Dans le monde de l’ingénierie logicielle, nous sommes tous confrontés un jour à la même limite : la taille de la base de données devient un obstacle à la performance. Que vous gériez une plateforme e-commerce mondiale, un réseau social ou un système d’analyse de données en temps réel, il arrive un moment où une seule machine, aussi puissante soit-elle, ne suffit plus pour gérer le volume des requêtes ou le stockage des données. C’est à ce stade critique qu’intervient le sharding (ou partitionnement horizontal). Le sharding est une architecture distribuée qui consiste à diviser une base de données trop volumineuse en petits fragments plus digestes, appelés “shards”, répartis sur plusieurs serveurs. Pour les ingénieurs formés par DATAROCKSTARS, le sharding n’est pas seulement une technique de stockage ; c’est un changement de paradigme qui exige de repenser totalement la cohérence, la disponibilité et la gestion des données. Dans cet article, nous allons explorer les tenants et aboutissants de cette architecture essentielle au passage à l’échelle.
1. Vertical vs Horizontal : Le choix de la scalabilité
Avant de comprendre le sharding, il faut distinguer les deux grands modes de croissance. La montée en puissance verticale (vertical scaling) consiste à ajouter plus de CPU, de RAM et de stockage à un serveur unique. C’est simple, immédiat, mais limité par le matériel disponible et le coût exponentiel des serveurs très haut de gamme. À l’inverse, la montée en puissance horizontale (horizontal scaling) — c’est-à-dire le sharding — consiste à ajouter davantage de serveurs (nœuds) à votre infrastructure pour répartir la charge.
Le sharding permet de dépasser les limites physiques du matériel. En théorie, il n’y a pas de limite au nombre de shards que vous pouvez ajouter pour absorber la croissance. Cependant, cette simplicité théorique cache une complexité opérationnelle immense. Chez DATAROCKSTARS, nous apprenons à nos étudiants que le choix du sharding doit être réfléchi : si votre application peut fonctionner avec une base de données bien optimisée sur un serveur puissant, ne vous compliquez pas la vie avec le sharding dès le premier jour. C’est une architecture de “dernier recours” pour les projets qui ont réellement besoin de passer au niveau industriel.
2. Le principe du Sharding : Diviser pour mieux régner
L’idée centrale du sharding est le partitionnement. Imaginez une table de 10 milliards de lignes : vous allez la diviser en 10 fragments de 1 milliard, stockés sur 10 serveurs distincts. Le défi est de savoir, pour chaque requête, sur quel serveur se trouve la donnée. C’est là qu’intervient la logique de routage. Une application intelligente doit savoir que la requête pour “Utilisateur X” doit être envoyée au Shard 1, tandis que la requête pour “Utilisateur Y” doit aller au Shard 2.
Cette division transforme votre architecture de base de données en un système distribué. Chaque shard est une base de données autonome qui gère son propre sous-ensemble de données. Chez DATAROCKSTARS, nous enseignons que cette abstraction doit idéalement être gérée au niveau de la couche d’accès aux données ou du middleware, afin de ne pas saturer le code applicatif avec des règles de routage complexes. Un système de sharding bien conçu est invisible pour le développeur qui écrit les requêtes SQL, tout en étant extrêmement efficace sous le capot.
3. Le Shard Key : La décision la plus importante de votre carrière
Le choix de la “Shard Key” (clé de partitionnement) est sans doute la décision la plus critique de l’architecture. La Shard Key est le champ qui détermine dans quel shard une donnée est stockée. Si vous choisissez l’ID de l’utilisateur comme clé, toutes les données liées à un utilisateur spécifique seront stockées sur le même shard. Si vous choisissez le pays, tous les utilisateurs d’un même pays seront regroupés.
Le danger principal est le phénomène des “hotspots” (points chauds). Si vous choisissez le pays comme clé et que 80% de vos utilisateurs sont aux États-Unis, votre shard “États-Unis” sera saturé alors que les autres seront vides. Le sharding est efficace seulement si les données sont réparties de manière uniforme. Chez DATAROCKSTARS, dans nos bootcamps Data Engineer & AIOps, nous montrons comment analyser la distribution de vos données avant de choisir une clé. Un mauvais choix de clé peut rendre votre cluster inutilisable, tandis qu’un bon choix garantit une linéarité parfaite de la performance.
