Bien que son nom contienne le mot “régression”, la régression logistique est, par nature, un algorithme de classification. C’est l’un des modèles les plus utilisés en statistiques et en Machine Learning pour répondre à une question binaire : “Est-ce vrai ou faux ?”, “Est-ce un spam ou non ?”, “Ce client va-t-il résilier son contrat ?”. Contrairement à la régression linéaire qui prédit une valeur continue (comme un prix ou une température), la régression logistique prédit la probabilité qu’une donnée appartienne à une classe donnée. Pour tout Data Scientist ou Data Engineer formé chez DATAROCKSTARS, comprendre cet algorithme est le premier pas indispensable avant d’aborder des modèles plus complexes, car il offre une interprétabilité exceptionnelle, essentielle pour les décisions métier.
1. L’intuition derrière la fonction sigmoïde
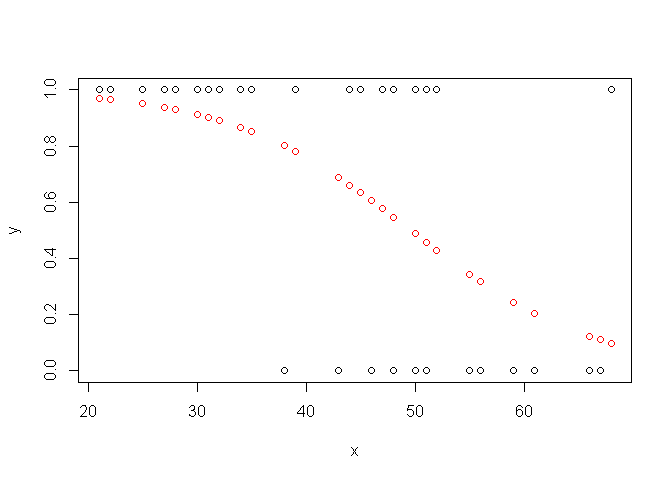
La régression logistique ne prédit pas directement une classe, mais une probabilité comprise entre 0 et 1. Pour transformer une sortie linéaire (qui peut aller de moins l’infini à plus l’infini) en une probabilité (entre 0 et 1), nous utilisons une fonction spéciale appelée la fonction “sigmoïde” (ou fonction logistique). Elle prend la forme d’un “S” étiré.
Cette courbe en S est magique pour les statisticiens : elle écrase les valeurs extrêmes vers 0 ou 1, tout en étant très sensible autour de 0,5. C’est ce qui permet au modèle de dire avec confiance : “Il y a 95% de chances que ce soit un spam” ou “Il y a 2% de chances que ce soit un spam”. Chez DATAROCKSTARS, nous insistons toujours sur le fait que comprendre la sigmoïde est essentiel pour saisir pourquoi le modèle est “logistique”. C’est cette transformation mathématique qui fait toute la différence par rapport à une simple droite de régression.
2. Pourquoi “Régression” si c’est de la classification ?
Le nom peut prêter à confusion. La raison est historique et mathématique : au fond, le modèle cherche à modéliser la relation entre les variables d’entrée et le log-odds (le logarithme des chances) de la variable de sortie, ce qui est une forme de régression linéaire. La régression logistique est simplement une régression linéaire sur laquelle on applique une transformation non linéaire (la sigmoïde) pour forcer la sortie à rester dans l’intervalle [0, 1].
Dans nos formations, nous expliquons que c’est un modèle linéaire généralisé. C’est une distinction importante à comprendre pour tout Data Scientist : la régression logistique est une extension élégante du modèle linéaire classique. Elle partage avec lui sa simplicité et sa rapidité d’exécution, ce qui en fait un outil de choix pour les systèmes nécessitant une réponse en temps réel, comme les systèmes de détection de fraude bancaire.
3. La frontière de décision : Le seuil à 0,5
Comment passons-nous de la probabilité à la décision finale ? Nous utilisons un seuil, le plus souvent fixé à 0,5. Si la probabilité prédite est supérieure à 0,5, nous classons l’entrée dans la catégorie “Vrai” (ou 1). Si elle est inférieure, dans la catégorie “Faux” (ou 0). Ce seuil crée une “frontière de décision” dans vos données.
Cette frontière est une droite (ou un hyperplan dans des dimensions supérieures). C’est pourquoi la régression logistique est appelée un “classifieur linéaire”. Elle ne peut séparer les données que si elles sont linéairement séparables. Si vos données forment des formes complexes ou imbriquées, la régression logistique sera limitée. Chez DATAROCKSTARS, nous apprenons à nos étudiants à visualiser ces frontières, car c’est en comprenant les limites géométriques de vos modèles que vous saurez quand passer à des algorithmes plus puissants comme les Random Forests ou les réseaux de neurones.
4. Les applications concrètes en entreprise
La régression logistique est partout. Dans le secteur bancaire, elle est le moteur du “Credit Scoring” : elle calcule la probabilité qu’un emprunteur fasse défaut sur son crédit. Dans le marketing, elle est utilisée pour prédire le “Churn” : quels clients vont quitter la marque dans les 3 prochains mois ? En médecine, elle aide à diagnostiquer des pathologies en classant des patients comme “malades” ou “sains” en fonction de biomarqueurs.
Le grand avantage de la régression logistique pour ces cas d’usage est son interprétabilité. Contrairement à une IA complexe qui vous donne un score sans explication, la régression logistique vous donne des “poids” (coefficients) pour chaque variable. Vous pouvez dire au métier : “Chaque année supplémentaire d’ancienneté réduit la probabilité de churn de 5%”. Cette transparence est un avantage compétitif majeur pour les entreprises qui doivent justifier leurs décisions auprès des régulateurs ou des clients. C’est un aspect que nous valorisons dans nos cursus de Data Engineer & AIOps.
