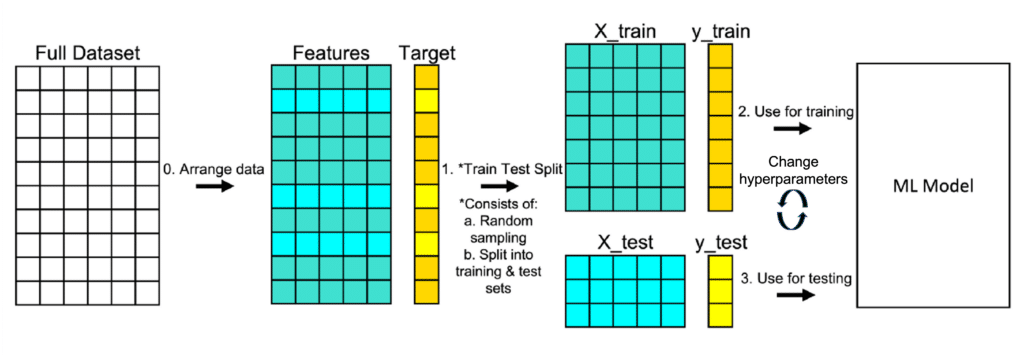
Dans le vaste écosystème de la science des données et de l’intelligence artificielle, l’objectif ultime n’est jamais de concevoir un modèle qui connaît vos données d’entraînement par cœur. L’objectif est de construire une intelligence artificielle capable de généraliser, c’est-à-dire de performer avec précision sur des données qu’elle n’a jamais vues auparavant. C’est ici qu’intervient le train_test_split. Cette procédure, simple en apparence mais d’une importance capitale, consiste à diviser votre jeu de données initial en deux sous-ensembles distincts : l’ensemble d’entraînement et l’ensemble de test. Cette séparation physique est le seul moyen de mesurer de manière objective la capacité prédictive de votre modèle et de détecter le phénomène redouté de l’overfitting (surapprentissage).
Pour les ingénieurs formés au sein de notre Bootcamp Data Scientist & AI, le train_test_split n’est pas qu’une fonction importée de Scikit-Learn ; c’est un protocole de rigueur scientifique. Ignorer cette étape ou mal l’exécuter, c’est construire un système d’information bancal qui risque de s’effondrer dès son déploiement sur le Cloud Computing. Dans cet article, nous allons explorer en profondeur les fondements théoriques, les mécanismes techniques et les pièges cachés derrière ce concept, afin de vous garantir une expertise robuste dans vos projets de modélisation les plus ambitieux.
1. La philosophie de la généralisation en machine learning
La généralisation est le concept qui sépare une simple mémorisation statistique d’une réelle intelligence prédictive. Lorsque vous entraînez un modèle, vous lui donnez accès à un patrimoine informationnel riche. Si le modèle est trop complexe ou si les données sont trop peu nombreuses, il risque de mémoriser le “bruit” des données au lieu de comprendre les relations sous-jacentes. C’est l’overfitting. À l’inverse, s’il est trop simple, il fera de l’underfitting, passant à côté des signaux importants. Le train_test_split est le test de vérité : il simule l’avenir du modèle en le confrontant à des données “inconnues” (le jeu de test).
Chez DATAROCKSTARS, nous enseignons que la performance ne se mesure jamais sur le set d’entraînement. C’est une erreur de débutant. La performance se mesure sur le set de test. En séparant les données, vous créez une barrière étanche entre l’apprentissage et l’évaluation. Cette étanchéité est le fondement de la confiance que vous pouvez accorder à vos prédictions. Sans cette séparation, vos métriques d’évaluation sont biaisées, optimistes et, en fin de compte, inutiles pour un décideur métier. Comprendre cette philosophie est le premier pas pour passer d’un pratiquant de tutoriels à un véritable architecte de solutions d’intelligence artificielle.
2. Le mécanisme technique du fractionnement des données
Techniquement, la procédure de train_test_split dans Scikit-Learn est conçue pour être à la fois flexible et déterministe. Elle effectue deux opérations majeures : le mélange (shuffling) et le découpage (splitting). Le mélange est crucial car, souvent, les données brutes sont ordonnées (par exemple, par date, par ID utilisateur ou par catégorie). Si vous ne mélangez pas les données, votre jeu de test pourrait ne contenir qu’une seule catégorie, ce qui rendrait votre évaluation totalement non représentative. Le train_test_split assure que la distribution des données dans les sets d’entraînement et de test est aléatoire.
Le paramètre random_state est un élément essentiel de cette mécanique. Il permet de fixer la graine du générateur de nombres aléatoires. Pourquoi est-ce vital ? Pour la reproductibilité. Si vous ne fixez pas le random_state, chaque exécution de votre code produira un split différent, ce qui rendra la comparaison entre deux versions de votre modèle impossible. Chez DATAROCKSTARS, nous insistons sur la rigueur scientifique : chaque expérience doit être reproductible. C’est une compétence qui se traduit directement dans vos projets de Data Engineer & AIOps, où la gestion des versions de vos datasets est aussi importante que la gestion du code lui-même.
