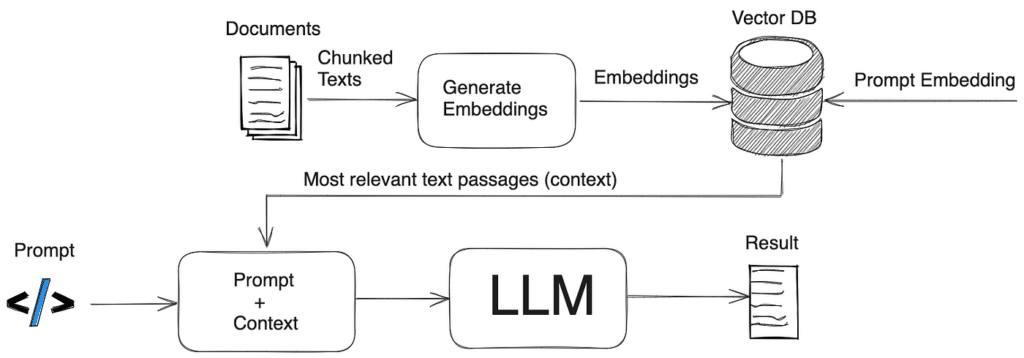
Les grands modèles de langage (LLM) comme GPT-4, Claude ou Llama sont incroyablement intelligents, mais ils souffrent de deux limites majeures : ils ne connaissent pas vos données d’entreprise internes et ils peuvent halluciner (inventer des faits crédibles mais faux). Le RAG (Génération Augmentée par Récupération) est l’architecture technique qui résout définitivement ce problème. Au lieu de réentraîner un modèle de zéro, le RAG va chercher les informations pertinentes dans vos documents internes et les fournit au LLM pour qu’il rédige une réponse ultra-précise et sourcée.
Chez DATAROCKSTARS, nous considérons le RAG comme l’architecture la plus demandée et la plus rentable du marché de l’IA en 2026. C’est l’outil qui transforme un modèle de langage généraliste en un expert surpuissant de votre catalogue produit, de vos procédures RH ou de votre documentation technique.
1. Comment fonctionne un pipeline RAG ?
Un système RAG se décompose en deux phases principales : la préparation des données (hors ligne) et l’exécution de la requête (en temps réel).
Étape 1 : L’ingestion et l’indexation (Le “Chunking”)
Vos documents de base (PDF, Word, Notion, bases de données) sont découpés en petits morceaux textuels appelés chunks. Ces morceaux sont ensuite traduits en vecteurs numériques grâce à un modèle d’Embedding. Ces vecteurs, qui capturent le sens sémantique du texte, sont stockés dans une base de données vectorielle (comme Pinecone, Chroma ou Milvus).
Étape 2 : La récupération (Retrieval)
Lorsqu’un utilisateur pose une question, sa requête est elle aussi transformée en vecteur. Le système interroge la base de données vectorielle pour trouver les $K$ morceaux de documents qui ressemblent le plus sémantiquement à la question.
Étape 3 : La génération (Generation)
Le système prend la question d’origine, y ajoute les morceaux de documents récupérés (le contexte), et envoie le tout au LLM avec une consigne claire : “Réponds à la question en utilisant uniquement les informations fournies”.
2. RAG vs Fine-Tuning : Quelle différence ?
Il est fréquent de confondre le RAG et le Fine-Tuning (ajustement fin). Voici comment choisir la bonne approche :
- Fine-Tuning : C’est comme envoyer le LLM faire de longues études pour apprendre un nouveau métier ou un style d’écriture. C’est coûteux, long, et le modèle peut finir par oublier d’anciennes connaissances ou continuer à halluciner sur les faits précis.
- RAG : C’est comme donner au LLM un examen à livre ouvert avec toute la documentation sous les yeux. C’est instantané, peu coûteux, et parfait pour des données qui changent souvent (comme des prix ou des stocks).
En entreprise, le RAG est plébiscité pour sa flexibilité et la traçabilité des réponses : le modèle peut citer exactement la ligne du PDF d’où provient l’information.
