Les grands modèles de langage (LLM) possèdent une intelligence linguistique exceptionnelle, mais ils souffrent de deux limites majeures en entreprise : ils n’ont pas accès à vos données internes confidentielles et ils peuvent halluciner (inventer des réponses erronées avec beaucoup d’assurance). Le RAG (Retrieval-Augmented Generation, ou Génération Augmentée par Récupération) est l’architecture technique qui résout ce problème. Au lieu de réentraîner le modèle, le RAG va chercher les informations exactes dans vos documents d’entreprise et les fournit au LLM pour qu’il rédige une réponse ultra-précise et sourcée.
Chez DATAROCKSTARS, nous considérons le RAG comme la compétence d’ingénierie IA la plus demandée du marché. C’est l’outil qui transforme une intelligence artificielle générale en un expert surpuissant de votre catalogue produit, de vos contrats juridiques ou de vos procédures RH.
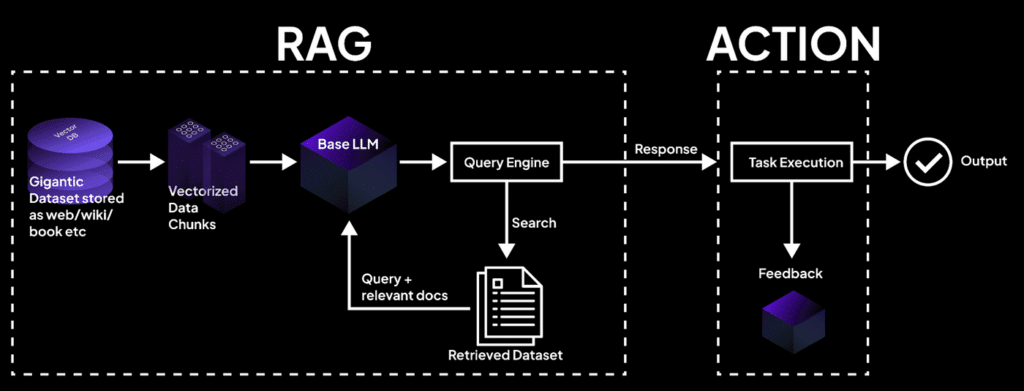
1. Le fonctionnement d’un pipeline RAG
Un système RAG fonctionne comme un examen à livre ouvert pour le LLM. Le processus se divise en deux phases distinctes : l’ingestion des données (hors ligne) et la génération de la réponse (en temps réel).
Phase 1 : L’ingestion et l’indexation des connaissances
- Le Chunking : Vos documents internes (PDF, wikis, bases de données) sont découpés en petits morceaux textuels logiques appelés chunks.
- L’Embedding : Chaque morceau est traduit en une suite de nombres (un vecteur numérique) par un modèle d’embedding. Ce vecteur capture le sens sémantique profond du texte.
- Le Stockage : Ces vecteurs sont sauvegardés dans une base de données vectorielle (comme Pinecone, Qdrant ou Milvus), qui agit comme un index sémantique ultra-rapide.
Phase 2 : La récupération et la génération (En temps réel)
- La Requête : L’utilisateur pose une question (ex: “Quelle est notre politique de télétravail ?”). Cette question est elle aussi convertie en vecteur sémantique.
- La Récupération (Retrieval) : Le système interroge la base vectorielle pour trouver les morceaux de documents dont le sens est le plus proche de la question.
- L’Augmentation : Le système construit un prompt enrichi : il prend la question d’origine et y injecte les morceaux de documents récupérés en guise de contexte.
- La Génération : Le LLM lit le prompt augmenté et rédige une réponse naturelle, fiable et entièrement basée sur les documents fournis, en éliminant tout risque d’hallucination.
2. Pourquoi le RAG est-il préféré au Fine-Tuning ?
Lorsqu’il s’agit de spécialiser une IA sur des données d’entreprise, deux approches s’affrontent. Le RAG s’impose généralement pour des raisons de coût et de flexibilité :
- Le Fine-Tuning (Ajustement fin) : Consiste à réentraîner les poids du LLM. C’est un processus lourd, coûteux en serveurs GPU, et les données intégrées sont figées à l’instant T. De plus, le modèle peut toujours halluciner sur des détails précis.
