Dans l’univers de l’intelligence artificielle en 2026, l’entraînement d’un modèle n’est que la moitié du chemin ; l’autre moitié consiste à mesurer sa fiabilité réelle. La matrice de confusion est l’outil de diagnostic fondamental utilisé pour évaluer les performances d’un algorithme de classification. Elle permet de visualiser de manière croisée les prédictions d’un modèle par rapport aux étiquettes réelles du patrimoine informationnel. Qu’il s’agisse de détecter une intrusion en cybersécurité, de diagnostiquer une maladie ou de filtrer des spams, la matrice de confusion révèle non seulement si le modèle se trompe, mais surtout comment il se trompe. C’est l’instrument qui permet d’ajuster la précision et le rappel au sein du système d’information pour garantir une aide à la décision optimale sur le Cloud Computing.
Pour les talents formés chez DATAROCKSTARS, la lecture d’une matrice de confusion est une compétence de survie. Que vous soyez futur Data Scientist ou Analyste, savoir interpréter ces résultats est une compétence clé des métiers data qui recrutent. Ce dossier approfondi explore les 10 dimensions de la matrice de confusion en 10 pavés détaillés, sans aucune ligne de séparation.
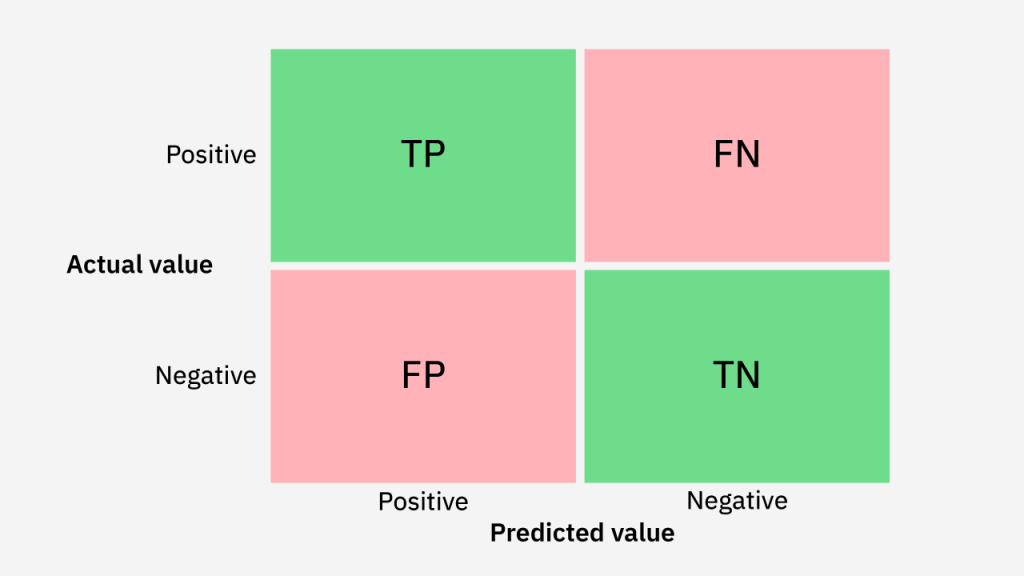
1. La structure fondamentale : Les quatre quadrants
La matrice de confusion pour une classification binaire se présente sous la forme d’un tableau $2 \times 2$. Elle se compose de quatre indicateurs clés : les Vrais Positifs (TP), les Vrais Négatifs (TN), les Faux Positifs (FP) et les Faux Négatifs (FN). Les Vrais Positifs représentent les cas où le modèle a correctement prédit la classe positive (ex: une fraude détectée). Les Vrais Négatifs sont les cas correctement prédits comme négatifs. En revanche, les Faux Positifs (alarmes inutiles) et les Faux Négatifs (manqués critiques) sont les zones de “confusion” qui donnent son nom à la matrice. Cette structure simple est un aspect vital pour tout savoir sur la validation des modèles de Data Science, car elle décompose l’erreur globale en catégories actionnables pour le patrimoine informationnel.
2. L’erreur de Type I : Le Faux Positif (Fausse Alerte)
Le Faux Positif, ou erreur de Type I, survient lorsque le modèle prédit un événement qui n’a pas eu lieu. Dans un contexte de cybersécurité, cela correspondrait à bloquer un utilisateur légitime en le prenant pour un pirate. Bien que moins grave qu’une intrusion réussie, une accumulation de Faux Positifs sature les équipes de maintenance applicative et dégrade l’expérience utilisateur au sein du système d’information. Chez DATAROCKSTARS, nous apprenons à nos étudiants à minimiser ce bruit pour optimiser les ressources sur le Cloud Computing et préserver la fluidité opérationnelle du patrimoine informationnel de l’entreprise.
3. L’erreur de Type II : Le Faux Négatif (Le danger invisible)
Le Faux Négatif, ou erreur de Type II, est souvent le cauchemar du Data Scientist. Il se produit lorsque le modèle ne détecte pas un événement réel (ex: un cancer non diagnostiqué ou une faille de sécurité ignorée). Dans le cadre du Data Management, le coût d’un Faux Négatif est généralement bien plus élevé que celui d’un Faux Positif. Maîtriser la matrice de confusion permet d’identifier cette faiblesse et de choisir des algorithmes plus “sensibles” pour protéger les actifs critiques du système d’information. C’est une dimension éthique et sécuritaire majeure de l’intelligence artificielle en 2026.
