Dans le domaine vaste et complexe de la vision par ordinateur, la classification d’images — savoir si une photo contient un chat ou un chien — n’est souvent que la première étape. Pour de nombreuses applications industrielles, médicales ou scientifiques, ce dont nous avons besoin, c’est de comprendre où se trouve l’objet, pixel par pixel. C’est ce qu’on appelle la segmentation sémantique. L’architecture U-Net, initialement développée pour le domaine biomédical, est devenue le standard de l’industrie pour cette tâche. Sa forme en “U” caractéristique cache une prouesse d’ingénierie qui permet de conserver à la fois le contexte global d’une image et les détails de localisation les plus fins. Comprendre le U-Net, c’est comprendre comment construire des modèles capables de “voir” et de “délimiter” avec une précision chirurgicale.
Chez DATAROCKSTARS, nous observons que la segmentation est l’une des briques technologiques les plus demandées dans les projets d’IA modernes : détection de tumeurs, analyse de satellites pour l’agriculture, conduite autonome, contrôle qualité industriel. Maîtriser le U-Net, c’est maîtriser la capacité à extraire une information spatialement structurée. Que vous soyez un futur Data Scientist ou un Data Engineer cherchant à déployer des modèles de vision en production, cet article vous plonge au cœur de cette architecture. Pour aller plus loin et manipuler ces modèles concrètement, découvrez notre Bootcamp Data Scientist & AI Engineer.
1. La segmentation sémantique : Définir le terrain de jeu
Avant d’entrer dans les détails techniques du U-Net, il est crucial de définir la tâche. La segmentation sémantique est une méthode de vision par ordinateur qui consiste à classer chaque pixel d’une image. Contrairement à la détection d’objets (qui dessine une boîte autour d’un objet), la segmentation découpe l’image pour épouser les contours exacts des objets. Si vous analysez une radiographie, la segmentation ne vous dira pas seulement “il y a une tumeur”, elle vous donnera la forme exacte de la zone anormale. C’est une tâche beaucoup plus riche en informations que la simple classification.
Cependant, cette richesse a un coût : la complexité computationnelle. Un modèle doit être capable de comprendre la scène globale (est-ce un poumon ?) tout en étant capable d’identifier les frontières de chaque pixel avec une précision extrême. Les premières architectures de Deep Learning peinaient à combiner ces deux niveaux d’information : soit elles perdaient les détails lors de la contraction (le “pooling”), soit elles manquaient de contexte global. Le U-Net a résolu ce dilemme avec une élégance structurelle unique. C’est cette élégance que nous enseignons chez DATAROCKSTARS pour que nos étudiants puissent résoudre des problèmes de vision complexes, et non plus se limiter à des exemples de tutoriels simples.
