Dans le paysage technologique actuel, les termes Machine Learning (ML) et Deep Learning (DL) sont souvent utilisés de manière interchangeable, créant une confusion sur leurs capacités réelles. Bien que le Deep Learning soit une sous-catégorie du Machine Learning, ils diffèrent radicalement par leur architecture, leur besoin en données et leur puissance de calcul.
Chez DATAROCKSTARS, nous formons les futurs experts à discerner quel outil est le plus adapté à un problème business donné. Utiliser un réseau de neurones profond pour une tâche simple est une perte de ressources, tandis qu’utiliser un algorithme de régression classique pour la reconnaissance faciale est voué à l’échec. Voici l’analyse comparative complète pour maîtriser ces deux géants de la donnée.
1. La structure : Un emboîtement logique
Pour bien comprendre le débat, il faut visualiser l’Intelligence Artificielle comme un ensemble de poupées russes. L’IA est le concept global de machines imitant l’intelligence humaine. Le Machine Learning est la branche de l’IA qui permet aux ordinateurs d’apprendre sans être explicitement programmés. Enfin, le Deep Learning est une technique spécifique de Machine Learning basée sur des réseaux de neurones artificiels profonds.
Cette distinction est le socle de notre Bootcamp Data Scientist & AI Engineer. Nous y apprenons que le Deep Learning tente d’imiter la structure du cerveau humain pour résoudre des problèmes d’une complexité extrême que le ML classique ne peut traiter seul.
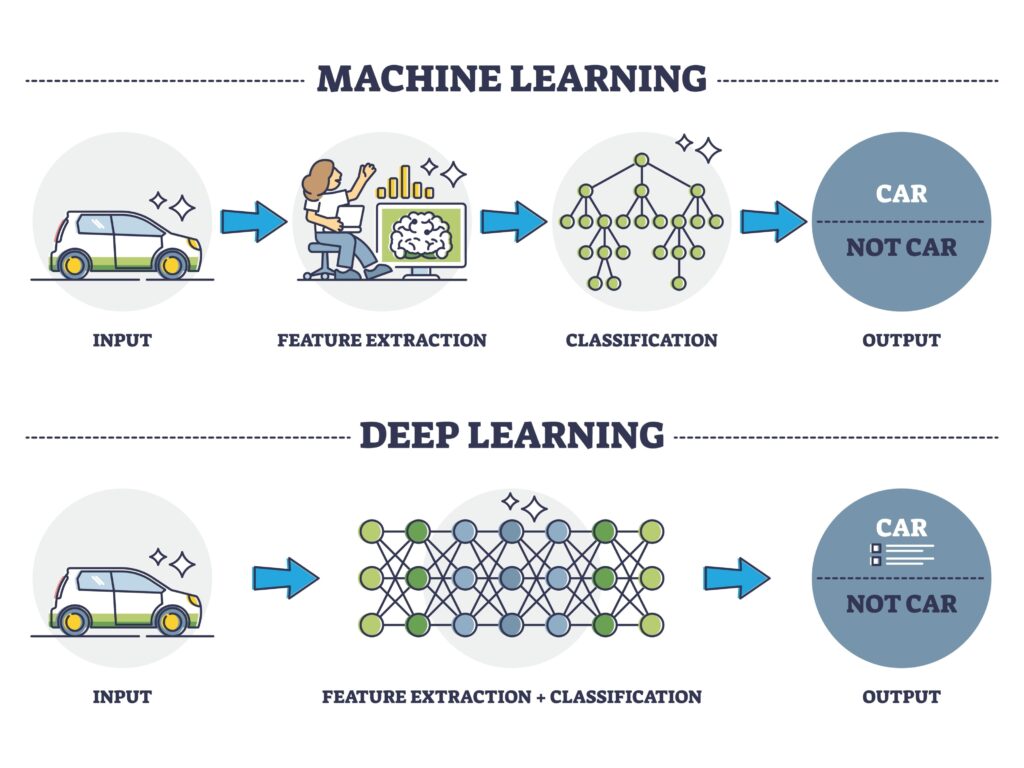
2. L’extraction des caractéristiques (Feature Engineering)
C’est la différence la plus fondamentale entre les deux approches. Dans le Machine Learning classique, un expert humain doit identifier et extraire manuellement les caractéristiques pertinentes (features) des données brutes pour que l’algorithme puisse les comprendre.
Dans le Deep Learning, l’algorithme apprend lui-même à extraire les caractéristiques. Par exemple, pour reconnaître un chat sur une photo : • En ML : Vous devez définir mathématiquement ce qu’est une oreille pointue ou une moustache. • En DL : Le réseau de neurones analyse des millions d’images et découvre par lui-même les motifs qui définissent un chat.
Cette automatisation est une force immense, mais elle demande une expertise que nous développons chez DATAROCKSTARS pour s’assurer que le modèle n’apprend pas des corrélations absurdes.
3. La quantité de données nécessaires
Le Deep Learning est un consommateur vorace de données. Pour être performant, un réseau de neurones profond a souvent besoin de millions d’échantillons. Sans cette masse critique, il risque le sur-apprentissage (overfitting) et sera moins performant qu’un simple algorithme de Machine Learning.
