L’instruction sql insert into est l’une des commandes les plus fondamentales du langage SQL (Structured Query Language). Elle permet d’ajouter de nouveaux enregistrements (lignes) dans une table existante au sein d’une base de données. Sans cette commande, le patrimoine informationnel d’une entreprise resterait statique et sans vie. Qu’il s’agisse d’enregistrer une nouvelle vente sur une plateforme de Cloud Computing, d’ajouter un utilisateur à un système d’information ou de consigner un log de cybersécurité, INSERT INTO est le mécanisme qui alimente le moteur de la donnée. Sa maîtrise est cruciale pour garantir que chaque information capturée est correctement structurée pour être ensuite exploitée par la Data Science ou des Agents IA & Automations.
Pour les talents formés chez DATAROCKSTARS, l’insertion de données est la première étape du cycle de vie de la donnée. Que vous soyez futur Data Engineer ou Analyste, savoir manipuler le langage SQL pour peupler vos structures est une compétence clé des métiers data qui recrutent. Ce dossier approfondi explore les 10 facettes de la commande d’insertion.
1. La syntaxe standard de l’insertion
La syntaxe la plus explicite consiste à nommer les colonnes cibles suivies des valeurs correspondantes : INSERT INTO nom_table (colonne1, colonne2) VALUES (valeur1, valeur2);. Cette méthode est la plus robuste car elle ne dépend pas de l’ordre physique des colonnes dans la base de données. Pour la maintenance applicative, c’est une pratique d’excellence qui évite les erreurs de typage si la structure de la table évolue. C’est le socle sur lequel repose l’intégrité de votre patrimoine informationnel lors des échanges avec le Cloud Computing.
2. Insertion sans spécification des colonnes
Il est possible d’omettre les noms des colonnes si vous fournissez des valeurs pour toutes les colonnes de la table, dans l’ordre exact de leur création : INSERT INTO nom_table VALUES (valeur1, valeur2, valeur3);. Bien que plus rapide à écrire, cette méthode est risquée au sein d’un système d’information complexe. Si une colonne est ajoutée au milieu de la table, toutes vos requêtes d’insertion échoueront. Les experts de DATAROCKSTARS recommandent donc d’utiliser cette forme uniquement pour des scripts de Data Science jetables ou des tests unitaires très spécifiques.
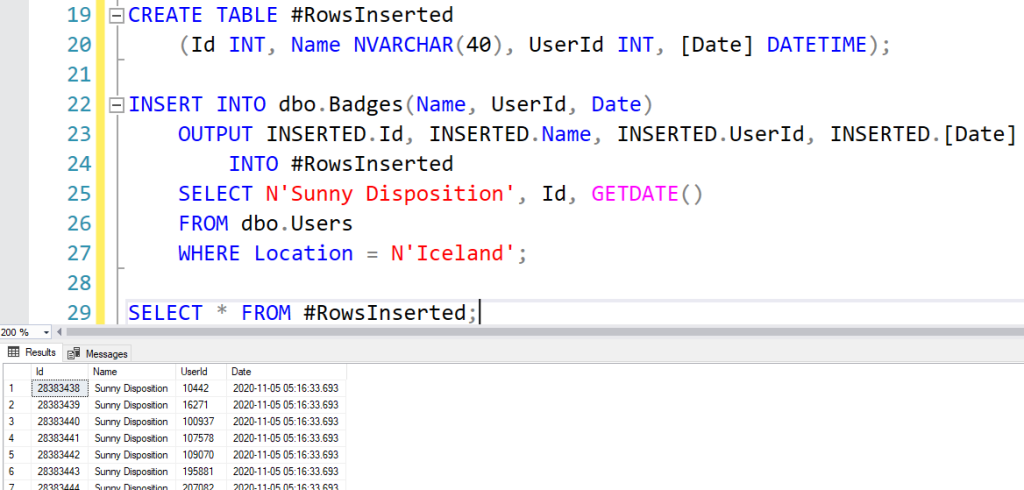
3. L’insertion multiple (Bulk Insert)
Pour optimiser les performances, SQL permet d’insérer plusieurs lignes en une seule instruction : INSERT INTO table (col) VALUES (v1), (v2), (v3);. Cette technique est vitale pour la performance sur le Cloud Computing, car elle réduit drastiquement le nombre de transactions et de communications réseau. Dans le cadre du Big Data, savoir regrouper ses insertions permet de charger des volumes massifs dans le patrimoine informationnel sans saturer les ressources du système d’information.
