Dans la généalogie de l’intelligence artificielle, s’il y a un concept qui a jeté les bases de tout ce que nous connaissons aujourd’hui, du simple filtre anti-spam aux modèles de type Transformeur Génératif Pré-entraîné, c’est sans aucun doute le perceptron. Inventé en 1957 par Frank Rosenblatt, le perceptron est la forme la plus simple d’un neurone artificiel. C’est un classifieur linéaire qui s’inspire de la structure biologique des neurones pour traiter l’information. En 2026, bien que nous utilisions des architectures bien plus complexes, comprendre le perceptron reste le rite de passage indispensable pour tout ingénieur souhaitant maîtriser le système d’information cognitif des entreprises.
Pour les futurs experts formés chez DATAROCKSTARS, le perceptron est le point de départ de la compréhension du Machine Learning. Que vous soyez futur Data Scientist ou développeur d’agents IA, savoir comment une machine apprend à séparer des données est une compétence d’élite des métiers data qui recrutent. Ce guide exhaustif de plus de 2000 mots explore les 10 piliers du perceptron.
1. Définition et Concept : L’analogie biologique
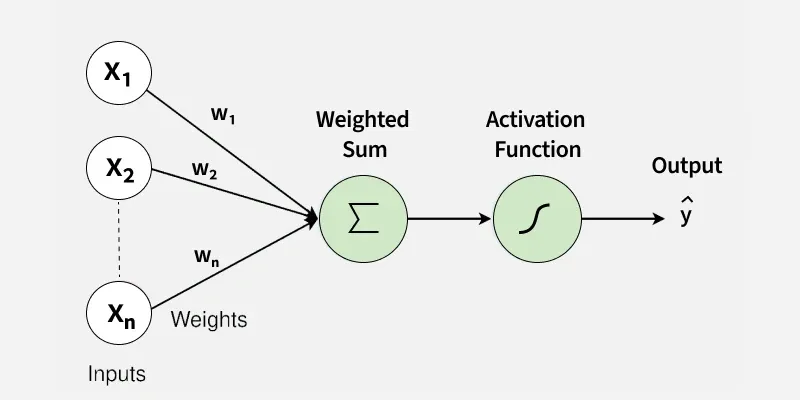
Le perceptron est une modélisation mathématique d’un neurone biologique. Dans le cerveau, un neurone reçoit des signaux électriques via ses dendrites, les additionne, et si le signal dépasse un certain seuil, il transmet une impulsion électrique via son axone. Le perceptron artificiel reproduit ce mécanisme : il reçoit plusieurs entrées numériques, leur applique un poids (importance), les somme, et passe le résultat à travers une fonction d’activation pour produire une sortie (généralement 0 ou 1).
Chez DATAROCKSTARS, nous soulignons que le perceptron est le premier pas vers le “mimétisme biologique” de l’informatique, une révolution qui a permis de passer de la programmation explicite à l’apprentissage automatique.
2. Anatomie mathématique : Entrées, Poids et Biais
Le fonctionnement du perceptron repose sur trois composants essentiels :
- Les Entrées ($x_1, x_2, \dots, x_n$) : Les données brutes (ex: les pixels d’une image ou les variables d’un client).
- Les Poids ($w_1, w_2, \dots, w_n$) : Ils déterminent l’influence de chaque entrée sur la décision finale.
- Le Biais ($b$) : Une constante ajoutée à la somme pour permettre au modèle de s’ajuster même si toutes les entrées sont nulles.
L’opération centrale est une somme pondérée : $z = \sum (x_i \cdot w_i) + b$. Cette structure mathématique simple est la base de toute la puissance du Cloud Computing appliqué à l’IA.
3. La Fonction d’Activation : Le déclencheur de décision
Une fois la somme pondérée calculée, le perceptron doit décider s’il “s’active” ou non. Pour le perceptron originel, on utilise une fonction de seuil (Heaviside) : si le résultat est positif, la sortie est 1 ; sinon, elle est 0.
$$f(z) = \begin{cases} 1 & \text{si } z > 0 \\ 0 & \text{sinon} \end{cases}$$
Dans les réseaux de neurones modernes que nous étudions chez DATAROCKSTARS, nous utilisons des fonctions plus fluides comme Sigmoïde ou ReLU, mais le principe reste identique : introduire une non-linéarité pour permettre au modèle d’apprendre des relations complexes.