3. Les composants clés d’une infrastructure RAG
Pour bâtir un RAG de niveau industriel, vous devez orchestrer plusieurs briques technologiques :
| Composant | Rôle | Technologies populaires |
| Orchestrateur | Fait le lien entre le code, la base et le LLM | LangChain, LlamaIndex, DSPy |
| Base Vectorielle | Stocke et cherche les vecteurs sémantiques | Pinecone, Qdrant, PGVector, Milvus |
| Modèle d’Embedding | Transforme le texte en coordonnées mathématiques | OpenAI text-embedding-3, Cohere, Hugging Face |
| LLM Générateur | Rédige la réponse finale de manière fluide | GPT-4o, Claude 3.5 Sonnet, Llama 3 |
Chez DATAROCKSTARS, nous mettons un accent particulier sur l’utilisation de DSPy pour remplacer les prompts manuels par une optimisation algorithmique de vos pipelines RAG.
4. Les techniques avancées pour optimiser un RAG
Un RAG basique (Naïve RAG) montre vite ses limites sur des questions complexes. En production, nos ingénieurs mettent en place des stratégies avancées :
• Le Reranking (Réévaluation) : Après avoir récupéré les 20 meilleurs documents, un modèle spécialisé (comme Cohere Rerank) les réanalyse pour ne garder que les 3 ou 4 les plus pertinents avant de les donner au LLM. Cela réduit la confusion du modèle et optimise les coûts de jetons (tokens).
• Le Query Rewriting : Souvent, l’utilisateur pose une question mal formulée. Le système utilise un premier LLM léger pour reformuler la question sous plusieurs angles afin d’optimiser la recherche dans la base vectorielle.
• Le Parent-Child Chunking : Chercher des petits morceaux de texte (précis pour la recherche vectorielle) mais envoyer au LLM le paragraphe entier qui l’entoure (riche en contexte pour la rédaction).
[Image showing advanced RAG techniques including query rewriting reranking and parent child chunking]
5. Le défi de l’évaluation : Métriques RAG Triad
Comment savoir si votre système RAG s’améliore lorsque vous modifiez un paramètre ? On utilise le framework de la RAG Triad pour évaluer scientifiquement trois aspects :
- Context Relevance (La pertinence du contexte) : Le moteur de recherche a-t-il récupéré les bons documents pour répondre à la question ?
- Groundedness (La fidélité) : La réponse du LLM est-elle strictement basée sur le contexte fourni, ou a-t-il commencé à halluciner ?
- Answer Relevance (La pertinence de la réponse) : La réponse finale répond-elle directement et efficacement à la question de l’utilisateur ?
Maîtriser ces outils d’évaluation (comme Ragas ou TruLens) est ce qui distingue un développeur amateur d’un ingénieur IA d’élite.
6. Pourquoi se former aux architectures RAG avec DATAROCKSTARS
Le déploiement de systèmes RAG est la compétence la plus recherchée par les directions techniques des entreprises. Savoir manipuler des bases vectorielles, optimiser le découpage des documents (chunking) et sécuriser les accès aux données confidentielles vous garantit une employabilité maximale.
Chez DATAROCKSTARS, nous vous formons à l’état de l’art du domaine. Nos bootcamps intensifs vous plongent dans la création de pipelines RAG de bout en bout, prêts pour la production et optimisés pour le cloud. Prêt à donner de la mémoire à vos intelligences artificielles ? Souhaitez-vous découvrir comment notre Bootcamp Data Scientist & AI Engineer peut vous aider à dompter l’architecture RAG et à propulser votre carrière au sommet de la tech ?
Quel type de documents souhaitez-vous connecter à votre LLM pour votre projet de RAG : des rapports textuels (PDF, Word) ou des données structurées issues de bases SQL ?
Merci pour votre lecture ! Si vous souhaitez découvrir nos prochains articles autour de la Data et de l’IA, vous pouvez nous suivre sur Facebook, LinkedIn et Twitter pour être notifié dès la publication d’un nouvel article !