Dans l’univers du Machine Learning et du Deep Learning, la descente de gradient (Gradient Descent) est sans aucun doute l’algorithme le plus important. C’est lui qui permet à un modèle “d’apprendre” à partir des données. Son rôle est simple en apparence mais complexe mathématiquement : ajuster les paramètres du modèle (poids et biais) de manière itérative afin de minimiser une fonction de coût (l’erreur du modèle).
Chez DATAROCKSTARS, nous enseignons que comprendre la descente de gradient, c’est comprendre comment l’IA progresse vers la solution optimale. Que vous construisiez une simple régression ou un réseau de neurones profond, cet algorithme est le chef d’orchestre qui guide votre modèle vers la précision.
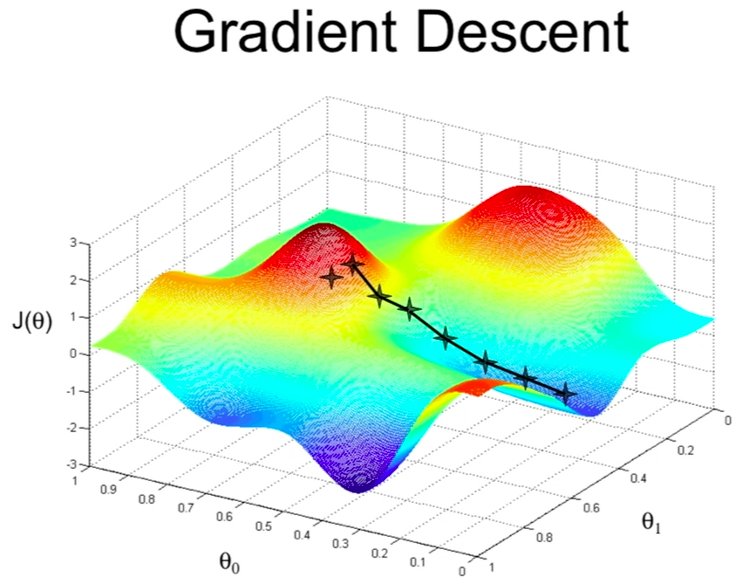
1. L’analogie de la montagne dans le brouillard
Pour visualiser la descente de gradient, imaginez que vous êtes au sommet d’une montagne par un brouillard très épais. Votre objectif est d’atteindre le point le plus bas de la vallée (le minimum de la fonction de coût). Comme vous ne voyez pas le paysage, vous regardez le sol sous vos pieds pour déterminer la direction de la pente la plus raide.
• La pente : C’est le gradient. Il vous indique la direction vers laquelle l’erreur augmente le plus.
• Le pas : C’est le taux d’apprentissage (learning rate). C’est la taille du pas que vous faites vers le bas.
L’algorithme répète cette opération jusqu’à ce que la pente soit nulle (ou presque), ce qui signifie que vous avez atteint le fond de la vallée. Dans nos formations, nous utilisons ces visualisations pour ancrer la compréhension géométrique de l’optimisation.
2. La Fonction de Coût (Loss Function)
Avant de descendre, il faut savoir ce que l’on mesure. La fonction de coût quantifie l’écart entre la prédiction de l’IA et la réalité. Plus le coût est élevé, plus le modèle se trompe. La descente de gradient cherche à minimiser cette fonction.
Les fonctions les plus courantes incluent :
• MSE (Mean Squared Error) : Utilisée pour la régression.
• Cross-Entropy : Utilisée pour la classification.
Comprendre quelle fonction de coût minimiser est crucial. Chez DATAROCKSTARS, nous vous apprenons à choisir la métrique de performance adaptée à chaque problématique métier.
3. Le calcul du Gradient : Dérivées et Sensibilité
Mathématiquement, le gradient est le vecteur des dérivées partielles de la fonction de coût par rapport à chaque paramètre du modèle. Il indique comment une petite variation d’un paramètre (un poids) affecte l’erreur globale.
Si la dérivée est positive, augmenter le poids augmente l’erreur. Si elle est négative, augmenter le poids diminue l’erreur. L’algorithme déplace donc les paramètres dans la direction opposée au gradient. Cette rigueur mathématique est le socle de notre Bootcamp Data Scientist & AI Engineer.
4. Le Taux d’Apprentissage (Learning Rate)
Le taux d’apprentissage (souvent noté $\alpha$ ou $\eta$) est le paramètre le plus critique. Il contrôle la vitesse de la descente :
• Trop grand : Vous risquez de “sauter” par-dessus le minimum et de ne jamais converger (le modèle diverge).
