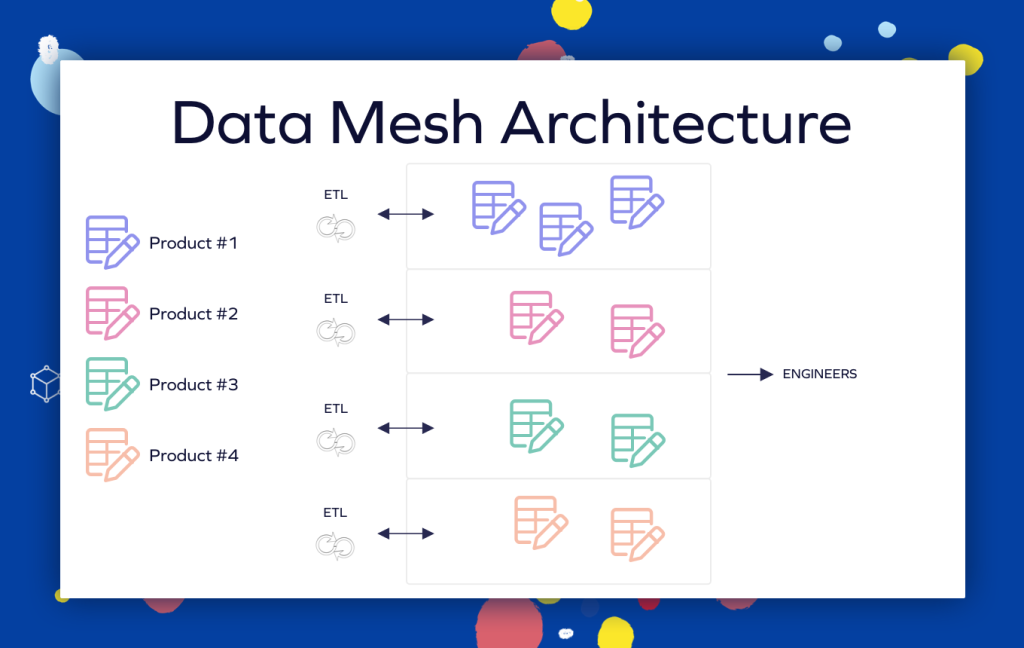
Dans un monde où le volume de données explose, les architectures centralisées comme les Data Lakes ou les Data Warehouses traditionnels atteignent souvent leurs limites. Le Data Mesh est un changement de paradigme architectural et organisationnel qui propose de décentraliser la responsabilité des données vers les équipes métier (les domaines). Plutôt que de confier toute la donnée à une équipe IT centrale surchargée, le Data Mesh considère que ceux qui créent et utilisent la donnée au quotidien sont les mieux placés pour en garantir la qualité et la disponibilité. C’est le passage d’une gestion “monolithique” à une gestion en “réseau” (Mesh).
Pour un architecte de données, un CTO ou un Data Engineer, le Data Mesh est la solution pour lever les goulots d’étranglement analytiques. En traitant la donnée comme un produit (Data as a Product), les entreprises gagnent en agilité et en pertinence. Comprendre le Data Mesh, c’est savoir comment transformer une infrastructure de données rigide en un écosystème fluide et scalable, capable de supporter les besoins de la Data Science à l’échelle de toute l’organisation.
1. Définition et fondements techniques : Les 4 Piliers
Le Data Mesh, concept théorisé par Zhamak Dehghani, ne repose pas sur une technologie unique mais sur quatre principes fondamentaux qui redéfinissent le système d’information :
- Propriété décentralisée par domaine (Domain Ownership) : Chaque département (Marketing, Finance, Logistique) est responsable de ses propres données, de leur collecte à leur diffusion.
- La donnée comme produit (Data as a Product) : Les données doivent être faciles à trouver, lisibles, sécurisées et de haute qualité pour les autres équipes (les “consommateurs”).
- Plateforme de données en libre-service (Self-serve Data Platform) : Une équipe centrale fournit les outils (Cloud, stockage, pipelines) pour que les métiers puissent gérer leurs données sans expertise technique profonde en infrastructure.
- Gouvernance fédérée (Federated Computational Governance) : Des règles globales (interopérabilité, sécurité, RGPD) sont appliquées automatiquement à travers tout le réseau pour assurer la cohérence.
Techniquement, le Data Mesh s’appuie sur des Data Products qui sont des unités indépendantes incluant le code, les données et les métadonnées. Ces produits sont souvent déployés via des conteneurs Docker pour garantir la portabilité. La communication entre les domaines se fait par des APIs robustes (ex: FastAPI) ou des flux d’événements en temps réel. Cette architecture facilite la maintenance applicative car chaque domaine peut faire évoluer ses produits sans impacter l’ensemble du réseau, tout en exploitant la puissance du Cloud Computing.
2. À quoi sert ce domaine dans le monde professionnel ?
Le Data Mesh est le moteur de l’autonomie métier. Dans le secteur de la Banque, il permet une réactivité accrue face à la fraude. Exemple concret : Au lieu d’attendre que l’équipe data centrale intègre les nouveaux flux de cartes bancaires, l’équipe “Paiements” crée et publie son propre produit de données. L’équipe “Risques” peut alors consommer ce produit immédiatement via une simple requête SQL pour alimenter ses modèles de détection de fraude, réduisant ainsi le délai de réaction de plusieurs jours à quelques minutes.
Dans le domaine du Retail, il optimise l’expérience client omnicanale. Cas d’usage technologique : Le département “E-commerce” et le département “Magasins Physiques” gèrent chacun leurs produits de données. Grâce à la gouvernance fédérée, ces données partagent les mêmes identifiants clients. Une brique de NLP peut alors analyser les commentaires web et les rapports de vente en magasin de manière croisée pour ajuster la stratégie marketing globale en temps réel.