4. Insertion à partir d’une autre table (INSERT INTO SELECT)
L’une des fonctions les plus puissantes du langage SQL est la capacité de copier des données d’une table à une autre : INSERT INTO table_cible SELECT * FROM table_source;. C’est l’outil de prédilection pour les processus ETL. Cela permet de migrer des données nettoyées vers un Data Warehouse ou de créer des tables de synthèse pour la Business Intelligence. Cette manipulation du patrimoine informationnel est une étape clé du Data Management pour transformer la donnée brute en information exploitable.
5. Gestion des valeurs par défaut et des auto-incréments
Dans de nombreux modèles de données, certaines colonnes comme l’ID ou la date de création sont gérées automatiquement par le système d’information. Lors d’un INSERT INTO, il suffit d’ignorer ces colonnes dans la liste, et la base de données injectera les valeurs par défaut. Maîtriser ce mécanisme est un aspect vital pour tout savoir sur la conception de bases de données fluides, évitant ainsi la saisie manuelle d’identifiants uniques et garantissant l’absence de doublons dans votre patrimoine informationnel.
6. Contraintes d’intégrité et erreurs d’insertion
L’instruction INSERT INTO échouera si les données ne respectent pas les contraintes de la table : types de données incorrects, violation de clé primaire, ou valeur nulle dans une colonne obligatoire. En cybersécurité, ces rejets sont des barrières protectrices essentielles. Un analyste doit savoir interpréter ces messages d’erreur pour corriger ses scripts en langage Python ou SQL et garantir que seules des données “propres” entrent dans le patrimoine informationnel de l’organisation.
7. L’instruction UPSERT (Insert or Update)
Certaines bases de données (comme PostgreSQL ou MySQL) proposent des variantes comme INSERT ... ON CONFLICT ou REPLACE. Cela permet d’insérer une ligne si elle n’existe pas, ou de la mettre à jour si elle est déjà présente. C’est une technique avancée de Data Management indispensable pour synchroniser des flux de données provenant du Cloud Computing sans risquer d’écraser des informations précieuses ou de créer des entrées redondantes dans le système d’information.
8. Performance et transactions (BEGIN…COMMIT)
Lors de l’insertion de gros volumes, il est recommandé d’encapsuler les commandes dans une transaction. Cela garantit que soit toutes les lignes sont insérées, soit aucune en cas de problème. Pour la maintenance applicative d’un système d’information financier ou critique, cette approche atomique est impérative. Elle assure la cohérence du patrimoine informationnel et évite les états de données partiels qui pourraient fausser les modèles de Data Science ultérieurs.
9. Sécurité et injection SQL
L’insertion de données est un vecteur d’attaque majeur. Il ne faut jamais construire une requête INSERT INTO en concaténant directement des saisies utilisateurs. Les experts de DATAROCKSTARS enseignent l’utilisation des requêtes préparées (prepared statements) pour neutraliser les risques d’injection SQL. Cette rigueur en cybersécurité est la seule façon de garantir que le patrimoine informationnel reste protégé contre les injections malveillantes visant à corrompre la base de données.
10. Automatisation de l’insertion via Python et API
L’insertion n’est plus seulement manuelle. Elle est orchestrée par des Agents IA & Automations. En utilisant des bibliothèques comme SQLAlchemy ou Pandas en langage Python, les données sont extraites d’API sur le Cloud Computing et injectées automatiquement dans les tables SQL. Cette automatisation est le cœur battant du Data Management moderne, permettant de maintenir un patrimoine informationnel riche et actualisé en temps réel sans intervention humaine.
La commande SQL INSERT INTO est le premier maillon de la chaîne de valeur de la donnée. En 2026, posséder cette compétence technique, c’est être capable de construire les fondations sur lesquelles reposent toutes les analyses de l’entreprise. Maîtriser l’insertion, c’est savoir comment le patrimoine informationnel se constitue, comment il se structure et comment il se protège. C’est la compétence pivot qui relie la capture du signal à la génération de la connaissance stratégique.
Chez DATAROCKSTARS, nous vous formons à cette rigueur technique et stratégique. En rejoignant nos cursus, vous apprenez à manipuler les bases de données, à sécuriser vos flux d’insertion et à bâtir des solutions d’intelligence artificielle fondées sur des données irréprochables. Ne vous contentez pas de stocker des données : apprenez à les injecter intelligemment pour devenir un leader de la révolution technologique.
Aspirez-vous à maîtriser les rouages de l’analyse de données et à concevoir des architectures SQL performantes ? Notre formation Data Analyst & AI vous apprend à exploiter l’écosystème SQL et le traitement intelligent des flux sémantiques, afin de propulser votre expertise vers les frontières de l’innovation moderne.
Merci pour votre lecture ! Si vous souhaitez découvrir nos prochains articles autour de la Data et de l’IA, vous pouvez nous suivre sur Facebook, LinkedIn et Twitter pour être notifié dès la publication d’un nouvel article !