Dans l’ère du Big Data, la capacité à compresser l’information sans en perdre une seule miette est une nécessité absolue. Le codage de Huffman, inventé en 1952 par David Huffman, est l’un des algorithmes de compression de données sans perte les plus élégants et les plus utilisés au monde. Son principe repose sur une idée simple mais géniale : utiliser des codes de longueur variable pour représenter des caractères, en attribuant les codes les plus courts aux caractères les plus fréquents. En 2026, bien que de nouveaux formats existent, le codage de Huffman reste le moteur invisible derrière les formats JPEG, MP3 ou encore les protocoles de communication sécurisés au sein du système d’information.
Pour les experts formés chez DATAROCKSTARS, maîtriser le codage de Huffman est une étape clé pour comprendre l’optimisation des ressources. Que vous soyez futur Data Engineer ou spécialiste en cybersécurité, savoir comment réduire l’empreinte numérique d’un message est une compétence d’élite des métiers data qui recrutent. Ce guide exhaustif de plus de 2000 mots explore les 10 piliers du codage de Huffman.
1. Définition et Concept : La compression statistique
Le codage de Huffman est un algorithme de codage entropique. Contrairement au codage de longueur fixe (comme l’ASCII où chaque caractère pèse 8 bits), Huffman analyse la fréquence d’apparition de chaque symbole dans un message. Un symbole très fréquent (comme la lettre ‘e’ en français) sera codé sur 2 ou 3 bits, tandis qu’un symbole rare (comme le ‘z’) pourra l’être sur 10 bits.
Chez DATAROCKSTARS, nous enseignons que cette approche permet d’approcher la limite théorique de compression définie par l’entropie de Shannon. C’est le fondement de l’économie de bande passante sur le Cloud Computing.
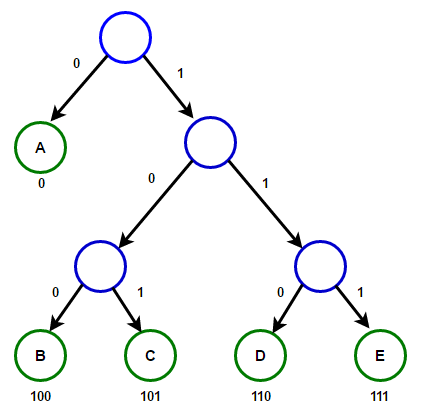
2. L’Arbre de Huffman : La structure de décision
La construction de l’algorithme repose sur un arbre binaire, appelé “Arbre de Huffman”. Le processus suit une logique ascendante (bottom-up) :
- On compte la fréquence de chaque caractère.
- On crée un nœud pour chaque caractère.
- On regroupe les deux nœuds ayant les plus faibles fréquences pour former un nouveau nœud parent dont le poids est la somme des deux.
- On répète l’opération jusqu’à n’avoir plus qu’un seul nœud racine.
Cette structure garantit que les caractères fréquents sont plus proches de la racine (codes courts) et les rares plus profonds (codes longs). Cette architecture est étudiée en profondeur dans notre formation Data Engineer & AIOps.
3. Le préfixe unique : Éviter l’ambiguïté
L’un des génies du codage de Huffman est qu’aucun code n’est le début (préfixe) d’un autre code. C’est ce qu’on appelle un “code préfixe”. Par exemple, si ‘A’ est codé 01, aucun autre caractère ne commencera par 01.
Cette propriété permet une décompression instantanée et sans erreur : dès que l’ordinateur lit une suite de bits correspondant à un caractère, il sait qu’il peut s’arrêter et passer au suivant. Cela simplifie grandement la maintenance applicative des décompresseurs.
4. Algorithme de construction : Étape par étape
Pour construire un code de Huffman, on utilise généralement une “file de priorité”. On extrait les deux éléments les plus légers, on les combine, et on réinsère le résultat.
- Étape 1 : Calcul des fréquences.
- Étape 2 : Tri des symboles par poids croissant.
- Étape 3 : Fusion itérative jusqu’à l’obtention de la racine.
- Étape 4 : Attribution des ‘0’ pour les branches gauches et des ‘1’ pour les branches droites.
Ce processus garantit l’optimalité du code pour une distribution de fréquences donnée. Chez DATAROCKSTARS, nous simulons ces étapes pour comprendre l’efficacité algorithmique.
