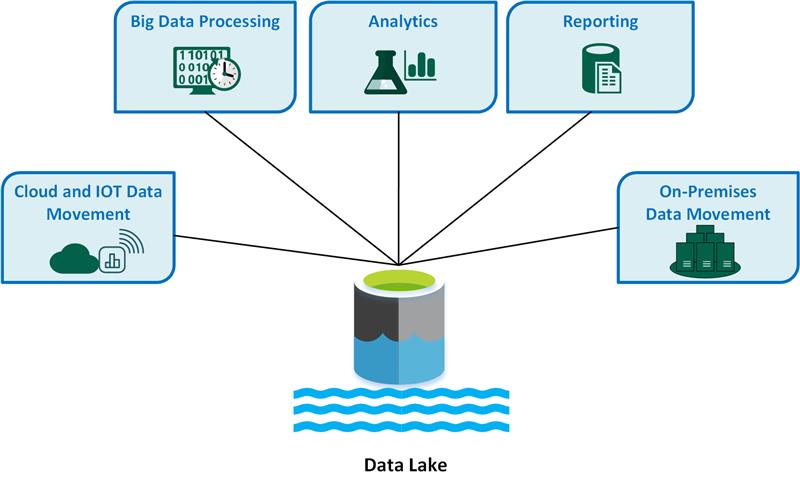
Un Data Lake (ou lac de données) est un répertoire de stockage centralisé qui permet de conserver de vastes quantités de données brutes dans leur format natif. Contrairement au Data Warehouse traditionnel, qui impose une structure rigide avant le stockage, le Data Lake accepte tout type d’information : données structurées (SQL), semi-structurées (JSON, XML) ou non structurées (images, documents, logs). C’est cette flexibilité qui en fait le socle indispensable pour les projets de Data Science et d’apprentissage automatique à grande échelle.
Pour les professionnels qui aspirent à concevoir et gérer ces infrastructures, DATAROCKSTARS propose des cursus d’immersion technique de haut niveau. En apprenant à orchestrer ces réservoirs de données massifs sur le Cloud Computing, vous rejoignez l’élite des métiers data qui recrutent, capables de transformer un déluge d’informations en décisions stratégiques.
1. Définition et fondements techniques : L’architecture “Schema-on-Read”
Le concept fondamental du Data Lake repose sur le principe du “Schema-on-Read” (schéma à la lecture). Au lieu de transformer les données pour qu’elles rentrent dans des cases prédéfinies (ETL), on les stocke telles quelles et on définit leur structure uniquement au moment où on en a besoin pour une analyse précise.
Les composants techniques d’un Data Lake moderne incluent :
- Le Stockage Distribué : Souvent basé sur des technologies comme HDFS ou des services Cloud comme AWS S3 ou Azure Data Lake Storage.
- La Couche de Gouvernance : Pour cataloguer les données et éviter que le lac ne se transforme en “Data Swamp” (marécage de données) inexploitable.
- Le Moteur de Calcul : Des outils comme Spark ou Presto qui viennent “puiser” dans le lac pour transformer les données à la volée via le langage Python.
2. À quoi sert un Data Lake dans le monde professionnel ?
Dans le secteur de la Santé, un Data Lake permet de stocker des dossiers patients (structurés), mais aussi des radiographies (images) et des rapports de recherche (texte brut) pour entraîner des IA de diagnostic. Dans la Finance, il centralise tous les journaux de transactions et les flux des réseaux sociaux pour détecter la fraude ou analyser le sentiment du marché en temps réel.
Cette capacité à briser les silos d’informations permet une vision à 360° de l’activité. En maîtrisant la conception de ces architectures via le Bootcamp Data Engineer & AIOps de DATAROCKSTARS, vous devenez capable de maintenir un système d’information agile, prêt à répondre à n’importe quelle question métier imprévue.
3. Classement des 10 avantages majeurs du Data Lake
- Flexibilité totale : Accepte tous les formats de données sans distinction.
- Scalabilité massive : Capacité à stocker des pétaoctets de données à moindre coût.
- Vitesse d’ingestion : Les données sont stockées instantanément, sans attendre un processus de transformation long.
- Support natif de l’IA : Idéal pour alimenter les algorithmes de Deep Learning gourmands en données brutes.
- Démocratisation de la donnée : Permet à différents profils (Data Scientists, Analystes) d’accéder aux mêmes sources.