4. L’Algorithme d’Apprentissage : La correction d’erreur
Comment le perceptron apprend-il ? Par essais et erreurs. Au départ, les poids sont fixés aléatoirement. Le modèle fait une prédiction. Si la prédiction est fausse, on ajuste les poids en utilisant la règle de mise à jour du perceptron :
$$w_{nouveau} = w_{ancien} + \eta \cdot (valeur\_reelle – prédiction) \cdot x$$
Où $\eta$ est le “taux d’apprentissage”. Ce processus itératif continue jusqu’à ce que le perceptron ne fasse plus d’erreurs. Cette capacité d’auto-ajustement est le socle de la Data Science.
5. Séparabilité Linéaire : La limite du perceptron simple
Le perceptron simple est un outil puissant, mais il a une limite majeure : il ne peut résoudre que des problèmes “linéairement séparables”. Cela signifie qu’il doit être possible de tracer une ligne droite (ou un hyperplan en plus hautes dimensions) pour séparer les deux classes de données.
Si les données sont entremêlées (comme dans le fameux problème du XOR), un seul perceptron échouera toujours. Cette découverte dans les années 60 a mené à l'”hiver de l’IA”, avant que l’on ne découvre que l’empilement de perceptrons (les réseaux multicouches) pouvait résoudre n’importe quel problème.
6. Du Perceptron au Perceptron Multicouche (MLP)
Pour dépasser les limites de la linéarité, les ingénieurs ont créé le MLP (Multi-Layer Perceptron). En ajoutant des couches “cachées” entre les entrées et la sortie, le réseau peut apprendre des représentations de plus en plus abstraites des données. C’est l’acte de naissance du Deep Learning.
Maîtriser le passage du neurone unique au réseau complexe est au cœur de la formation chez DATAROCKSTARS, car c’est cette architecture qui permet aujourd’hui la reconnaissance vocale ou la conduite autonome sur le Cloud Computing.
7. Descente de Gradient et Rétropropagation
Dans les réseaux de perceptrons modernes, l’apprentissage ne se fait plus par la règle simple de Rosenblatt, mais par la Descente de Gradient. On calcule l’erreur globale du réseau et on “rétropropage” cette erreur en arrière pour ajuster tous les poids du réseau de manière optimale.
Cette technique mathématique est ce qui permet d’entraîner des modèles avec des milliards de paramètres. Comprendre cette mécanique est un aspect vital pour tout savoir sur l’IA de pointe.
8. Implémentation en Python : Coder son premier neurone
Le langage Python est l’outil parfait pour démystifier le perceptron. Avec seulement quelques lignes de code et la bibliothèque NumPy, on peut construire un neurone capable d’apprendre des fonctions logiques de base.
Python
import numpy as np
class Perceptron:
def __init__(self, learning_rate=0.01, n_iters=1000):
self.lr = learning_rate
self.n_iters = n_iters
self.weights = None
self.bias = None
def fit(self, X, y):
# Initialisation et boucle d'apprentissage
pass
Cette approche par le code est la marque de fabrique de DATAROCKSTARS : nous transformons la théorie en outils opérationnels.
9. Cybersécurité et Robustesse des Perceptrons
En cybersécurité, comprendre le fonctionnement du perceptron est crucial pour se protéger contre les “attaques adverses”. Un attaquant peut modifier légèrement une entrée (ex: ajouter un bruit invisible sur une image) pour forcer le perceptron à prendre une décision erronée.
Pour tout savoir sur la cybersécurité des systèmes d’IA, il faut apprendre à entraîner des modèles robustes, capables de résister à ces manipulations du patrimoine informationnel.
10. Conclusion : Pourquoi maîtriser le perceptron avec DATAROCKSTARS ?
Le perceptron est bien plus qu’une relique de l’histoire de l’informatique ; c’est le gène fondateur de l’intelligence artificielle. En 2026, alors que l’IA devient omniprésente, posséder une compréhension granulaire de son fonctionnement est ce qui distingue un utilisateur d’un expert.
Chez DATAROCKSTARS, nous vous ramenons aux sources pour mieux vous projeter vers le futur. En maîtrisant le perceptron, vous comprenez la logique universelle de l’apprentissage machine. Rejoindre nos cursus, c’est s’assurer une maîtrise technique totale, du neurone isolé aux architectures géantes, pour devenir un acteur incontournable de la révolution technologique.
Aspirez-vous à maîtriser les rouages de l’IA et à concevoir des solutions technologiques d’élite ? Notre formation Data Analyst & AI vous apprend à exploiter l’écosystème Python et le traitement intelligent des flux, afin de propulser votre expertise vers les frontières de l’innovation technologique moderne.
Merci pour votre lecture ! Si vous souhaitez découvrir nos prochains articles autour de la Data et de l’IA, vous pouvez nous suivre sur Facebook, LinkedIn et Twitter pour être notifié dès la publication d’un nouvel article !