- Le RAG (Recherche augmentée) : Le modèle reste fixe. Mettre à jour les connaissances du système prend quelques secondes : il suffit d’ajouter ou de supprimer un document dans la base vectorielle. C’est l’approche idéale pour les données dynamiques (prix, stocks, réglementations).
3. Les composants de la “Stack” RAG
Pour bâtir une infrastructure RAG robuste et scalable, un ingénieur IA doit orchestrer plusieurs briques technologiques :
- L’orchestrateur (Framework) : Le framework qui crée les liens logiques entre les données, les bases et les modèles. LangChain et LlamaIndex sont les leaders historiques, mais l’utilisation de frameworks programmatiques comme DSPy s’impose pour optimiser automatiquement les invites (prompts).
- La base de données vectorielle : Conçue spécifiquement pour la recherche de similarité à grande échelle (ex: Chroma, Pgvector, Pinecone).
- Les modèles (Embeddings et LLM) : Un premier modèle léger pour vectoriser le texte (ex: Cohere, OpenAI embeddings) et un LLM performant pour la rédaction finale (ex: GPT-4o, Claude 3.5 Sonnet ou Llama 3).
4. Les techniques de RAG Avancé pour la production
Un RAG basique montre vite ses limites face à des documents complexes (tableaux, structures financières). Pour atteindre un niveau industriel, les équipes déploient des stratégies avancées :
[Image showing advanced RAG techniques including query rewriting reranking and parent child chunking]
• Le Reranking (Réévaluation) : Le moteur de recherche récupère par exemple les 25 documents les plus proches sémantiquement. Un modèle spécialisé de Reranking les réanalyse pour ne transmettre au LLM que les 3 ou 4 morceaux les plus pertinents. Cela permet de réduire la confusion de l’IA et d’optimiser les coûts de consommation de jetons (tokens).
• Le Parent-Child Chunking : Lors de la recherche, le système cible de très petits morceaux de texte (très précis pour la correspondance vectorielle). En revanche, au moment d’envoyer l’information au LLM, il lui transmet le paragraphe entier ou la page complète (le “parent”) pour lui donner tout le contexte nécessaire à une bonne rédaction.
• La reformulation de requête (Query Rewriting) : Les utilisateurs posent parfois des questions floues. Le système utilise un LLM léger en amont pour réécrire la question sous différentes formulations afin de maximiser les chances de trouver la bonne information dans la base de données.
5. Comment évaluer la performance d’un système RAG ?
Contrairement aux logiciels classiques, évaluer un système d’IA générative est complexe. On utilise le framework de la RAG Triad pour mesurer mathématiquement trois scores clés via des outils comme Ragas ou TruLens :
- La pertinence du contexte (Context Relevance) : Le moteur de recherche a-t-il extrait les bons documents par rapport à la question posée ?
- La fidélité (Groundedness) : La réponse finale du LLM est-elle strictement issue du contexte fourni, ou l’IA a-t-elle inventé des faits ?
- La pertinence de la réponse (Answer Relevance) : Le texte généré répond-il directement et de manière utile à la problématique de l’utilisateur ?
6. Pourquoi se former au RAG avec DATAROCKSTARS
Le déploiement d’architectures RAG est aujourd’hui le cas d’usage concret le plus recherché par les entreprises qui adoptent l’intelligence artificielle. Savoir manipuler des bases vectorielles, optimiser le traitement des données brutes (data parsing) et sécuriser les accès aux documents confidentiels sont des compétences hautement valorisées sur le marché du travail.
Chez DATAROCKSTARS, nos cursus intensifs vous préparent à concevoir et industrialiser ces systèmes de bout en bout. Nous vous apprenons à dépasser les prototypes pour créer des applications IA prêtes pour la production et optimisées pour le cloud. Prêt à donner une mémoire infaillible aux modèles de langage ? Souhaitez-vous découvrir comment notre Bootcamp Data Scientist & AI Engineer peut vous aider à maîtriser l’architecture RAG et à propulser votre carrière au sommet de la tech ?
Merci pour votre lecture ! Si vous souhaitez découvrir nos prochains articles autour de la Data et de l’IA, vous pouvez nous suivre sur Facebook, LinkedIn et Twitter pour être notifié dès la publication d’un nouvel article !