, on versionne aussi les données et les modèles. Des outils comme DVC (Data Version Control) permettent de lier une version spécifique du code à un dataset précis stocké sur le Cloud Computing. Cette rigueur garantit la reproductibilité des expériences d’intelligence artificielle, un pilier fondamental du Data Management scientifique.
7. Audit et conformité (Compliance)
Dans les secteurs régulés, le versionning est une obligation légale. Il permet de prouver l’intégrité du patrimoine informationnel lors d’audits de cybersécurité. Savoir exactement quel code tournait en production à une date précise est essentiel pour répondre aux exigences de transparence du système d’information. C’est la garantie que l’entreprise maîtrise ses algorithmes de bout en bout.
8. Intégration avec la CI/CD (DevOps)
Le versionning est l’étincelle qui déclenche les pipelines d’automatisation. Dès qu’une modification est validée dans le système de versionning, des tests automatisés sont lancés sur le Cloud Computing. Cette synergie entre code et opérations accélère la maintenance applicative et permet de livrer des solutions de Business Intelligence plus fiables et plus rapides.
9. Gestion des versions sémantiques (SemVer)
Le versionning impose une nomenclature (ex: v1.2.0). Le premier chiffre indique une rupture majeure, le second une nouveauté, et le troisième un correctif. Cette standardisation du patrimoine informationnel technique permet aux autres systèmes du Cloud Computing de savoir si une mise à jour est compatible. C’est une règle d’or du Data Management pour éviter de casser les dépendances logicielles.
10. L’avenir : Versionning piloté par l’IA
L‘intelligence artificielle aide à gérer les versions. Des Agents IA & Automations peuvent suggérer des messages de commit, identifier des codes redondants ou même résoudre automatiquement des conflits de fusion simples. Cette évolution marque le sommet du système d’information intelligent, où le patrimoine informationnel technique s’auto-documente et s’auto-répare pour servir l’innovation.
Le versionning est la boussole temporelle de la technologie. Posséder cette maîtrise technique permet de sécuriser ses développements, de fluidifier le travail d’équipe et de valoriser son patrimoine informationnel. C’est la compétence pivot qui transforme un bricolage de fichiers en une ingénierie logicielle rigoureuse et professionnelle.
Chez DATAROCKSTARS, nous vous formons à cette discipline de fer. En rejoignant nos cursus, vous apprenez à dompter Git, à versionner vos modèles de données et à bâtir des solutions d’intelligence artificielle fondées sur un historique irréprochable. Ne perdez plus jamais une ligne de code : apprenez à graver vos succès dans le temps pour devenir un leader de la révolution technologique.
Aspirez-vous à maîtriser les rouages de l’ingénierie moderne et à devenir un expert du versionning de données ? Notre formation Data Engineer & AIOps vous apprend à exploiter l’écosystème numérique et le traitement intelligent des flux, afin de propulser votre expertise vers les frontières de l’innovation moderne.
Merci pour votre lecture ! Si vous souhaitez découvrir nos prochains articles autour de la Data et de l’IA, vous pouvez nous suivre sur Facebook, LinkedIn et Twitter pour être notifié dès la publication d’un nouvel article !