Dans le monde de la donnée, une intuition ne suffit jamais. Qu’il s’agisse de vérifier si une nouvelle fonctionnalité sur une application augmente réellement les ventes, ou de déterminer si un nouveau traitement médical est plus efficace qu’un placebo, nous avons besoin d’un cadre rigoureux pour conclure. C’est ici qu’interviennent les tests statistiques (ou tests d’hypothèses).
Chez DATAROCKSTARS, nous enseignons que les tests statistiques sont les garde-fous de l’analyste. Ils permettent de distinguer un véritable phénomène d’un simple coup de chance dû au hasard. Maîtriser ces tests, c’est donner une légitimité scientifique à vos recommandations business. Un Data Analyst ou un Data Scientist qui ne maîtrise pas ces concepts risque de prendre des décisions coûteuses basées sur des bruits aléatoires.
1. La structure d’un test : H0 et H1
Tout test statistique repose sur un duel entre deux hypothèses contradictoires :
• L’Hypothèse Nulle (H0) : C’est l’hypothèse par défaut. Elle stipule qu’il n’y a pas d’effet, pas de différence, ou que tout est dû au hasard (ex : “Le nouveau design du site n’a aucun impact sur le taux de clic”).
• L’Hypothèse Alternative (H1) : C’est ce que vous essayez de prouver. Elle stipule qu’il existe un effet réel (ex : “Le nouveau design augmente le taux de clic”).
L’objectif du test est de voir si les données récoltées sont suffisamment “extrêmes” pour nous permettre de rejeter H0 au profit de H1. Dans nos formations, nous insistons sur le fait qu’on ne “prouve” jamais H1, on se contente de rejeter H0 avec un certain degré de confiance.
2. La P-value : Le juge de paix
La p-value est sans doute le concept le plus célèbre et le plus mal compris des statistiques. Elle représente la probabilité d’obtenir les résultats observés (ou des résultats encore plus extrêmes) si l’hypothèse nulle (H0) était vraie.
• Si la p-value est très petite (généralement < 0,05) : Le résultat est statistiquement significatif. On rejette H0.
• Si la p-value est grande (> 0,05) : On ne peut pas rejeter H0. L’effet observé pourrait simplement être dû au hasard.
Chez DATAROCKSTARS, nous apprenons à nos étudiants à ne pas devenir des “esclaves de la p-value”. Un résultat peut être statistiquement significatif mais n’avoir aucune importance concrète pour le business. L’analyse du contexte reste primordiale.
3. Le risque Alpha et les erreurs de Type I et II
Prendre une décision basée sur un échantillon comporte toujours un risque d’erreur :
• Erreur de Type I (Faux Positif) : Rejeter H0 alors qu’elle est vraie (croire qu’il y a un effet alors qu’il n’y en a pas). Le risque associé est noté $\alpha$ (souvent 5 %).
• Erreur de Type II (Faux Négatif) : Ne pas rejeter H0 alors qu’elle est fausse (manquer un effet qui existe réellement). Le risque associé est noté $\beta$.
Trouver le bon équilibre entre ces deux risques est une compétence de haut niveau. Dans notre Bootcamp Data Scientist & AI Engineer, nous étudions comment la puissance d’un test ($1 – \beta$) permet de minimiser les chances de passer à côté d’une découverte majeure.
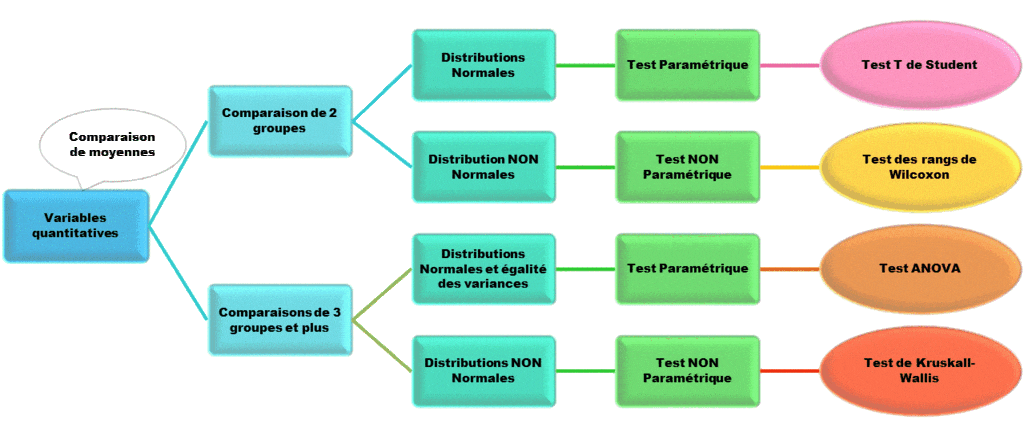
4. Les tests de comparaison de moyennes (Test de Student / t-test)
Le t-test est le roi des tests lorsque vous voulez comparer les moyennes de deux groupes. Par exemple : les clients parisiens dépensent-ils plus que les clients lyonnais ?
