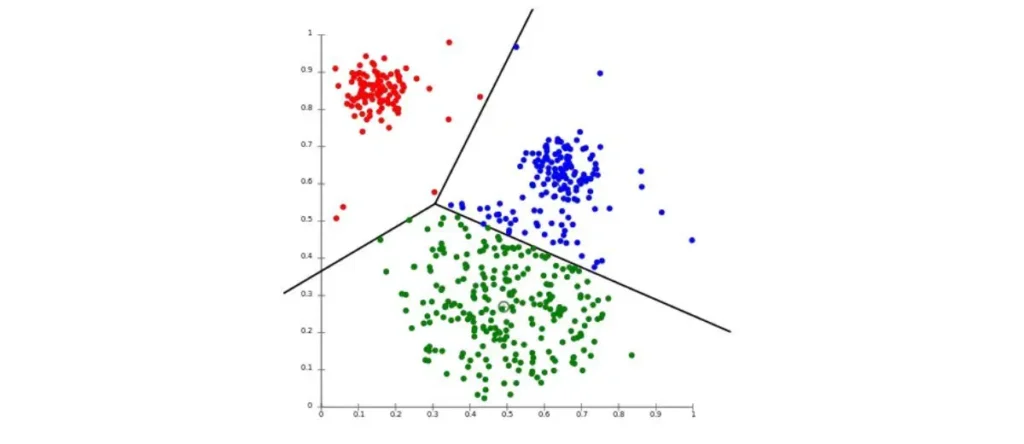
Dans le vaste arsenal du Machine Learning, le K-Means occupe une place de choix. C’est l’algorithme de référence pour l’apprentissage non supervisé (unsupervised learning). Son rôle est de regrouper des données non étiquetées en “clusters” (groupes) homogènes. Imaginez que vous ayez une base de données de milliers de clients sans savoir comment les catégoriser ; le K-Means va analyser leurs comportements et créer lui-même des groupes de profils similaires.
Chez DATAROCKSTARS, nous enseignons que le K-Means est l’outil de base pour toute stratégie de personnalisation. Que ce soit pour la segmentation marketing, la compression d’images ou la détection d’anomalies, cet algorithme transforme le chaos de données disparates en structures organisées et exploitables. Maîtriser le K-Means, c’est apprendre à découvrir les motifs cachés dans vos données sans avoir besoin de guide préalable.
1. Le concept fondamental du Clustering
Le clustering consiste à diviser un ensemble de points en plusieurs groupes de telle sorte que :
• La similarité intra-classe soit maximale : Les points d’un même groupe se ressemblent le plus possible.
• La similarité inter-classe soit minimale : Les groupes soient les plus distincts possible les uns des autres.
Le K-Means réalise cela en minimisant la distance entre les points de données et le centre de leur groupe respectif, appelé le centroïde. C’est une approche géométrique de la donnée qui nécessite souvent de normaliser les variables pour que chacune ait le même poids dans le calcul.
2. Le fonctionnement itératif de l’algorithme
Le K-Means suit un processus simple mais redoutablement efficace en quatre étapes principales :
Initialisation : L’algorithme choisit au hasard $K$ points qui serviront de centroïdes initiaux.
Assignation : Chaque point de donnée est rattaché au centroïde dont il est le plus proche (généralement en utilisant la distance euclidienne).
Mise à jour : Pour chaque groupe formé, on calcule la position moyenne de tous les points. Ce nouveau point devient le nouveau centroïde.
Répétition : On répète les étapes 2 et 3 jusqu’à ce que les centroïdes ne bougent plus ou qu’un nombre maximal d’itérations soit atteint.
Dans notre Bootcamp Data Scientist & AI Engineer, nous décomposons cette logique pour comprendre comment l’algorithme converge mathématiquement vers une solution stable.
3. Le défi du choix de “K” : La méthode du coude (Elbow Method)
L’un des plus grands défis avec le K-Means est que vous devez lui indiquer à l’avance le nombre de groupes ($K$) que vous souhaitez créer. Mais comment savoir si vos clients se divisent en 3, 5 ou 10 segments ?
La technique la plus utilisée est la méthode du coude (Elbow Method). On lance l’algorithme pour différentes valeurs de $K$ et on calcule l’inertie (la somme des carrés des distances). On trace ensuite une courbe : le point où la diminution de l’inertie ralentit brusquement (formant un “coude”) indique souvent le nombre optimal de clusters.
