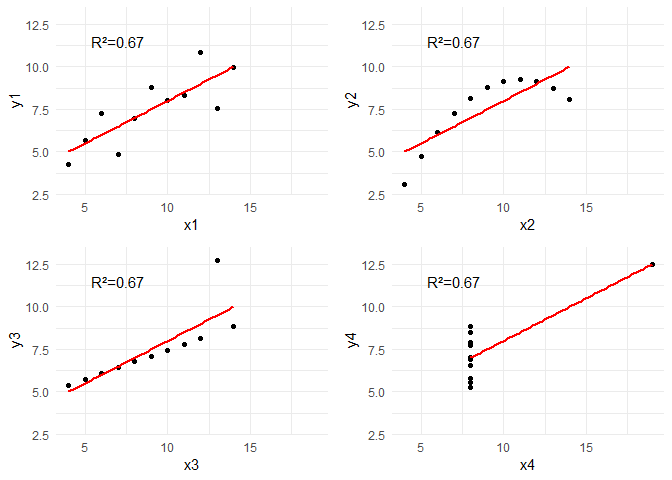
Le coefficient de détermination, universellement noté $R^2$ (R-deux), est une métrique statistique utilisée pour évaluer la qualité d’une régression linéaire ou d’un modèle de prédiction. Il mesure la proportion de la variance de la variable dépendante qui est expliquée par les variables indépendantes du modèle. Dans un système d’information décisionnel, le $R^2$ est le pivot indispensable pour savoir si un modèle mathématique reflète fidèlement la réalité ou s’il n’est qu’un bruit statistique. Sur le Cloud Computing, il permet de valider la puissance de vos algorithmes avant leur déploiement à grande échelle.
Pour les talents formés chez DATAROCKSTARS, maîtriser le coefficient de détermination est une compétence fondamentale. Que vous soyez futur Data Analyst ou ingénieur en intelligence artificielle, comprendre cette valeur est une compétence clé des métiers data qui recrutent.
1. Définition mathématique et calcul du R2
Le coefficient de détermination représente le rapport entre la variance expliquée par le modèle et la variance totale du patrimoine informationnel. Mathématiquement, il se calcule par la formule suivante :
$$R^2 = 1 – \frac{SS_{res}}{SS_{tot}}$$
Où $SS_{res}$ est la somme des carrés des résidus et $SS_{tot}$ la somme totale des carrés. Ce calcul permet au système d’information de quantifier précisément la fiabilité d’une tendance identifiée au sein de vos données sur le Cloud Computing.
2. Interprétation de la valeur entre 0 et 1
Le $R^2$ est un score normalisé qui varie toujours entre 0 et 1. Une valeur de 0 indique que le modèle n’explique absolument rien de la variabilité des données. Une valeur de 1 signifie que le modèle prédit parfaitement chaque point du patrimoine informationnel. Pour la Data Science, atteindre un score proche de 1 est souvent l’objectif recherché lors de l’entraînement de modèles sur le Cloud Computing.
3. Corrélation versus Détermination
Il existe un lien direct entre le coefficient de corrélation de Pearson ($r$) et le coefficient de détermination. Pour une régression simple, le $R^2$ est littéralement le carré de $r$. Si une corrélation est de 0,7, le $R^2$ sera de 0,49, signifiant que 49% de la variation est expliquée. Cette nuance est un aspect vital pour tout savoir sur la force réelle d’une relation au sein du système d’information.
4. Le piège de l’ajout de variables inutiles
Un défaut majeur du $R^2$ classique est qu’il augmente mécaniquement chaque fois que l’on ajoute une variable, même non pertinente, au modèle. Cela peut donner une fausse impression de précision de votre patrimoine informationnel technique. C’est un risque majeur de surapprentissage (overfitting) que le Data Management doit impérativement surveiller lors des phases de tests sur le Cloud Computing.
5. Le R2 ajusté pour une mesure de précision réelle
Pour corriger le biais lié au nombre de variables, les experts utilisent le R2 ajusté. Ce dernier pénalise l’ajout de variables qui n’apportent pas d’amélioration significative au système d’information. C’est la métrique préférée en Data Science pour comparer des modèles complexes et garantir que le patrimoine informationnel est modélisé de la manière la plus sobre et efficace possible.
6. Utilisation du R2 comme métrique de Machine Learning
En intelligence artificielle, le coefficient de détermination sert de score de validation pour les modèles de régression. Il permet de comparer la performance d’algorithmes comme les forêts aléatoires ou le gradient boosting sur le Cloud Computing. Intégré au système d’information, il devient un indicateur de performance (KPI) pour le pilotage automatique du patrimoine informationnel.
7. Limites et interprétation contextuelle du coefficient
Un $R^2$ élevé ne signifie pas nécessairement que le modèle est bon. Il ne détecte pas les biais systématiques et ne prouve jamais une relation de causalité. De plus, il est extrêmement sensible aux valeurs aberrantes (outliers) présentes dans le patrimoine informationnel. Le Data Management doit donc toujours coupler cet indicateur à une analyse des résidus au sein du système d’information.
8. Calcul automatique avec Python et bibliothèques Data
Dans le langage Python, le calcul du coefficient de détermination est instantané grâce à des bibliothèques comme Scikit-Learn ou Statsmodels. Cette automatisation permet d’intégrer des tests de qualité dans vos Agents IA & Automations, facilitant la maintenance applicative des modèles de production hébergés sur le Cloud Computing.
9. Importance du R2 selon le secteur métier
L’exigence de valeur du $R^2$ varie selon le domaine. En ingénierie ou en physique, on attend souvent un score supérieur à 0,95. En marketing ou en sciences humaines, un $R^2$ de 0,4 peut être considéré comme très satisfaisant en raison de la complexité des comportements. Le système d’information doit donc adapter ses seuils de tolérance au patrimoine informationnel spécifique de chaque métier.
10. L’avenir : Métriques avancées et évaluation par l’IA
En 2026, si le coefficient de détermination reste un standard, l’intelligence artificielle introduit des méthodes d’évaluation plus dynamiques. On utilise désormais des techniques de validation croisée et des scores de stabilité pour s’assurer que le patrimoine informationnel reste prédictif dans le temps. Le $R^2$ devient ainsi une pièce d’un puzzle plus large pour un Data Management de haute précision sur le Cloud Computing.
Le coefficient de détermination est le premier juge de la valeur de vos modèles. Posséder cette maîtrise technique permet de séparer les signaux utiles du bruit, de sécuriser vos prévisions et de valoriser le patrimoine informationnel de votre entreprise. C’est la compétence pivot qui transforme une simple analyse en une aide à la décision incontestable.
Chez DATAROCKSTARS, nous vous formons à l’excellence statistique. En rejoignant nos cursus, vous apprenez à bâtir des modèles robustes, à interpréter les métriques de performance et à déployer des solutions d’intelligence artificielle fondées sur une analyse rigoureuse du patrimoine informationnel.
Souhaitez-vous découvrir comment notre formation Data Analyst & AI peut vous aider à maîtriser le coefficient de détermination pour propulser votre carrière ?
Merci pour votre lecture ! Si vous souhaitez découvrir nos prochains articles autour de la Data et de l’IA, vous pouvez nous suivre sur Facebook, LinkedIn et Twitter pour être notifié dès la publication d’un nouvel article !