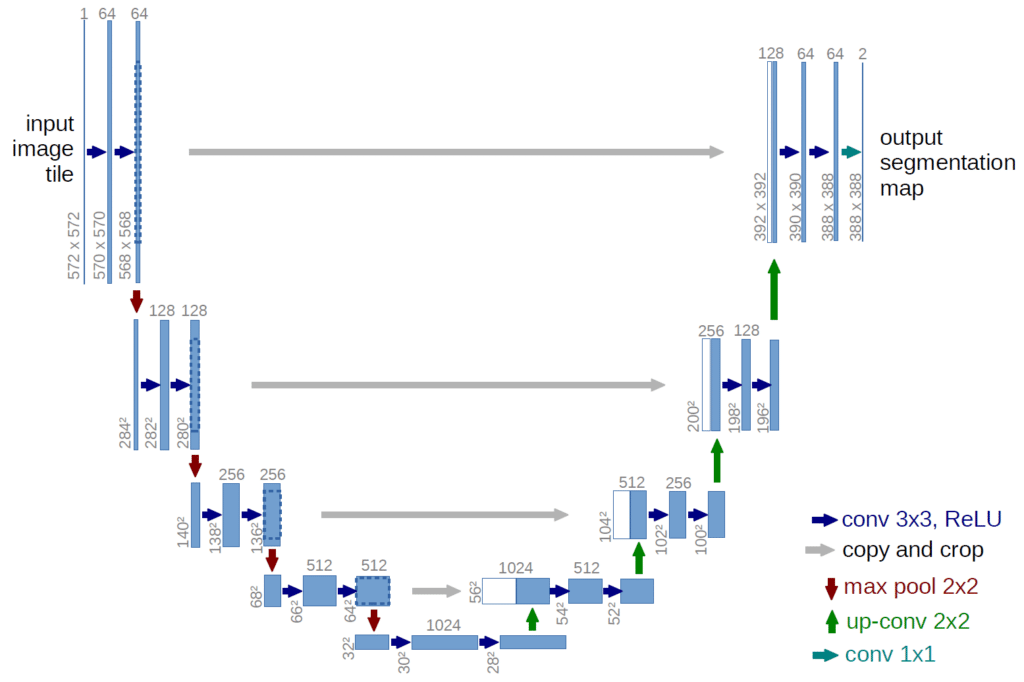
2. Anatomie de l’architecture : Pourquoi un “U” ?
Le nom “U-Net” provient de sa forme visuelle lors de la représentation du graphe de son architecture. Il se compose d’une partie descendante, souvent appelée “chemin de contraction” (ou encodeur), et d’une partie ascendante, le “chemin d’expansion” (ou décodeur). Le passage entre les deux se fait par un point de jonction qui donne cette forme en “U”. Cette architecture est une évolution directe du réseau entièrement convolutif (FCN – Fully Convolutional Network). La logique est simple : pour comprendre ce qu’il y a dans l’image, il faut compresser l’information pour extraire les caractéristiques (features), puis reconstruire l’image à partir de ces caractéristiques.
Cette forme en U n’est pas un choix esthétique. Elle représente une symétrie fonctionnelle. La partie descendante réduit la résolution spatiale pour augmenter la profondeur sémantique : le réseau apprend “ce qu’est” l’image. La partie ascendante, à l’inverse, augmente la résolution spatiale pour permettre la reconstruction des masques de segmentation : le réseau apprend “où sont” les éléments. Chez DATAROCKSTARS, nous insistons sur la compréhension géométrique des couches : chaque couche de convolution réduit ou augmente la résolution par un facteur de 2. Cette rigueur mathématique est indispensable pour maintenir les dimensions lors de la reconstruction.
3. Le chemin de contraction : L’encodeur et l’extraction de caractéristiques
Le chemin de contraction est composé de plusieurs blocs de convolution répétitifs. Chaque bloc consiste typiquement en deux convolutions 3×3 suivies d’une fonction d’activation ReLU, et d’une opération de Max Pooling 2×2. L’objectif ici est de réduire la taille de l’image de moitié à chaque étape tout en augmentant le nombre de “canaux” (ou de cartes de caractéristiques). En début de réseau, le modèle détecte des caractéristiques simples comme des bords ou des textures. En descendant dans le U, le réseau apprend des structures plus complexes.
Le Max Pooling est l’opération qui permet cette réduction de résolution. Il sélectionne la valeur maximale dans une fenêtre donnée, ce qui permet d’invarier le modèle par rapport aux légères translations (si l’objet bouge un peu, la caractéristique reste capturée). Mais c’est une opération destructive : on perd la localisation exacte du pixel. C’est là que réside le génie du U-Net : il sait que cette perte est inévitable pour la compréhension sémantique, mais qu’elle sera compensée par la partie ascendante. Dans notre Bootcamp Data Engineer & AIOps, nous détaillons comment gérer ce flux de données pour optimiser les performances des modèles sur vos infrastructures Cloud.
4. Le chemin d’expansion : Le décodeur et la reconstruction
Après avoir atteint le bas du “U”, le modèle possède une représentation très abstraite et très profonde de l’image. Il faut maintenant “remonter” pour retrouver la résolution originale de l’image d’entrée et produire un masque de segmentation de la même taille. C’est le rôle du chemin d’expansion. Contrairement à l’encodeur, le décodeur utilise des convolutions transposées (ou Upsampling) pour augmenter la résolution spatiale de l’image.