5. Les hypothèses fortes du modèle
Comme tout modèle statistique, la régression logistique repose sur des hypothèses. Si elles ne sont pas respectées, le modèle perd en précision. Par exemple, elle suppose l’indépendance des observations et l’absence de colinéarité entre les variables explicatives (si deux variables sont trop corrélées, le modèle devient instable). Elle suppose également une relation linéaire entre les variables d’entrée et le logit de la probabilité.
Dans nos bootcamps, nous passons beaucoup de temps sur l’étape de préparation des données (Data Cleaning et Feature Engineering). Identifier la multicolinéarité avant l’entraînement est une compétence cruciale. Un modèle logistique entraîné sur des données mal préparées produira des coefficients aberrants, menant à des décisions métier catastrophiques. La rigueur statistique est le rempart contre l’effet “boîte noire” de l’IA.
6. La régularisation : Lutter contre le sur-apprentissage
Même si la régression logistique est un modèle simple, elle peut faire du sur-apprentissage (overfitting) si vous avez trop de variables par rapport au nombre d’observations. Pour contrer cela, on utilise la régularisation (Lasso ou Ridge). La régularisation ajoute une pénalité aux coefficients du modèle, forçant les variables les moins utiles à s’annuler.
La régularisation Lasso, en particulier, est très prisée car elle effectue une sélection de variables automatique (elle met à zéro les coefficients non pertinents). C’est un excellent outil pour simplifier vos modèles tout en conservant la précision. Chez DATAROCKSTARS, nous montrons comment régler ces hyperparamètres avec les bibliothèques comme scikit-learn. Maîtriser la régularisation, c’est savoir construire des modèles robustes, capables de généraliser sur des données qu’ils n’ont jamais vues en entraînement.
7. Extension vers la classification multi-classes
La régression logistique est nativement binaire. Mais que faire si vous avez trois classes : “Client Actif”, “Churn imminent”, “Churn confirmé” ? On utilise alors la régression logistique multinomiale, souvent appelée Softmax Regression. Le principe est d’étendre la sigmoïde à plusieurs catégories en utilisant la fonction Softmax, qui distribue la probabilité totale de 1 entre toutes les classes disponibles.
C’est une extension naturelle qui est très utilisée pour des tâches comme la reconnaissance de chiffres manuscrits ou la classification de documents. Dans nos formations, nous vous apprenons à structurer vos datasets pour permettre cette classification multi-classes. Comprendre la transition du binaire au multinomial est essentiel pour construire des systèmes d’IA capables de gérer des problèmes de classification du monde réel, qui sont rarement aussi simples que “0 ou 1”.
8. L’évaluation : Pourquoi la précision ne suffit pas
Dans un problème de classification, vous entendrez souvent parler de précision, de rappel (recall), de F1-score et de matrice de confusion. Pourquoi ? Parce que si vous essayez de prédire une maladie rare qui touche 0,1% de la population, un modèle qui prédit toujours “sain” aura 99,9% de précision mais sera inutile. C’est le piège du déséquilibre des classes.
Chez DATAROCKSTARS, nous apprenons à nos étudiants à regarder au-delà du chiffre brut. La matrice de confusion est votre meilleure alliée : elle vous montre les vrais positifs, les faux positifs, les vrais négatifs et les faux négatifs. Comprendre le coût d’une erreur (ex: un faux négatif en médecine est plus grave qu’un faux positif) est ce qui transforme un simple utilisateur de bibliothèque Python en un véritable ingénieur IA responsable et compétent.
9. Implémentation pratique : Python et Scikit-Learn
En pratique, la régression logistique se code en quelques lignes avec Python. Scikit-Learn est la bibliothèque de référence. L’étape clé n’est pas l’appel à .fit(), c’est la préparation de la donnée (StandardScaler) et le découpage en train/test set. Un bon Data Scientist passe 80% de son temps à nettoyer la donnée et à préparer le modèle, et seulement 20% à l’entraîner.
Dans nos bootcamps, vous ne coderez pas seulement des exemples, vous travaillerez sur des datasets réels, souvent “sales” et imparfaits. C’est cette expérience pratique qui vous prépare au monde de l’entreprise. Vous apprendrez que la régression logistique est souvent le “baseline model” (le modèle de référence) : si vous ne pouvez pas battre une régression logistique bien optimisée avec un modèle deep learning complexe, alors votre modèle complexe ne sert à rien. C’est une leçon d’humilité et d’efficacité ingénierique.
10. Pourquoi maîtriser les bases est le secret des experts
Il est tentant de vouloir sauter directement sur les derniers modèles de LLM ou de réseaux de neurones profonds. Mais les ingénieurs qui réussissent le mieux sont ceux qui maîtrisent parfaitement les fondamentaux comme la régression logistique. Ils savent quand un modèle complexe est justifié et quand un modèle simple est préférable pour des raisons d’interprétabilité et de coût.
Chez DATAROCKSTARS, notre philosophie est de bâtir des fondations solides. Vous deviendrez des ingénieurs capables de choisir le bon outil pour le bon problème, et de justifier vos choix technologiques. La régression logistique n’est pas un modèle obsolète ; c’est un outil indispensable de la panoplie du data scientist expert. Rejoignez nos cursus pour acquérir cette maîtrise et propulser votre carrière. Souhaitez-vous découvrir comment notre Bootcamp Data Engineer & AIOps peut vous aider à industrialiser vos modèles, qu’ils soient simples ou complexes ?
Merci pour votre lecture ! Si vous souhaitez découvrir nos prochains articles autour de la Data et de l’IA, vous pouvez nous suivre sur Facebook, LinkedIn et Twitter pour être notifié dès la publication d’un nouvel article !