Méta-description : La méthodologie Kimball est l’approche de référence pour la modélisation dimensionnelle en Data Warehousing. Apprenez à structurer vos données pour l’analyse décisionnelle avec l’expertise de DATAROCKSTARS.
La Méthodologie Kimball : Le pilier du Data Warehousing moderne
Dans l’univers de la Business Intelligence, le nom de Ralph Kimball est synonyme de révolution. Sa méthodologie, centrée sur la modélisation dimensionnelle, a transformé la manière dont les entreprises structurent leurs données pour la prise de décision. Contrairement aux approches purement normalisées, la méthode Kimball privilégie la facilité d’utilisation par les utilisateurs métier et la performance des requêtes analytiques.
Chez DATAROCKSTARS, nous enseignons que maîtriser Kimball est indispensable pour tout Data Analyst ou Data Engineer. C’est la différence entre une base de données illisible et un système d’information où chaque manager peut trouver ses réponses en quelques clics. Comprendre Kimball, c’est apprendre à traduire le langage du business en structures de données performantes.
1. L’approche Bottom-Up de Kimball
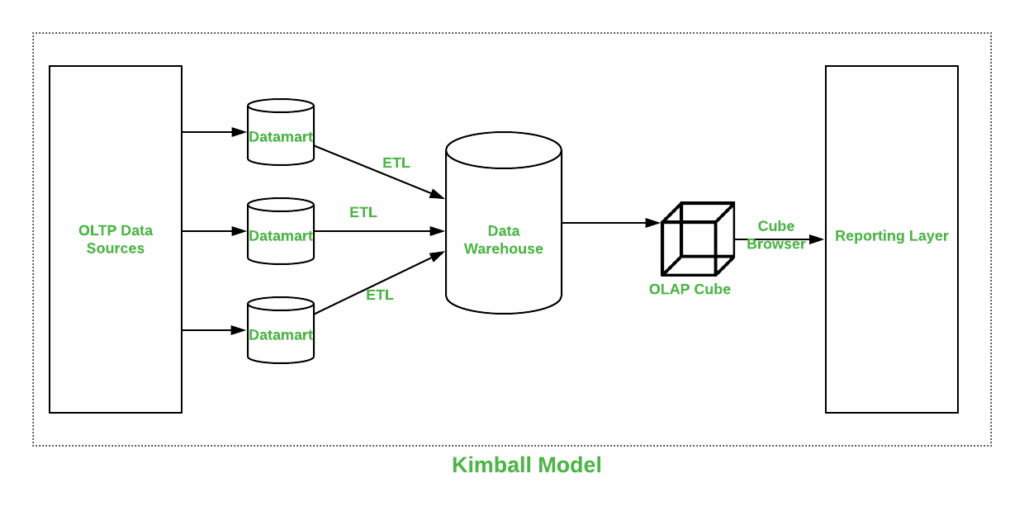
La philosophie de Ralph Kimball repose sur une approche “ascendante” (Bottom-Up). Au lieu de construire un immense entrepôt de données centralisé et complexe dès le départ, Kimball préconise la création de Data Marts (magasins de données) par département ou par processus métier (ventes, stocks, RH). Ces Data Marts sont ensuite reliés entre eux par une architecture de “dimensions conformes”. Cette méthode permet de livrer de la valeur rapidement aux métiers sans attendre des années pour la finalisation d’un projet global. C’est cette agilité que nous prônons dans nos formations, car elle permet de s’adapter aux besoins changeants de l’entreprise.
2. Le Modèle en Étoile (Star Schema)
Le concept central de la méthodologie Kimball est le modèle en étoile. Cette structure organise les données en deux types de tables :
• Les tables de Faits (Fact Tables) : Elles contiennent les mesures quantitatives (montants, quantités, durées) associées à un processus métier.
• Les tables de Dimensions (Dimension Tables) : Elles contiennent le contexte des faits (Qui ? Quoi ? Où ? Quand ?).
Le modèle en étoile simplifie les jointures SQL et optimise la lecture des données. Chez DATAROCKSTARS, nous entraînons nos étudiants à concevoir ces schémas pour que leurs tableaux de bord Power BI ou Tableau soient ultra-réactifs.
3. Les 4 étapes de la conception dimensionnelle
Kimball a défini un processus rigoureux en quatre étapes pour modéliser n’importe quel processus métier :
Choisir le processus métier : Par exemple, “la vente en magasin”.
Déclarer le grain : C’est l’étape la plus critique. Quel est le niveau de détail de chaque ligne de la table de faits ? (ex: un ticket de caisse, une ligne d’article).
Identifier les dimensions : Quelles sont les entités qui décrivent le fait ? (Date, Produit, Magasin, Employé).
Identifier les faits : Quelles sont les métriques numériques à agréger ? (Prix de vente, remise, taxe).
Maîtriser ces quatre étapes est le cœur de notre Bootcamp Data Engineer & AIOps. Une erreur sur le “grain” peut fausser l’intégralité d’un système décisionnel.