4. L’Accuracy (Précision Globale) : Un indicateur trompeur
L’Accuracy est le rapport entre les bonnes prédictions (TP + TN) et le total des cas. Si elle est l’indicateur le plus simple à comprendre, elle peut être extrêmement trompeuse, surtout face à des classes déséquilibrées. Par exemple, si 99% de vos transactions sont honnêtes, un modèle qui prédit “toujours honnête” aura 99% d’Accuracy mais sera totalement inutile pour détecter les fraudes. La matrice de confusion met en lumière ce paradoxe en montrant que les 1% de fraudes (FN) n’ont jamais été détectés. C’est pourquoi, en Data Science, on ne se fie jamais à l’Accuracy seule pour évaluer la santé du patrimoine informationnel.
5. La Precision (Justesse des prédictions positives)
La Precision répond à la question : “Sur toutes les prédictions positives du modèle, combien étaient réellement correctes ?”. Elle se calcule par la formule $TP / (TP + FP)$. Une haute Precision signifie que lorsque l’algorithme tire la sonnette d’alarme, il y a de fortes chances qu’il ait raison. C’est un indicateur clé pour les Agents IA & Automations qui déclenchent des actions coûteuses ou irréversibles. Maximiser la Precision permet de renforcer la confiance des utilisateurs dans le système d’information et de limiter les interventions manuelles inutiles sur le Cloud Computing.
6. Le Recall ou Sensibilité (Capacité de détection)
Le Recall (ou Rappel) mesure la capacité du modèle à trouver tous les cas positifs : $TP / (TP + FN)$. Il répond à la question : “Sur tous les cas positifs réels, combien le modèle a-t-il réussi à en capturer ?”. En cybersécurité ou en médecine, le Recall est souvent prioritaire sur la Precision. On préfère accepter quelques fausses alertes (Faux Positifs) plutôt que de rater une menace réelle (Faux Négatifs). Comprendre ce compromis au sein de la matrice de confusion est le cœur de la stratégie de Data Management pour sécuriser efficacement le patrimoine informationnel.
7. Le F1-Score : L’équilibre parfait
Le F1-Score est la moyenne harmonique de la Precision et du Recall. Il offre un indicateur unique qui pénalise les valeurs extrêmes. Si l’un des deux indicateurs est très bas, le F1-Score le sera aussi. En 2026, c’est l’un des métriques les plus utilisés pour comparer des modèles de langage Python complexes. Il permet de s’assurer que l’intelligence artificielle ne sacrifie pas la détection au profit de la justesse, ou inversement. C’est le baromètre de la performance équilibrée pour tout système d’information piloté par les données.
8. La spécificité : La performance sur les négatifs
Souvent oubliée, la spécificité mesure la capacité du modèle à détecter les cas négatifs : $TN / (TN + FP)$. C’est le “Recall du négatif”. Dans le domaine du filtrage de contenu ou de la maintenance applicative, une haute spécificité garantit que le système ne bloque pas par erreur des processus sains. La matrice de confusion permet de visualiser cet équilibre, assurant que l’automatisation par les Agents IA & Automations ne devienne pas un obstacle à la productivité sur le Cloud Computing.
9. Matrice de confusion multiclasse
Si le cas binaire est le plus simple, la matrice peut s’étendre à $N$ classes (ex: classifier des types d’animaux ou des catégories de produits). Dans ce cas, la diagonale principale de la matrice représente toutes les prédictions correctes. Toutes les valeurs en dehors de cette diagonale indiquent des erreurs de confusion entre des catégories spécifiques. Cette vision macroscopique est un aspect vital pour tout savoir sur la classification complexe. Elle permet aux Data Engineers de comprendre si le modèle confond deux classes proches, guidant ainsi l’amélioration du patrimoine informationnel via le Feature Engineering en langage Python.
10. La courbe ROC et l’AUC : Au-delà de la matrice fixe
La matrice de confusion dépend d’un “seuil de classification” (souvent 0.5). En changeant ce seuil, les valeurs de la matrice changent. La courbe ROC (Receiver Operating Characteristic) trace l’évolution du taux de Vrais Positifs par rapport au taux de Faux Positifs pour tous les seuils possibles. L’AUC (Area Under the Curve) résume cette performance globale en un seul chiffre. En 2026, maîtriser ces concepts issus de la matrice de confusion est indispensable pour déployer des modèles d’intelligence artificielle robustes et adaptables aux conditions changeantes du Cloud Computing et du système d’information.
Conclusion : Pourquoi maîtriser la matrice de confusion avec DATAROCKSTARS ?
La matrice de confusion est le stéthoscope de la donnée. En 2026, savoir lire entre ses quadrants, c’est être capable de diagnostiquer la santé d’une IA et de garantir que la technologie sert réellement les intérêts de l’entreprise sans créer de risques cachés. Maîtriser cet outil, c’est passer d’une approche “boîte noire” à une gestion transparente et responsable du patrimoine informationnel.
Chez DATAROCKSTARS, nous vous formons à cette rigueur analytique. En rejoignant nos cursus, vous apprenez à construire, évaluer et optimiser des modèles d’intelligence artificielle avec une précision chirurgicale. Ne vous laissez pas tromper par des chiffres globaux : apprenez à disséquer l’erreur pour devenir un leader de la révolution technologique.
Aspirez-vous à maîtriser les rouages des modèles de langage et à concevoir des solutions d’IA ultra-performantes ? Notre formation Data Scientist & AI Engineer vous apprend à exploiter l’écosystème Python et le traitement intelligent des flux sémantiques, afin de propulser votre expertise vers les frontières de l’innovation moderne.
Merci pour votre lecture ! Si vous souhaitez découvrir nos prochains articles autour de la Data et de l’IA, vous pouvez nous suivre sur Facebook, LinkedIn et Twitter pour être notifié dès la publication d’un nouvel article !