4. Stratégies de Sharding : Range, Hash et Directory-based
Il existe plusieurs façons de distribuer les données :
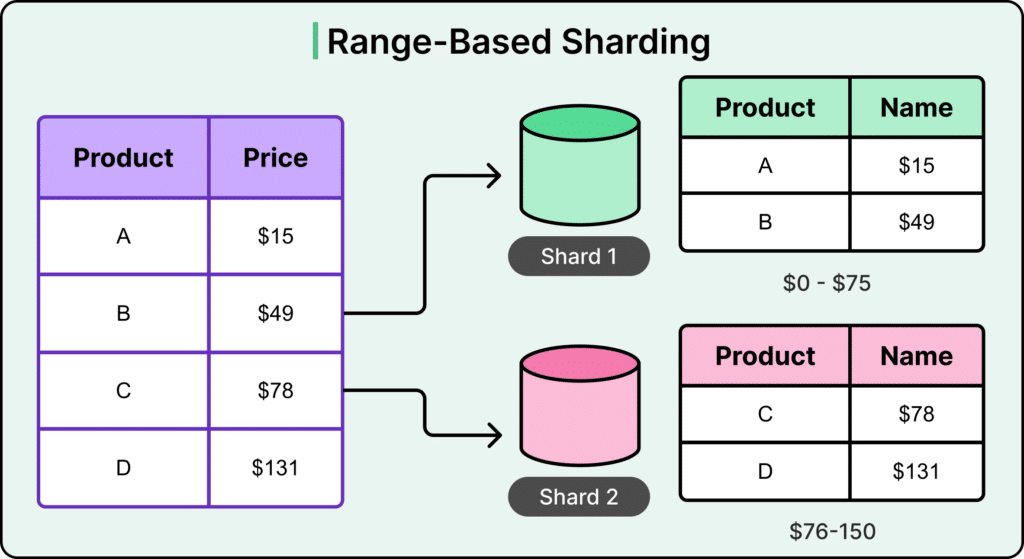
- Range-based sharding : Vous divisez par plages de valeurs (ex: ID 1-1000 sur le shard 1, 1001-2000 sur le shard 2). C’est simple mais très risqué pour les hotspots si les données ne sont pas uniformes.
- Hash-based sharding : Vous appliquez une fonction de hachage sur la clé et utilisez le résultat pour déterminer le shard. C’est la méthode la plus courante car elle garantit une répartition statistique équilibrée des données.
- Directory-based sharding : Vous maintenez une table de correspondance (un annuaire) qui dit explicitement quelle clé va vers quel shard. C’est très flexible, mais l’annuaire devient un point de défaillance unique.
Chaque stratégie a ses avantages et ses inconvénients. Dans notre pratique chez DATAROCKSTARS, nous privilégions souvent le hachage pour sa résilience et sa capacité à éviter les hotspots. Comprendre comment fonctionne la fonction de hachage est essentiel pour prévoir comment votre système va réagir quand vous ajouterez un nouveau shard à votre cluster.
5. Le défi de la réindexation et du “Resharding”
Imaginez que vous avez commencé avec 4 shards et que, deux ans plus tard, le volume de données a doublé. Vous devez ajouter des shards. Avec une méthode basée sur le hachage (clé % nombre_de_shards), le simple fait de passer de 4 à 5 shards change la destination de la majorité de vos données. Vous devez donc déplacer physiquement des téraoctets d’informations. C’est ce qu’on appelle le “resharding”.
C’est l’opération la plus redoutée des Data Engineers. Elle peut entraîner des temps d’arrêt prolongés ou une charge réseau insupportable. Pour éviter cela, des techniques comme le “Consistent Hashing” sont utilisées. Elles permettent d’ajouter des shards en ne déplaçant qu’une fraction minimale des données. Chez DATAROCKSTARS, nous enseignons comment automatiser ces migrations sans interruption de service. La capacité à faire croître une base de données sans arrêter l’application est ce qui distingue une architecture mature d’un système artisanal.
6. Jointures et Transactions : La mort de la simplicité
Le sharding introduit une complexité majeure : les jointures (JOINs). Dans une base de données unique, joindre deux tables est une opération triviale. Dans une base de données shardée, les tables peuvent se trouver sur des serveurs différents. Pour faire une jointure, vous devez soit rapatrier toutes les données sur un serveur central (ce qui est extrêmement lent), soit implémenter des jointures distribuées.