- Conservation historique : Possibilité de garder des données “au cas où” elles deviendraient utiles plus tard.
- Coût réduit : Utilisation de stockages objets économiques sur le Cloud.
- Interopérabilité : Facilité de connexion avec des outils d’analyse comme Power BI ou Tableau.
- Analyse en temps réel : Supporte l’ingestion de flux continus (streaming).
- Gouvernance centralisée : Un seul point de contrôle pour la sécurité et la conformité.
4. Data Lake vs Data Warehouse : Quelles différences ?
Il est crucial de comprendre que ces deux architectures sont souvent complémentaires plutôt que concurrentes.
| Caractéristique | Data Lake | Data Warehouse |
| Données | Brutes et non structurées | Structurées et traitées |
| Schéma | Schema-on-Read | Schema-on-Write |
| Utilisateurs | Data Scientists, Engineers | Business Analysts, Managers |
| Coût | Faible (stockage de masse) | Plus élevé (performance optimisée) |
Le passage vers une architecture hybride, appelée Data Lakehouse, est au cœur de l’apprentissage chez DATAROCKSTARS. Nous formons nos étudiants à bâtir des systèmes qui combinent la souplesse du lac avec la fiabilité du warehouse.
5. L’impact de l’IA sur l’évolution des Data Lakes
L’intelligence artificielle générative a besoin de “contextes” massifs pour être pertinente. Le Data Lake est l’endroit où l’on stocke les bases de connaissances nécessaires au RAG (Retrieval-Augmented Generation), permettant à une IA de répondre en s’appuyant sur les documents réels de l’entreprise.
En 2026, l’IA aide également à gérer le lac. Des algorithmes d’AIOps surveillent la qualité des données entrantes, détectent les anomalies et automatisent le catalogage des fichiers orphelins. Maîtriser ces outils est l’un des piliers de notre formation Agents IA & Automations, car un agent intelligent n’est efficace que s’il a accès à un réservoir de données bien organisé.
6. Cybersécurité : Protéger le patrimoine de données
Centraliser toutes les données d’une entreprise dans un lac crée un point de vulnérabilité majeur. La cybersécurité d’un Data Lake repose sur le chiffrement, la gestion fine des identités (IAM) et l’audit permanent des accès.
Pour tout savoir sur la cybersécurité des infrastructures critiques, le passage par un bootcamp spécialisé chez DATAROCKSTARS est essentiel. Vous y apprendrez à mettre en place des politiques “Zero Trust” pour garantir que seuls les utilisateurs et les services autorisés puissent puiser dans le lac de données.
7. Le Data Lake dans le Cloud : AWS, Azure et Google
Aujourd’hui, la majorité des Data Lakes sont construits sur le Cloud. Les services comme Amazon S3 ou Google Cloud Storage offrent une durabilité et une disponibilité quasi parfaites. Ces plateformes permettent également d’utiliser des architectures “serverless”, où l’on ne paie que pour le calcul consommé lors de l’analyse des données.
Cette maîtrise des infrastructures Cloud est au cœur du Bootcamp Data Engineer & AIOps de DATAROCKSTARS. Nous apprenons à nos étudiants à déployer ces solutions via des outils comme Docker et Terraform, assurant une maintenance applicative simplifiée et une portabilité maximale entre les différents fournisseurs.
8. Conclusion et perspectives d’avenir
Le Data Lake est la fondation sur laquelle repose l’entreprise pilotée par la donnée. En 2026, il n’est plus un simple lieu de stockage, mais un écosystème vivant et intelligent. Sa capacité à absorber l’imprévu en fait l’actif le plus précieux pour toute organisation souhaitant survivre à l’ère de l’IA.
L’avenir appartient aux architectes capables de transformer ces vastes étendues d’informations en flux de valeur continus. En maîtrisant l’ingénierie des Data Lakes chez DATAROCKSTARS, vous vous positionnez au centre de la révolution technologique actuelle.
Aspirez-vous à maîtriser les rouages du Big Data et à concevoir des architectures de données massives ? Notre formation Data Engineer & AIOps vous apprend à explorer l’écosystème distribué et le traitement de flux à grande échelle, afin de propulser votre expertise vers les frontières de l’ingénierie des données.
Merci pour votre lecture ! Si vous souhaitez découvrir nos prochains articles autour de la Data et de l’IA, vous pouvez nous suivre sur Facebook, LinkedIn et Twitter pour être notifié dès la publication d’un nouvel article !