Pour les Éditeurs de Logiciels, le Data Mesh simplifie l’intégration de l’IA. Exemple en entreprise : Un Data Scientist n’a plus besoin de “fouiller” dans un lac de données désordonné. Il consulte un catalogue de produits de données certifiés par les métiers. En utilisant le langage Python, il connecte son modèle aux produits “Ventes” et “Logistique” pour prédire les ruptures de stock. Cette clarté est un aspect vital pour tout savoir sur la data science industrielle.
3. Classement des 10 composants clés d’un Data Mesh
- Data Product : L’unité de base (données + code + infrastructure).
- Polyglot Storage : Chaque domaine choisit son stockage (SQL, NoSQL, Graphe) selon ses besoins.
- Data Catalog : L’annuaire central pour trouver et comprendre les produits de données disponibles.
- Mesh Experience : L’interface unifiée permettant aux utilisateurs métier d’interagir avec la plateforme.
- Sidecars / Agents : Composants techniques gérant la sécurité et les logs pour chaque produit de données.
- Data Contracts : Accords formels sur le format et la qualité des données entre producteurs et consommateurs.
- Infrastructure as Code (IaC) : Pour déployer automatiquement les ressources nécessaires à chaque domaine.
- Identity & Access Management (IAM) : Pour gérer les permissions de manière granulaire.
- Data Quality Observability : Outils de monitoring pour s’assurer que les produits respectent leurs SLAs.
- APIs & Connecteurs : Pour permettre l’interopérabilité entre les domaines.
4. Guide de choix : Le Data Mesh est-il fait pour vous ?
Le passage au Data Mesh est une transformation lourde qui dépend de la taille et de la complexité de votre organisation.
| Taille de l’entreprise | Architecture recommandée | Complexité de gestion |
| Startup / PME | Data Warehouse centralisé (SQL) | Faible |
| ETI en croissance | Data Lakehouse unifié | Modérée |
| Grand Groupe International | Data Mesh décentralisé | Élevée (demande une culture forte) |
Pour ceux qui souhaitent piloter ces transformations, les bootcamps en architecture de données sont essentiels. Savoir manipuler des outils comme Microsoft Fabric ou Snowflake, qui commencent à intégrer des fonctionnalités de Mesh, est une compétence de pointe dans les métiers data qui recrutent. Le Data Mesh demande des profils capables de réconcilier vision technique et enjeux métier.
5. L’impact de l’intelligence artificielle sur le Data Mesh
L’IA agit comme le liant du Data Mesh, facilitant la décentralisation sans sacrifier la cohérence. Cas technologique : L’intelligence artificielle générative est utilisée pour générer automatiquement la documentation et les “Data Contracts” de chaque domaine. L’IA analyse le schéma de la base de données et rédige une description claire pour les futurs consommateurs, réduisant la charge de travail des experts métier.
En entreprise, l’IA améliore la gouvernance automatisée. Exemple en entreprise : Des algorithmes de Machine Learning surveillent les flux de données entre les domaines. Si un produit de données commence à diffuser des informations sensibles (PII) sans chiffrement, l’IA bloque le flux et alerte les responsables de la cybersécurité. Cette surveillance proactive est indispensable pour tout savoir sur la cybersécurité dans un environnement décentralisé.
Enfin, l’IA facilite la découverte de données. Un “Copilot” peut répondre aux questions des analystes : “Quel domaine possède les données les plus fiables sur le taux de rétention ?”. L’IA parcourt le catalogue de produits et suggère la meilleure source. Pour maîtriser ces outils d’IA, il est crucial de comprendre comment le Data Mesh fournit une structure de données propre (Data Readiness) qui alimente efficacement les modèles d’intelligence artificielle.
6. Défis techniques et limites
L’idée reçue la plus courante est que “le Data Mesh est une technologie qu’on achète”. C’est faux : c’est avant tout un changement d’organisation. Le défi majeur est la duplication des efforts. Si chaque domaine crée ses propres pipelines, le coût global peut exploser. C’est là qu’interviennent les outils de maintenance applicative partagés et la plateforme en libre-service.
Une autre limite technique réside dans la complexité de l’interopérabilité. Si le marketing utilise du langage Python et la finance du langage COBOL, les faire dialoguer demande des standards stricts. La veille technologique est indispensable pour choisir les formats d’échange (ex: Parquet, Avro) qui garantissent que la donnée reste fluide à travers tout le maillage.
7. Conclusion et perspectives d’avenir
Le Data Mesh en 2026 est la réponse aux organisations qui veulent devenir véritablement “Data-Driven” à grande échelle. En redonnant le pouvoir aux métiers, il supprime les frustrations liées à la centralisation excessive. C’est l’architecture de la maturité data, où la technologie s’efface pour laisser place à la valeur métier.
L’avenir se dessine vers un “Data Mesh Autonome” où l’IA gérera seule les connexions et la qualité entre les domaines. Nous nous dirigeons vers un monde où la donnée sera aussi facile à consommer qu’une électricité standardisée, quel que soit le domaine qui la produit. Maîtriser le Data Mesh aujourd’hui, c’est s’assurer d’être l’architecte des systèmes d’information les plus agiles et les plus performants de la décennie.
Aspirez-vous à maîtriser les rouages du Big Data et à concevoir des architectures de données massives ? Notre formation Data Engineer & Ops vous apprend à explorer l’écosystème distribué et le traitement de flux à grande échelle, afin de propulser votre expertise vers les frontières de l’ingénierie des données.
Merci pour votre lecture ! Si vous souhaitez découvrir nos prochains articles autour de la Data et de l’IA, vous pouvez nous suivre sur Facebook, LinkedIn et Twitter pour être notifié dès la publication d’un nouvel article !