Savoir interpréter ce graphique est une compétence clé du Data Analyst. Chez DATAROCKSTARS, nous vous apprenons à valider ce choix avec d’autres métriques comme le score de Silhouette.
4. L’importance de l’initialisation et le K-Means++
Puisque les centroïdes de départ sont choisis au hasard, le résultat final peut varier d’une exécution à l’autre. Parfois, un mauvais tirage initial peut mener à un résultat médiocre.
Pour pallier ce problème, on utilise souvent K-Means++. Cet algorithme d’initialisation intelligent choisit des centroïdes qui sont initialement éloignés les uns des autres, ce qui accélère la convergence et garantit des résultats plus robustes. C’est le standard utilisé par défaut dans les bibliothèques comme Scikit-Learn, un outil que nous maîtrisons de bout en bout dans nos formations.
5. La sensibilité aux valeurs aberrantes (Outliers)
Le K-Means est très sensible aux valeurs extrêmes. Comme il calcule des moyennes pour déplacer ses centroïdes, un seul point situé très loin du reste du groupe peut “tirer” le centroïde vers lui et fausser toute la segmentation.
C’est pourquoi, chez DATAROCKSTARS, nous insistons sur la phase de Data Cleaning avant de lancer un clustering. Identifier et traiter les outliers est indispensable pour obtenir des groupes qui font sens pour le business.
6. Mise à l’échelle des données (Feature Scaling)
Le K-Means repose sur des distances géométriques. Si vous avez une variable “Âge” (de 0 à 100) et une variable “Salaire Annuel” (de 0 à 100 000), le salaire va totalement dominer le calcul de distance.
Il est donc impératif de normaliser ou de standardiser vos données avant l’analyse. Dans nos bootcamps, nous vous apprenons à utiliser des outils comme le StandardScaler pour que chaque caractéristique contribue équitablement à la forme des clusters.
7. Cas d’usage : Segmentation client (RFM)
L’application reine du K-Means en entreprise est la segmentation client via le modèle RFM (Récence, Fréquence, Montant). En appliquant le K-Means sur ces trois variables, vous pouvez identifier automatiquement vos “Champions”, vos “Clients à risque” ou vos “Nouveaux clients”.
Cette approche permet de personnaliser les campagnes marketing et d’optimiser le budget publicitaire. Chez DATAROCKSTARS, nous réalisons des projets concrets sur ce thème pour vous préparer aux réalités du métier de consultant data.
8. Les limites du K-Means : Formes et Densités
Le K-Means part du postulat que les clusters sont de forme sphérique et de tailles similaires. Il échoue souvent face à :
• Des formes complexes : Comme des croissants ou des cercles concentriques.
• Des densités variables : Des groupes très denses à côté de groupes très étalés.
Dans ces cas, nos experts vous apprennent à utiliser des alternatives comme DBSCAN ou les Modèles de Mélange Gaussien (GMM). Savoir quand ne PAS utiliser le K-Means est aussi important que de savoir s’en servir.
9. Implémentation rapide avec Python
Grâce à Python et Scikit-Learn, lancer un K-Means est devenu extrêmement simple.
Python
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=3, init='k-means++', random_state=42)
clusters = kmeans.fit_predict(data_scaled)
Mais la vraie valeur d’un expert DATAROCKSTARS ne réside pas dans l’écriture de ces trois lignes, mais dans la capacité à préparer les données en amont et à interpréter les résultats pour en tirer des recommandations stratégiques.
10. Pourquoi maîtriser le K-Means avec DATAROCKSTARS
Le K-Means est souvent la première porte d’entrée vers l’IA pour beaucoup d’entreprises car il apporte des réponses visuelles et immédiates à des problèmes complexes. Maîtriser cet algorithme vous donne une crédibilité immédiate auprès des directions marketing et produit.
Chez DATAROCKSTARS, nous transformons la théorie mathématique en expertise terrain. Prêt à segmenter le monde qui vous entoure ? Souhaitez-vous découvrir comment notre Bootcamp Data Scientist & AI Engineer peut vous aider à maîtriser le K-Means et à devenir un pilier de la stratégie data de votre entreprise ?
Merci pour votre lecture ! Si vous souhaitez découvrir nos prochains articles autour de la Data et de l’IA, vous pouvez nous suivre sur Facebook, LinkedIn et Twitter pour être notifié dès la publication d’un nouvel article !