4. Les Dimensions Conformes (Conformed Dimensions)
Pour que l’approche décentralisée de Kimball fonctionne, il faut un ciment : les dimensions conformes. Ce sont des dimensions (comme “Temps” ou “Client”) qui sont définies une seule fois et partagées de manière identique par tous les Data Marts de l’entreprise. Sans dimensions conformes, il est impossible de croiser les données entre les services. Si le service marketing et le service financier ont deux définitions différentes du “Client”, le reporting global devient impossible. Chez DATAROCKSTARS, nous insistons sur cette gouvernance pour garantir l’intégrité des analyses.
5. La Table de Faits : Grain et Additivité
Une table de faits bien conçue selon Kimball doit être, dans l’idéal, hautement granulaire (au niveau le plus fin possible). Kimball rejette souvent les agrégats pré-calculés, préférant laisser la puissance des outils de BI calculer les sommes à la volée. Il existe trois types de faits :
• Additifs : Peuvent être sommés sur toutes les dimensions (ex: Chiffre d’affaires).
• Semi-additifs : Peuvent être sommés sur certaines dimensions seulement (ex: Un niveau de stock ne s’additionne pas sur le temps).
• Non-additifs : Ne peuvent jamais être sommés (ex: Une température, un ratio).
Savoir distinguer ces types de mesures est une compétence clé du Data Analyst pour éviter de produire des indicateurs absurdes.
6. Slowly Changing Dimensions (SCD)
Comment gérer les changements dans le temps ? Si un client déménage, doit-on écraser son ancienne adresse ou garder un historique ? Kimball propose plusieurs techniques de gestion des SCD :
• Type 1 : On écrase la donnée (pas d’historique).
• Type 2 : On crée une nouvelle ligne avec un début et une fin de validité (historique complet). C’est la méthode la plus utilisée.
• Type 3 : On ajoute une colonne “ancienne valeur” (historique limité).
Dans notre Bootcamp Data Scientist & AI, nous expliquons comment ces types de SCD impactent l’entraînement des modèles prédictifs, car la qualité de l’historique détermine la qualité de l’IA.
7. Les tables de faits sans faits (Factless Fact Tables)
Parfois, un événement n’a pas de métrique numérique associée, mais sa présence est une information en soi. Par exemple, le pointage d’un étudiant à un cours. Il n’y a pas de montant, mais le fait que l’événement “étudiant X présent au cours Y à la date Z” ait eu lieu est crucial. Kimball appelle cela une “Factless Fact Table”. Ces tables sont essentielles pour analyser l’occurrence d’événements ou la couverture d’un service. Savoir modéliser ces cas particuliers témoigne d’une maîtrise avancée du génie logiciel appliqué à la donnée.
8. Hiérarchies et dimensions flocon (Snowflake Schema)
Contrairement au modèle en étoile, le schéma en flocon normalise les dimensions (ex: séparer la ville de la région dans des tables distinctes). Kimball déconseille généralement le flocon pour les utilisateurs finaux car il rend les requêtes SQL plus complexes et lentes. Toutefois, dans certains cas de Data Engineering complexes, une normalisation partielle est nécessaire. Chez DATAROCKSTARS, nous vous apprenons à arbitrer entre performance (Étoile) et rigueur de stockage (Flocon) selon les contraintes de votre infrastructure Cloud.
9. Kimball vs Inmon : Le grand débat
Il est impossible de parler de Kimball sans citer Bill Inmon, le père de l’approche “Top-Down”. Là où Kimball préconise de commencer par les Data Marts, Inmon suggère de construire d’abord un immense entrepôt de données normalisé (3NF). Aujourd’hui, la plupart des entreprises utilisent une approche hybride : une couche de stockage normalisée (Inmon) pour la robustesse, et une couche de présentation dimensionnelle (Kimball) pour les utilisateurs. Nos cursus de Data Engineer vous préparent à ces architectures mixtes modernes.
10. Pourquoi maîtriser la méthode Kimball avec DATAROCKSTARS
À l’ère de l’IA Générative et du Big Data, la structure des données reste le facteur de succès numéro un. Un modèle de langage (LLM) ou un algorithme de Machine Learning ne peut produire de bons résultats que s’il est alimenté par des données bien organisées.
Chez DATAROCKSTARS, nous vous donnons les bases académiques et la pratique terrain pour devenir un architecte de données hors pair. Maîtriser Kimball, c’est s’assurer que vos projets data apportent une valeur concrète et mesurable à votre entreprise. Souhaitez-vous découvrir comment notre Bootcamp Data Analyst & AI peut vous aider à structurer vos données comme un expert mondial ?
Merci pour votre lecture ! Si vous souhaitez découvrir nos prochains articles autour de la Data et de l’IA, vous pouvez nous suivre sur Facebook, LinkedIn et Twitter pour être notifié dès la publication d’un nouvel article !