• Trop petit : La descente sera extrêmement lente et pourra rester bloquée dans un “minimum local” au lieu d’atteindre le “minimum global”.
[Image comparing small versus large learning rate effects on gradient descent convergence]
Savoir ajuster ce paramètre est un art que nous développons par la pratique intensive. Chez DATAROCKSTARS, nous vous montrons comment utiliser des techniques de “Learning Rate Decay” pour stabiliser l’apprentissage.
5. Batch Gradient Descent : La méthode classique
Dans cette version, on calcule le gradient en utilisant l’intégralité du jeu de données à chaque étape. C’est une méthode très précise qui produit une trajectoire de descente très fluide vers le minimum.
Cependant, sur des jeux de données massifs (Big Data), cette méthode devient extrêmement lente et gourmande en mémoire vive. C’est pourquoi, dans nos cursus de Data Engineering, nous explorons des alternatives plus performantes pour l’industrie.
6. Stochastic Gradient Descent (SGD)
Le SGD calcule le gradient pour chaque exemple de donnée individuellement. La trajectoire est beaucoup plus “bruitée” et chaotique, mais l’algorithme est beaucoup plus rapide et peut s’échapper plus facilement des minimums locaux.
[Image showing the noisy path of Stochastic Gradient Descent versus the smooth path of Batch Gradient Descent]
Ce “bruit” est parfois une force car il permet d’explorer l’espace des solutions de manière plus dynamique. Chez DATAROCKSTARS, nous vous apprenons à dompter cette instabilité pour obtenir des modèles robustes.
7. Mini-Batch Gradient Descent : Le juste milieu
C’est la méthode standard utilisée aujourd’hui, notamment pour entraîner les réseaux de neurones profonds. On divise les données en petits groupes (mini-batches, par exemple de 32 ou 64 exemples). On calcule le gradient sur un groupe, on met à jour les poids, et on passe au groupe suivant.
Cette méthode combine la stabilité du Batch et la rapidité du SGD. Elle est particulièrement efficace sur les GPU. La maîtrise du dimensionnement des batches est une compétence clé que nous transmettons dans nos projets d’IA à grande échelle.
8. Les variantes avancées : Momentum et Adam
La descente de gradient “pure” peut parfois être inefficace sur des surfaces de coût complexes. Des optimiseurs plus avancés ont été créés :
• Momentum : Ajoute une notion d’inertie pour accélérer la descente dans les directions constantes.
• Adam (Adaptive Moment Estimation) : Adapte automatiquement le taux d’apprentissage pour chaque paramètre. C’est l’optimiseur par défaut dans la plupart des projets d’IA modernes.
Comprendre le fonctionnement interne d’Adam est indispensable. Chez DATAROCKSTARS, nous décortiquons ces algorithmes pour que vous ne les utilisiez pas comme des “boîtes noires”.
9. Le problème des Gradients qui disparaissent (Vanishing Gradients)
Dans les réseaux de neurones très profonds, lors de la rétropropagation (backpropagation), les gradients peuvent devenir si petits qu’ils finissent par s’annuler. Le modèle n’apprend plus rien dans les couches initiales.
[Image depicting the vanishing gradient problem in deep neural networks layers]
C’est un défi majeur du Deep Learning. Nous formons nos ingénieurs à utiliser des techniques comme les fonctions d’activation ReLU ou les connexions résiduelles pour contourner ce problème technique.
10. Pourquoi maîtriser l’optimisation avec DATAROCKSTARS
La descente de gradient est le cœur battant de l’IA. Maîtriser ses nuances, c’est être capable de diagnostiquer pourquoi un modèle n’apprend pas et savoir comment corriger sa trajectoire. C’est une compétence qui sépare les amateurs des experts en intelligence artificielle.
Chez DATAROCKSTARS, nous vous donnons la rigueur mathématique et l’expérience pratique nécessaire pour dompter ces algorithmes d’optimisation. Prêt à faire descendre vos fonctions de coût vers l’excellence ? Souhaitez-vous découvrir comment notre Bootcamp Data Scientist & AI Engineer peut vous aider à devenir un maître de l’apprentissage machine ?
Merci pour votre lecture ! Si vous souhaitez découvrir nos prochains articles autour de la Data et de l’IA, vous pouvez nous suivre sur Facebook, LinkedIn et Twitter pour être notifié dès la publication d’un nouvel article !