Il existe plusieurs variantes :
• Test pour échantillons indépendants : Comparer deux groupes distincts.
• Test pour échantillons appariés : Comparer le même groupe avant et après une intervention (ex : test d’un médicament).
• Test à un échantillon : Comparer la moyenne d’un groupe à une valeur théorique connue.
Savoir quel t-test choisir est l’un des premiers exercices pratiques dans nos cursus. C’est l’outil de base pour valider des tests A/B en marketing digital.
5. L’ANOVA : Comparer plus de deux groupes
Si vous avez trois variantes de couleurs pour un bouton sur votre site, le t-test ne suffit plus. Vous devez utiliser l’Analyse de Variance (ANOVA). L’ANOVA vérifie s’il existe au moins une différence significative entre les moyennes d’au moins deux de vos groupes.
Si l’ANOVA est significative, on effectue alors des tests “Post-hoc” (comme le test de Tukey) pour identifier précisément quels groupes diffèrent les uns des autres. Cette méthodologie structurée est au cœur de l’analyse de données rigoureuse que nous prônons chez DATAROCKSTARS.
6. Le test du Chi-deux ($\chi^2$) : Pour les données qualitatives
Tous les tests ne portent pas sur des moyennes. Le test du Chi-deux est utilisé pour analyser la relation entre deux variables qualitatives (catégorielles).
Exemple : Existe-t-il un lien entre le genre d’un utilisateur (Homme/Femme) et sa catégorie de produit préférée (Électronique/Mode) ?
Il permet de vérifier si la répartition observée est statistiquement différente de ce que l’on attendrait si les deux variables étaient totalement indépendantes. C’est un outil puissant pour la segmentation de clientèle, un sujet que nous approfondissons dans notre Bootcamp Data Analyst & AI.
7. Tests Paramétriques vs Non-Paramétriques
Pour utiliser des tests comme le t-test ou l’ANOVA, vos données doivent souvent respecter certaines conditions (normalité de la distribution, égalité des variances). Si ces conditions ne sont pas remplies, vous devez passer aux tests non-paramétriques :
• Test de Wilcoxon / Mann-Whitney : L’alternative au t-test.
• Test de Kruskal-Wallis : L’alternative à l’ANOVA.
Apprendre à vérifier les postulats d’un test avant de le lancer est une marque de professionnalisme. Chez DATAROCKSTARS, nous vous formons à ces étapes de diagnostic indispensables pour garantir la validité de vos conclusions.
8. Corrélation de Pearson et de Spearman
Le test de corrélation mesure la force du lien entre deux variables numériques.
• Pearson : Mesure la relation linéaire (si l’un monte, l’autre monte de manière proportionnelle).
• Spearman : Mesure la relation monotone (si l’un monte, l’autre monte, mais pas forcément en ligne droite).
Rappel crucial : Corrélation n’est pas causalité. Ce n’est pas parce que deux variables évoluent ensemble qu’une cause l’autre. Nous entraînons nos étudiants à débusquer ces corrélations fallacieuses pour éviter des erreurs stratégiques majeures.
9. Les tests dans l’ère de l’IA et du Machine Learning
Dans le Machine Learning, les tests statistiques sont utilisés pour valider la performance des modèles. Par exemple, le test de McNemar permet de comparer deux algorithmes de classification pour savoir si l’un est significativement meilleur que l’autre sur le même jeu de test.
On utilise aussi des tests pour détecter le Data Drift (dérive des données) : si la distribution des données réelles change par rapport aux données d’entraînement, le modèle perd en précision. Savoir automatiser ces tests est une compétence clé du Data Engineer & AIOps.
10. Pourquoi maîtriser les tests statistiques avec DATAROCKSTARS
Les statistiques sont le langage de la vérité dans un monde saturé de données. Savoir réaliser et interpréter un test statistique vous donne une autorité incontestable lors des prises de décision en entreprise. Vous ne dites plus “Je pense que…”, vous dites “Les données rejettent l’hypothèse nulle avec une confiance de 95 %”.
Chez DATAROCKSTARS, nous rendons les statistiques vivantes, concrètes et directement applicables à vos projets. Prêt à transformer vos incertitudes en décisions éclairées ? Souhaitez-vous découvrir comment notre Bootcamp Data Analyst & AI peut vous aider à devenir un maître de la validation de données et de la stratégie analytique ?
Merci pour votre lecture ! Si vous souhaitez découvrir nos prochains articles autour de la Data et de l’IA, vous pouvez nous suivre sur Facebook, LinkedIn et Twitter pour être notifié dès la publication d’un nouvel article !