Il en va de même pour les transactions ACID (Atomicity, Consistency, Isolation, Durability). Garantir qu’une transaction qui touche deux tables se valide entièrement sur les deux serveurs distants demande des protocoles de “commit distribué” très complexes (comme le Two-Phase Commit). Chez DATAROCKSTARS, nous apprenons à nos étudiants à concevoir leurs modèles de données pour éviter les jointures complexes. C’est une règle d’or en architecture distribuée : dénormalisez vos données au maximum pour minimiser la nécessité de transactions distribuées.
7. Le rôle du Middleware : Les frameworks de Sharding
Ne réinventez pas la roue. La plupart des ingénieurs utilisent des middlewares pour gérer le sharding pour eux. Des outils comme Vitess (pour MySQL) ou des fonctionnalités natives de bases de données distribuées (NewSQL) comme CockroachDB ou TiDB gèrent le sharding de manière transparente. Ces outils font le routage, la réplication, et le rebalancing automatiquement.
Choisir le bon outil est une décision stratégique. Chez DATAROCKSTARS, nous formons nos ingénieurs à évaluer ces solutions. Est-ce qu’il vaut mieux gérer son propre sharding avec une base classique ou utiliser une base de données nativement distribuée ? La réponse dépend de la complexité de vos requêtes et de vos capacités opérationnelles. La maîtrise de ces outils est indispensable pour quiconque souhaite gérer des infrastructures à très haute disponibilité.
8. Observabilité : Monitorer un système distribué
Monitorer une base de données est facile. Monitorer 50 shards, chacun avec ses propres métriques, est un défi d’observabilité. Vous devez surveiller la latence de chaque shard, le remplissage des disques, le taux de requêtes, et la charge des CPU. Un seul shard lent peut ralentir toute l’application.
Dans nos bootcamps, nous apprenons à mettre en place des dashboards avec Prometheus et Grafana pour avoir une vision globale du cluster. Vous apprendrez à détecter un hotspot avant qu’il ne fasse planter le système et à automatiser les alertes. L’observabilité n’est pas optionnelle ; dans une architecture shardée, c’est votre seule fenêtre sur la santé de votre système. Sans elle, vous pilotez à l’aveugle.
9. Cybersécurité : Sécuriser les communications entre Shards
Dans une architecture distribuée, les communications entre les shards ou entre le middleware et les shards deviennent des vecteurs d’attaque potentiels. Ces flux doivent être chiffrés, authentifiés et monitorés. Si un attaquant parvient à s’interposer dans le réseau, il peut injecter des données ou exfiltrer des informations confidentielles directement à partir du bus de données.
Chez DATAROCKSTARS, nous intégrons la sécurité à chaque étape. Appliquer le chiffrement en transit (TLS) entre tous les composants, gérer des accès restreints via des réseaux privés (VPC) et durcir les configurations de chaque nœud est la norme. La sécurité n’est pas juste une couche externe, c’est une composante architecturale de votre système shardé. C’est ce niveau d’exigence que nous transmettons dans nos formations en cybersécurité.
10. Pourquoi les Data Engineers doivent dompter le Sharding
En 2026, la donnée est le pétrole de l’entreprise, mais elle est devenue si volumineuse que la stocker sur une seule machine est une pratique archaïque. Le sharding est une compétence que tout Data Engineer sérieux doit maîtriser. C’est ce qui vous permet de prendre un système qui s’effondre sous le poids des requêtes et de le transformer en une machine capable de supporter la croissance mondiale.
Chez DATAROCKSTARS, notre ambition est de faire de vous des architectes capables de concevoir ces systèmes robustes. La technologie est complexe, les erreurs sont coûteuses, mais la maîtrise est gratifiante. Apprendre le sharding, c’est comprendre comment l’information circule et est stockée au cœur même de l’internet. Rejoignez nos cursus pour acquérir cette expertise fondamentale et propulser votre carrière. Souhaitez-vous découvrir comment notre Bootcamp Data Engineer & AIOps peut vous faire devenir l’expert indispensable aux architectures de données massives ?
Merci pour votre lecture ! Si vous souhaitez découvrir nos prochains articles autour de la Data et de l’IA, vous pouvez nous suivre sur Facebook, LinkedIn et Twitter pour être notifié dès la publication d’un nouvel article !