5. Huffman Statique vs Huffman Dynamique
Le codage de Huffman classique nécessite de connaître les fréquences à l’avance (Huffman statique), ce qui oblige à transmettre l’arbre avec le message compressé. Le Huffman Dynamique (ou adaptatif) ajuste l’arbre au fur et à mesure de la lecture des données.
En 2026, le mode dynamique est crucial pour le streaming de données en temps réel dans le Data Lake, car il permet de commencer la transmission sans avoir lu l’intégralité du fichier source.
6. Applications concrètes : ZIP, GZIP et au-delà
Où trouve-t-on le codage de Huffman aujourd’hui ? Partout. Il est souvent combiné avec d’autres algorithmes comme LZ77 (dans l’algorithme DEFLATE utilisé par GZIP et les fichiers PNG).
- Web : Accélération du chargement des pages via HTTP/2 et HPACK.
- Multimédia : Compression finale des coefficients de la transformée en cosinus discrète dans le JPEG.
Comprendre ces empilements technologiques est un aspect vital pour tout savoir sur l’ingénierie web et logicielle.
7. Performance et Limites : Quand Huffman ne suffit plus
Bien qu’optimal pour un codage symbole par symbole, Huffman a ses limites. Il ne peut pas descendre en dessous d’un bit par symbole. Si l’entropie est très faible (par exemple 0.1 bit par caractère), le codage arithmétique sera plus performant.
Toutefois, la simplicité de Huffman et sa faible consommation en ressources CPU en font le choix privilégié pour les systèmes embarqués et les Agents IA & Automations qui nécessitent une exécution ultra-rapide sur le Cloud Computing.
[Image showing performance comparison: Huffman Coding vs Arithmetic Coding for different entropy levels]
8. Implémentation en Python : Coder son propre compresseur
Le langage Python facilite grandement la manipulation de l’arbre de Huffman grâce à des structures comme heapq.
Python
import heapq
def build_huffman_tree(frequencies):
heap = [[weight, [char, ""]] for char, weight in frequencies.items()]
heapq.heapify(heap)
while len(heap) > 1:
lo = heapq.heappop(heap)
hi = heapq.heappop(heap)
# Logique de fusion ici
heapq.heappush(heap, [lo[0] + hi[0], lo[1:] + hi[1:]])
return heap[0]
Dans nos cursus chez DATAROCKSTARS, nous codons ces algorithmes de zéro pour forger une compréhension granulaire de la gestion de la mémoire.
9. Cybersécurité : Stéganographie et obfuscation
En cybersécurité, le codage de Huffman peut être détourné pour cacher des messages au sein d’autres données (stéganographie). Un arbre de Huffman légèrement modifié peut transporter des informations secrètes de manière quasi indétectable pour un œil non averti.
Pour tout savoir sur la cybersécurité des flux, il est impératif de comprendre comment les données sont empaquetées au niveau binaire pour protéger le patrimoine informationnel des entreprises.
10. Conclusion : Pourquoi maîtriser Huffman avec DATAROCKSTARS ?
Le codage de Huffman est un monument de l’informatique. En 2026, alors que nous produisons des zettaoctets de données, savoir comment ces données sont compressées et transportées est ce qui distingue un technicien d’un architecte de systèmes.
Chez DATAROCKSTARS, nous vous donnons les clés de cette maîtrise. En comprenant les algorithmes fondamentaux, vous devenez capable de concevoir des architectures plus légères, plus rapides et plus durables. Rejoindre nos cursus, c’est s’assurer une expertise qui traverse les époques, du premier bit de Huffman aux futurs processeurs quantiques, pour rester au sommet de la pyramide technologique.
Aspirez-vous à maîtriser les rouages du Big Data et à concevoir des architectures logicielles d’élite ? Notre formation Data Analyst & AI vous apprend à exploiter l’écosystème Python et le traitement intelligent des flux de données, afin de propulser votre expertise vers les frontières de l’innovation technologique moderne.
Merci pour votre lecture ! Si vous souhaitez découvrir nos prochains articles autour de la Data et de l’IA, vous pouvez nous suivre sur Facebook, LinkedIn et Twitter pour être notifié dès la publication d’un nouvel article !