3. Choisir le ratio idéal : L’art du compromis
Quel ratio choisir pour son train_test_split ? 80/20 ? 70/30 ? 90/10 ? Il n’y a pas de réponse universelle, car le choix dépend de la taille de votre jeu de données total. Si vous disposez de quelques centaines d’exemples seulement, un set de test de 30% pourrait priver le modèle de données critiques pour son apprentissage. Si vous disposez de millions d’exemples, un set de test de 1% peut suffire pour obtenir une évaluation statistique très robuste. La règle d’or est la représentativité statistique.
Le compromis réside dans le fait qu’il faut donner au modèle assez de données pour apprendre les motifs complexes (entraînement), tout en gardant assez de données pour évaluer ses erreurs sans que cette évaluation ne soit due au hasard (test). Dans nos formations, nous conseillons d’adopter des approches itératives. Si vous sentez que votre modèle est très instable lors de l’évaluation, c’est peut-être que votre set de test est trop petit. À l’inverse, si votre modèle performe bizarrement, vérifiez si votre set d’entraînement est suffisant pour capturer la diversité de la population réelle. La maîtrise de ces nuances est ce qui différencie un analyste qui applique des recettes de ceux qui comprennent la dynamique profonde de leur modèle.
4. La stratification : Un impératif pour les classes déséquilibrées
C’est ici que de nombreux débutants échouent. Dans les problèmes de classification, il arrive souvent qu’une classe soit très largement minoritaire (par exemple, la détection de fraudes bancaires ou de maladies rares). Si vous faites un train_test_split classique, vous courez le risque statistique que votre jeu de test ne contienne aucun exemple de la classe minoritaire. Votre modèle sera incapable d’apprendre cette classe, et votre évaluation sera vide de sens. La solution est la stratification (stratify=y dans Scikit-Learn).
La stratification force l’algorithme à conserver la même proportion de classes dans le jeu d’entraînement et dans le jeu de test que dans le dataset global. Si 5% de vos données sont des fraudes, la stratification garantit que 5% de votre set d’entraînement et 5% de votre set de test seront des fraudes. C’est un détail technique, mais c’est une différence fondamentale pour la crédibilité de votre modèle en production. Chez DATAROCKSTARS, nous intégrons la stratification comme une norme industrielle. Un modèle d’intelligence artificielle qui ne sait pas gérer les classes minoritaires est un modèle dangereux, car c’est précisément dans les cas limites que l’intelligence artificielle apporte le plus de valeur au système d’information.
5. Le jeu de validation : Vers une architecture à trois ensembles
Pour les projets avancés, le train_test_split binaire ne suffit plus. On passe alors à une architecture à trois ensembles : Entraînement, Validation et Test. Pourquoi ? Parce que pendant la phase d’entraînement, vous allez ajuster vos hyperparamètres (le taux d’apprentissage, la profondeur de l’arbre, la régularisation, etc.). Si vous utilisez votre jeu de test pour faire ces ajustements, vous risquez une forme de “triche” : vous apprenez indirectement le jeu de test.
L’ensemble de validation sert à comparer différentes configurations de votre modèle pendant le processus de développement. L’ensemble de test, lui, reste “sous scellé” jusqu’à la toute fin du projet. Il n’est utilisé qu’une seule fois, au moment de livrer la performance finale du modèle. C’est cette rigueur qui garantit que vos prédictions en production ne seront pas une déception. Dans nos cursus de Data Science, nous modélisons ces pipelines de validation pour vous apprendre à bâtir des systèmes d’IA de classe entreprise. La gestion de ces trois ensembles est le signe distinctif d’un Data Scientist qui pense à la mise en production (AIOps) dès le premier jour de son projet.
6. La Cross-Validation : La méthode robuste pour les petits datasets
Que faire si votre dataset est minuscule ? Si vous faites un split fixe, le résultat de votre évaluation dépendra de la chance de votre tirage aléatoire. C’est là qu’intervient la Cross-Validation (validation croisée). Au lieu d’un seul split, vous divisez vos données en K blocs (par exemple K=5). Vous entraînez le modèle 5 fois, chaque fois en utilisant un bloc différent comme jeu de test et les 4 autres comme jeu d’entraînement. Vous faites ensuite la moyenne des scores obtenus.
La Cross-Validation est beaucoup plus robuste qu’un simple train_test_split, car elle utilise chaque donnée du dataset pour l’entraînement et pour le test. C’est la méthode de référence dans les compétitions Kaggle ou dans la recherche académique. Chez DATAROCKSTARS, nous apprenons à nos étudiants à automatiser ces processus avec des bibliothèques puissantes. La robustesse statistique n’est pas optionnelle, surtout lorsque les décisions prises par l’IA ont des conséquences économiques ou sécuritaires importantes. Maîtriser la Cross-Validation, c’est s’assurer que votre modèle n’est pas le fruit d’une coïncidence statistique.