Chaque étape de cette reconstruction est cruciale. Si vous vous contentez de remonter à partir de l’abstraction profonde, vous obtiendrez un masque de segmentation très flou, avec des contours imprécis. Vous avez perdu trop d’informations spatiales lors de la descente. C’est pourquoi le décodeur du U-Net ne travaille pas seul : il reçoit une aide précieuse de l’encodeur à chaque étape de la reconstruction. Cette étape de reconstruction est critique pour des applications où la précision est vitale, comme le détourage d’objets industriels. Chez DATAROCKSTARS, nous formons nos experts à l’ajustement de ces couches pour obtenir des résultats qui respectent les exigences industrielles les plus strictes.
5. La magie des skip connections : Le pont indispensable
Les “skip connections” (connexions de saut) sont l’ingrédient secret du succès du U-Net. À chaque niveau de résolution dans le chemin de contraction, nous gardons les cartes de caractéristiques (feature maps) résultantes. Nous les “copions” et les “collons” (concaténation) directement sur les cartes correspondantes lors du chemin d’expansion. Cela permet au décodeur d’avoir accès non seulement à l’information abstraite reconstruite, mais aussi aux détails de haute résolution perdus lors de la contraction.
Sans ces skip connections, le réseau serait incapable de produire des masques de segmentation avec des bords nets. Ils permettent de transmettre les informations spatiales depuis les premières couches (où les détails sont préservés) jusqu’aux dernières couches (où la compréhension sémantique est achevée). C’est ce pont qui permet au U-Net d’être à la fois un excellent classificateur et un excellent localisateur. Pour les Data Scientists de DATAROCKSTARS, ces connexions sont le rappel constant qu’en Deep Learning, le choix de l’architecture est tout aussi important que le volume de données. Apprendre à utiliser les skip connections correctement est ce qui sépare les modèles qui performent sur Kaggle de ceux qui sont prêts pour la production.
6. Fonctions de perte : L’optimisation pour la segmentation
Pour entraîner un U-Net, on ne peut pas toujours utiliser la traditionnelle erreur quadratique moyenne. La segmentation est un problème de classification pixel par pixel. La fonction de perte la plus classique est la Cross-Entropy, mais elle présente un défaut majeur en segmentation : le déséquilibre des classes. Dans une image, il y a souvent beaucoup plus de pixels de “fond” que de pixels “objet”. Si vous entraînez un modèle sur une image de tumeur, 99% des pixels seront sains. Le modèle pourrait atteindre 99% de précision en disant simplement “tout est sain”.
C’est là que le Dice Loss (indice de Dice) entre en jeu. Le Dice Loss est conçu spécifiquement pour la segmentation. Il mesure le chevauchement entre la prédiction et la vérité terrain (ground truth). Il est beaucoup plus robuste face au déséquilibre des classes car il se concentre sur l’intersection des régions. Chez DATAROCKSTARS, nous enseignons comment choisir et adapter ces fonctions de perte pour garantir que votre modèle apprend réellement à segmenter l’objet d’intérêt, et non à prédire le fond. Cette finesse mathématique est indispensable pour atteindre des performances de pointe sur des projets de Data Scientist & AI.
7. Applications concrètes : Pourquoi le U-Net domine en imagerie médicale
Le U-Net a été inventé en 2015 par Olaf Ronneberger et ses collègues pour la segmentation de cellules dans des images de microscopie. Depuis, il est devenu l’incontournable du domaine médical. Qu’il s’agisse de segmenter des tumeurs cérébrales sur des IRM, de détecter des lésions pulmonaires sur des scanners thoraciques, ou de compter des cellules sur des images de microscopie électronique, le U-Net est systématiquement utilisé. Pourquoi ? Parce qu’il est extrêmement efficace même avec un nombre réduit d’images annotées, ce qui est très fréquent dans le milieu médical.
Dans nos programmes, nous utilisons des datasets médicaux pour faire pratiquer nos étudiants. Vous apprenez à gérer des formats spécifiques comme le DICOM, à gérer les augmentations de données (Data Augmentation) pour renforcer le modèle, et à interpréter les résultats cliniquement. Comprendre pourquoi un modèle segmente une zone, c’est aussi comprendre les enjeux d’éthique et de fiabilité de l’IA dans la santé. DATAROCKSTARS vous prépare non seulement techniquement, mais aussi à la responsabilité de déployer de tels modèles dans des environnements critiques où chaque erreur a un impact réel sur la vie humaine.