À l’inverse, le Machine Learning classique excelle sur des petits et moyens jeux de données (quelques milliers de lignes). Dans nos formations, nous apprenons à évaluer le “retour sur investissement” de la donnée : est-ce que collecter 10 fois plus de données pour passer au Deep Learning en vaut vraiment la peine pour votre entreprise ?
4. Puissance de calcul et infrastructure
Le Machine Learning classique est léger. Il peut s’exécuter sur un ordinateur de bureau standard en quelques secondes ou minutes. Le Deep Learning, en revanche, nécessite une puissance de calcul phénoménale. Il repose massivement sur les GPU (unités de traitement graphique) et des architectures cloud coûteuses pour entraîner ses couches de neurones.
La maîtrise de cette infrastructure est au cœur de notre Bootcamp Data Engineer & AIOps. Savoir configurer des clusters sur AWS ou Azure pour entraîner des modèles de Deep Learning sans faire exploser le budget est une compétence d’élite que nous vous transmettons.
5. Le temps d’entraînement et d’exécution
Le Deep Learning peut mettre des jours, voire des semaines, à s’entraîner sur des serveurs surpuissants. Cependant, une fois le modèle entraîné, son temps d’exécution (inférence) peut être très rapide. Le Machine Learning classique s’entraîne beaucoup plus vite, mais sa performance stagne rapidement dès que la complexité des données augmente.
Chez DATAROCKSTARS, nous vous apprenons à gérer ce compromis “temps vs précision” pour livrer des solutions qui respectent les contraintes de temps réel de vos clients.
6. L’interprétabilité du modèle (Boîte Noire)
Le Machine Learning classique offre des modèles souvent “transparents”. Si un algorithme d’arbre de décision refuse un prêt bancaire, on peut expliquer précisément pourquoi (ex: revenus trop faibles). Le Deep Learning est souvent considéré comme une boîte noire. Il est extrêmement difficile d’expliquer mathématiquement pourquoi un réseau de neurones a pris telle ou telle décision parmi ses milliards de paramètres.
Dans notre cursus Cybersécurité & IA, nous abordons l’importance de l’IA explicable (XAI) pour garantir que ces modèles puissants restent éthiques et auditables par les autorités de régulation.
7. Types de problèmes résolus
• Le Machine Learning : Idéal pour les données structurées (tableaux Excel, bases de données SQL). On l’utilise pour la prédiction de ventes, la détection de fraudes bancaires simples ou la segmentation client.
• Le Deep Learning : Indispensable pour les données non structurées. C’est le roi de la vision par ordinateur, du traitement du langage naturel (NLP) comme ChatGPT, et de la reconnaissance vocale.
Savoir identifier la nature de votre donnée est la première leçon chez DATAROCKSTARS. Choisir le bon paradigme dès le début du projet permet d’économiser des mois de développement inutile.
8. L’architecture des réseaux de neurones
Le Deep Learning tire son nom de la “profondeur” de ses réseaux. Il empile des couches de neurones artificiels : une couche d’entrée, de nombreuses couches cachées (Hidden Layers) et une couche de sortie. Chaque couche affine la compréhension de la donnée.
Apprendre à concevoir ces architectures (CNN pour les images, RNN pour les séries temporelles) est une compétence de pointe que nous enseignons de manière ultra-pratique, pour que vous sachiez construire vos propres modèles de A à Z.
9. Le transfert d’apprentissage (Transfer Learning)
C’est la botte secrète du Deep Learning moderne. Comme entraîner un modèle coûte cher, on utilise des modèles déjà pré-entraînés par des géants comme Google ou OpenAI (ex: ResNet ou BERT) et on les “affine” (fine-tuning) sur nos données spécifiques.
Le Machine Learning classique ne permet pas vraiment ce type de transfert. Chez DATAROCKSTARS, nous vous montrons comment exploiter le travail des meilleurs laboratoires mondiaux pour créer des IA surpuissantes à moindre coût pour votre organisation.
10. Pourquoi choisir DATAROCKSTARS pour maîtriser l’IA
Le débat entre Machine Learning et Deep Learning n’est pas une question de supériorité, mais d’adéquation. Un expert doit maîtriser les deux pour être polyvalent. Le marché recherche des profils capables de construire des pipelines robustes, qu’il s’agisse d’une simple régression ou d’un transformeur complexe.
Chez DATAROCKSTARS, nous vous donnons les bases mathématiques et la pratique intensive sur le cloud pour dompter ces deux technologies. Prêt à transformer le chaos des données en intelligence pure ? Souhaitez-vous découvrir comment notre Bootcamp Data Scientist & AI Engineer peut vous propulser au sommet de la hiérarchie technologique ?
Merci pour votre lecture ! Si vous souhaitez découvrir nos prochains articles autour de la Data et de l’IA, vous pouvez nous suivre sur Facebook, LinkedIn et Twitter pour être notifié dès la publication d’un nouvel article !