7. Les pièges du Data Leakage (Fuite de données)
Le “Data Leakage” est le péché mortel de la science des données, et le train_test_split est souvent l’endroit où cela arrive. Le leakage se produit lorsque des informations du set de test “fuient” par inadvertance dans le set d’entraînement. Par exemple, si vous normalisez vos données (ex: calculer la moyenne) sur l’ensemble du dataset avant de faire le split, vous transférez une information sur la distribution du set de test vers le set d’entraînement. C’est une fuite subtile mais fatale.
Une autre forme de leakage courant est le traitement des séries temporelles. Si vous mélangez aléatoirement des données qui ont une composante temporelle, vous faites en sorte que le modèle “voit le futur” pendant son entraînement. Dans nos formations en cybersécurité et en data engineering, nous apprenons à identifier et bloquer ces fuites. Un ingénieur DATAROCKSTARS sait qu’un modèle qui semble trop parfait (ex: 99.9% de précision) est souvent le symptôme d’un leakage. Apprendre à traquer ces anomalies est une compétence d’expert qui protège l’intégrité de votre système d’information.
8. Le défi des séries temporelles : splitting temporel vs aléatoire
Comme mentionné brièvement, les données temporelles exigent une approche radicalement différente. Dans une série temporelle (ventes quotidiennes, prix d’actions, logs système), l’ordre a une importance cruciale. Si vous faites un train_test_split aléatoire, vous mélangez le futur avec le passé. Le modèle apprendra le futur et essaiera de l’appliquer pour prédire le passé. C’est une aberration logique.
Pour les séries temporelles, on utilise un “Time Series Split” : vous entraînez sur les données du passé et vous testez sur les données qui suivent chronologiquement. Vous avancez comme une fenêtre glissante. Chez DATAROCKSTARS, nous insistons sur la nature des données avant de décider du split. Un Data Engineer doit être capable d’identifier immédiatement si ses données sont indépendantes et identiquement distribuées (IID) ou si elles possèdent une dépendance temporelle. Cette distinction est cruciale pour le succès de vos modèles, qu’il s’agisse de maintenance prédictive dans une usine ou de détection d’intrusions réseau pour un projet de cybersécurité.
9. Infrastructure et scalabilité : Le split à l’ère du Big Data
Lorsque vous travaillez avec plusieurs téraoctets de données sur des clusters Hadoop ou Spark, le train_test_split local n’est plus possible. Vous ne pouvez pas charger tout le dataset en mémoire pour le mélanger. Les ingénieurs doivent alors utiliser des techniques de partitionnement distribué. Dans Spark, cela implique de gérer le partitionnement des RDD ou DataFrames pour assurer que le split soit effectué de manière cohérente à travers les nœuds du cluster.
C’est là que le métier de Data Engineer, tel qu’enseigné dans notre Bootcamp Data Engineer & AIOps, devient critique. Vous devez concevoir des pipelines où le split fait partie intégrante du flux de données. Vous ne voulez pas faire de copie inutile de données. Vous voulez un split logique qui soit “lazy” (paresseux) : le calcul du split ne doit se faire que lors de l’exécution du calcul. Cette vision orientée infrastructure est ce qui permet à nos diplômés de travailler sur des systèmes de production mondiaux où la moindre inefficacité dans la gestion de la mémoire se traduit par des coûts cloud astronomiques.
10. Vers des split automatisés et l’IA générative
Avec l’arrivée de l’IA générative et des plateformes d’AutoML, le train_test_split tend à devenir une étape automatisée et transparente pour l’utilisateur final. Les plateformes modernes se chargent de la stratification, de la validation croisée et du monitoring de la dérive des données (data drift) sans intervention manuelle. Pourtant, cette automatisation cache une complexité que l’expert ne doit pas ignorer.
L’expert DATAROCKSTARS est celui qui peut auditer ces systèmes automatisés. Savoir ce qui se passe “sous le capot” du split automatisé est essentiel pour ne pas se laisser enfermer dans des boîtes noires. Si votre modèle échoue, vous devez être capable de revenir aux fondamentaux : est-ce que mon split était biaisé ? Est-ce que j’ai une fuite de données ? Comprendre le train_test_split restera une compétence fondamentale, car c’est la seule façon de maintenir un contrôle total sur la qualité de votre intelligence artificielle. La maîtrise de cet outil est le gage d’une carrière durable. Rejoignez nos cursus pour apprendre à maîtriser ces fondations et devenir un architecte de la donnée autonome et compétent. Souhaitez-vous découvrir comment notre Bootcamp Data Scientist & AI peut vous donner cette profondeur technique indispensable pour propulser vos projets vers l’excellence ?
Merci pour votre lecture ! Si vous souhaitez découvrir nos prochains articles autour de la Data et de l’IA, vous pouvez nous suivre sur Facebook, LinkedIn et Twitter pour être notifié dès la publication d’un nouvel article !