8. Au-delà de l’original : Variants et améliorations du U-Net
Le succès du U-Net a engendré une famille entière d’architectures basées sur le même principe. Le U-Net++ améliore la connectivité des skip connections pour une meilleure extraction de caractéristiques. L’Attention U-Net intègre des mécanismes d’attention pour permettre au réseau de “se concentrer” sur les régions importantes de l’image tout en ignorant les régions non pertinentes (ce qui est crucial pour filtrer le bruit dans les images complexes). D’autres variantes intègrent des encodeurs basés sur les Transformers, comme le TransUNet, pour capturer des dépendances à longue distance.
Cette évolution rapide montre pourquoi il est dangereux de se contenter de connaissances obsolètes. Ce qui était le “state-of-the-art” il y a trois ans est aujourd’hui une base de départ. Chez DATAROCKSTARS, notre approche pédagogique est centrée sur la compréhension des mécanismes évolutifs. Nous ne vous apprenons pas seulement à coder “le” U-Net, nous vous apprenons à comprendre pourquoi telle variante est meilleure dans tel contexte. Cette capacité d’analyse critique est ce qui vous permettra de rester à jour et pertinent dans votre carrière, en suivant l’évolution technologique plutôt que d’être dépassé par elle.
9. Les défis de l’entraînement : Augmentation de données et GPU
Entraîner un U-Net, surtout en 3D (pour des scanners volumétriques, par exemple), est une opération extrêmement coûteuse en ressources. Vous avez besoin de clusters de GPU puissants et d’une infrastructure de données capable de fournir les images sans interruption. L’augmentation de données est une étape indispensable pour éviter l’overfitting : vous devez créer des variantes de vos images (rotations, zooms, changements de contraste, bruit) à la volée pendant l’entraînement.
Pour les ingénieurs DATAROCKSTARS, c’est un problème d’ingénierie système. Comment créer un pipeline qui génère ces augmentations sans ralentir le GPU ? Comment distribuer l’entraînement sur plusieurs GPU pour gagner du temps ? Dans notre Bootcamp Data Engineer & AIOps, nous traitons ces problématiques de performance de bout en bout. L’IA, ce n’est pas seulement le modèle, c’est tout l’écosystème qui le nourrit. Maîtriser le matériel et le pipeline de données est une compétence technique de très haut niveau, essentielle pour travailler dans les entreprises les plus avancées du secteur.
10. Le futur de la segmentation : Vers l’interprétabilité et l’IA générative
Le futur de la segmentation dépasse la simple sortie d’un masque. On commence à intégrer de l’interprétabilité : pourquoi le modèle segmente-t-il cette zone ? Quels sont les pixels qui ont le plus pesé dans la décision ? De plus, la frontière entre segmentation et génération s’efface. Des modèles peuvent désormais “remplir” les zones segmentées, ou proposer des variations de segmentation basées sur des incertitudes. Les modèles de segmentation deviennent de plus en plus interactifs, apprenant en temps réel de la correction humaine (Interactive Segmentation).
Cette convergence entre vision et langage, entre analyse et génération, est le nouveau terrain de jeu de l’IA. DATAROCKSTARS se tient à l’avant-garde de ces changements. En rejoignant nos cursus, vous ne vous contentez pas d’étudier les classiques comme le U-Net ; vous vous préparez à concevoir les systèmes de vision hybrides de demain. Vous ne serez pas juste des experts en Deep Learning, vous serez les architectes de la perception artificielle. N’attendez pas que le futur se construise sans vous. Souhaitez-vous découvrir comment notre Bootcamp Data Scientist & AI Engineer peut vous donner les clés pour dominer ces technologies et devenir un expert incontournable dans le domaine de la vision par ordinateur ?
Merci pour votre lecture ! Si vous souhaitez découvrir nos prochains articles autour de la Data et de l’IA, vous pouvez nous suivre sur Facebook, LinkedIn et Twitter pour être notifié dès la publication d’un nouvel article !