Dans le monde de la gestion de données, l’information est rarement stockée dans un seul bloc monolithique. Pour des raisons d’efficacité, de stockage et de cohérence (la normalisation), les données sont réparties dans plusieurs tables au sein d’une base de données relationnelle. Les jointures SQL (JOIN) sont les instructions fondamentales qui permettent de “recoudre” ces morceaux pour répondre à des questions métier complexes. Que vous souhaitiez lier un client à ses commandes, un employé à son département ou un capteur IoT à sa localisation géographique, la jointure est l’outil universel de réconciliation.
En 2026, la maîtrise des jointures est le socle de toute analyse de Data Science et de tout pipeline de Big Data. Pour les professionnels formés chez DATAROCKSTARS, savoir choisir le bon type de jointure est une compétence d’élite qui sépare les simples exécutants des architectes de données. Ce guide exhaustif de plus de 2000 mots explore les 10 piliers de la puissance des jointures en SQL.
1. Définition et Concept : Pourquoi diviser pour mieux régner ?
Le SQL repose sur le modèle relationnel. Au lieu de stocker le nom d’un client dans chaque ligne de commande (ce qui créerait des doublons et des risques d’erreurs lors d’une modification), on stocke un identifiant unique (la clé étrangère) qui pointe vers la table “Clients”.
La jointure est l’opération qui utilise cette clé commune pour fusionner temporairement les lignes de deux tables ou plus lors d’une requête SELECT. Chez DATAROCKSTARS, nous enseignons que la jointure n’est pas qu’une commande technique, c’est la traduction logique de la structure du monde réel dans un système d’information.
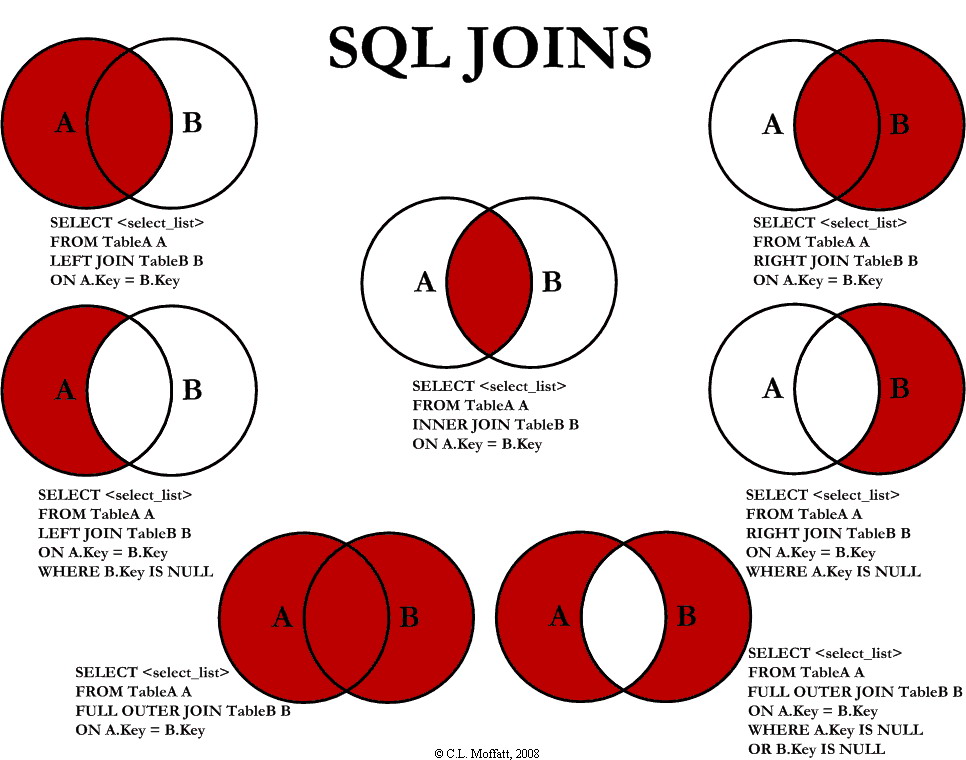
2. L’INNER JOIN : Le cœur de la précision
L’INNER JOIN (jointure interne) est la plus courante. Elle ne retourne que les lignes pour lesquelles il existe une correspondance exacte dans les deux tables. Si un client n’a jamais passé de commande, il n’apparaîtra pas dans le résultat d’un INNER JOIN entre “Clients” et “Commandes”.
C’est l’outil de précision par excellence. On l’utilise pour générer des rapports stricts où l’on ne veut voir que les relations complètes. Dans nos bootcamps, nous utilisons l’INNER JOIN pour filtrer les bruits de données et se concentrer sur les transactions validées au sein du Data Lake.
3. LEFT JOIN (ou LEFT OUTER JOIN) : Ne rien perdre en route
Le LEFT JOIN est l’un des préférés des Data Analysts. Il retourne toutes les lignes de la table de gauche (la première citée), même s’il n’y a pas de correspondance dans la table de droite. Pour les lignes sans correspondance, les colonnes de la table de droite afficheront la valeur NULL.
Exemple concret : Lister tous les produits du catalogue, y compris ceux qui n’ont jamais été vendus. C’est une technique vitale pour identifier les “stocks morts” ou les opportunités manquées. La gestion des valeurs NULL après un LEFT JOIN est un aspect fondamental de la maintenance applicative des rapports de Business Intelligence.
4. RIGHT JOIN : La symétrie de la donnée
Le RIGHT JOIN est le miroir du LEFT JOIN. Il retourne toutes les lignes de la table de droite. Bien qu’il soit techniquement identique à un LEFT JOIN dont on inverserait l’ordre des tables, il est parfois utilisé pour des raisons de lisibilité dans des requêtes complexes impliquant de nombreuses tables.
Chez DATAROCKSTARS, nous conseillons souvent de privilégier le LEFT JOIN par convention de lecture (de gauche à droite), mais comprendre le fonctionnement du RIGHT JOIN est indispensable pour auditer du code existant ou travailler sur des infrastructures de Cloud Computing partagées.
5. FULL OUTER JOIN : L’union totale
Le FULL OUTER JOIN combine les résultats du LEFT et du RIGHT JOIN. Il retourne toutes les lignes dès qu’une correspondance existe dans l’une des deux tables. C’est l’outil idéal pour les audits complets ou pour réconcilier deux systèmes différents (par exemple, fusionner les données d’un ancien CRM avec un nouveau) sans perdre aucune information.
Attention toutefois à la performance : sur des volumes de Big Data, un FULL JOIN mal indexé peut saturer les ressources de calcul. Savoir quand l’utiliser est un signe de maturité technique.
6. CROSS JOIN : Le produit cartésien
Le CROSS JOIN est particulier : il ne nécessite pas de condition de jointure (ON). Il multiplie chaque ligne de la première table par chaque ligne de la seconde. Si vous avez 10 couleurs et 10 tailles, un CROSS JOIN générera les 100 combinaisons possibles de vêtements.
Bien que dangereux s’il est utilisé par erreur (explosion du nombre de lignes), il est très utile en Data Science pour créer des grilles de test ou des référentiels complets avant d’y injecter des données réelles.
7. SELF JOIN : La table qui se regarde dans le miroir
Parfois, la relation se trouve au sein de la même table. Par exemple, dans une table “Employés”, une colonne “ID_Manager” renvoie vers l’ID d’un autre employé de la même table. Le SELF JOIN consiste à joindre une table avec elle-même en utilisant des alias (ex: FROM Employes AS E1 JOIN Employes AS E2).
C’est une technique avancée indispensable pour gérer les hiérarchies, les arbres généalogiques ou les structures de dossiers. La maîtrise des alias est ici cruciale pour éviter la confusion mentale et technique.
8. Optimisation et Performance : L’importance des Index
Une jointure sur des tables contenant des millions de lignes peut être extrêmement lente. Le secret de la performance réside dans les Index. En créant un index sur les colonnes de jointure (généralement les clés primaires et étrangères), vous permettez au moteur SQL de trouver les correspondances instantanément au lieu de scanner toute la table.
Dans notre Bootcamp Data Engineer & AIOps, nous apprenons à analyser les “Execution Plans” pour identifier les goulots d’étranglement et transformer une requête de 10 minutes en une exécution de quelques secondes sur le Cloud Computing.
9. Jointures et Cybersécurité : Attention aux fuites
Les jointures mal maîtrisées peuvent devenir des vecteurs de fuites de données. Par exemple, une jointure oubliée dans une clause WHERE pourrait afficher des informations sensibles d’un client à un autre utilisateur.
La cybersécurité des bases de données passe par l’utilisation de “Vues” sécurisées qui encapsulent les jointures complexes, limitant ainsi ce que l’utilisateur final ou l’application peut voir. Pour tout savoir sur la cybersécurité des données, il faut comprendre que la jointure est l’endroit où les permissions se croisent.
10. Conclusion : Pourquoi devenir un maître des jointures avec DATAROCKSTARS ?
Maîtriser les jointures SQL en 2026, c’est posséder la capacité d’unifier le chaos. Dans une entreprise moderne, les données sont partout : dans le CRM, dans l’ERP, dans les logs web et dans les fichiers Python. Celui qui sait joindre ces mondes est celui qui détient la vérité métier.
Chez DATAROCKSTARS, nous ne nous contentons pas de vous montrer la syntaxe. Nous vous plongeons dans des bases de données réelles et massives pour vous apprendre à réconcilier, nettoyer et transformer l’information. En maîtrisant l’art du JOIN, vous devenez le pivot central de la stratégie data, capable de transformer des tables isolées en une intelligence d’affaires surpuissante.
Aspirez-vous à maîtriser les rouages du Big Data et à concevoir des requêtes de données ultra-performantes ? Notre formation Data Analyst & AI vous apprend à exploiter l’écosystème SQL et le traitement intelligent des flux, afin de propulser votre expertise vers les frontières de l’innovation technologique moderne.
Merci pour votre lecture ! Si vous souhaitez découvrir nos prochains articles autour de la Data et de l’IA, vous pouvez nous suivre sur Facebook, LinkedIn et Twitter pour être notifié dès la publication d’un nouvel article !