Le système de fichiers distribué Hadoop, mieux connu sous l’acronyme HDFS, est l’une des inventions les plus marquantes dans l’histoire de l’informatique moderne. Avant son apparition, le stockage de données à grande échelle nécessitait des systèmes de stockage propriétaires, coûteux et incapables de monter en charge sans limites. HDFS a radicalement changé cette donne en proposant une architecture capable de stocker des pétaoctets de données sur des grappes (clusters) de serveurs standards, ou “commodity hardware”. Pour un ingénieur, comprendre HDFS, c’est comprendre la philosophie du calcul distribué. Ce n’est pas seulement un système de stockage ; c’est le socle fondamental sur lequel ont été construites les révolutions du Big Data, permettant l’analyse de flux informationnels globaux que nous traitons aujourd’hui avec l’intelligence artificielle.
Si l’industrie se tourne aujourd’hui vers le Cloud et les solutions de stockage objet, la logique HDFS imprègne encore toutes les architectures distribuées actuelles. Chez DATAROCKSTARS, nous enseignons que la donnée est le pétrole du 21ème siècle, mais que ce pétrole ne vaut rien s’il n’est pas stocké, accessible et protégé par une architecture résiliente. Que vous soyez un futur Data Engineer ou un expert en AIOps, maîtriser les concepts de distribution, de réplication et de cohérence des données que HDFS a popularisés est indispensable pour votre carrière. Cet article détaille, point par point, pourquoi HDFS demeure un sujet d’étude crucial pour tout architecte système souhaitant construire des solutions pérennes en 2026.
1. L’architecture fondamentale et le concept de distribution des données
L’architecture de HDFS repose sur un principe simple mais puissant : la division des fichiers volumineux en morceaux de taille fixe, appelés “blocs”. Par défaut, ces blocs font 128 Mo, mais ils peuvent être ajustés selon les besoins de vos applications. Cette fragmentation permet de distribuer les données à travers tout un cluster, rendant le stockage de fichiers gigantesques possible sur des machines individuelles qui n’auraient jamais pu les contenir autrement. La beauté de cette approche est qu’elle transforme un ensemble de machines disparates en un seul espace de nommage global. C’est ce qu’on appelle la transparence de localisation : pour l’utilisateur, HDFS ressemble à un système de fichiers classique, mais en coulisses, les données sont éparpillées sur des dizaines, voire des centaines de serveurs.
Pour les apprenants du Bootcamp Data Scientist & AI, cette architecture est le premier contact avec la notion de parallélisme. Au lieu de traiter un fichier en entier sur un seul processeur, on distribue les blocs de données pour permettre un traitement parallèle. C’est cette capacité qui permet de réduire les temps de traitement de plusieurs jours à quelques minutes. La gestion de cette distribution est gérée par des composants logiciels spécifiques dont l’interaction est le garant de la cohérence globale de votre patrimoine informationnel. L’architecture de HDFS est pensée pour le débit (throughput), privilégiant la lecture massive de données à la latence d’accès, ce qui en fait l’outil parfait pour le traitement par lots (batch processing) et les modèles de Deep Learning gourmands en données.
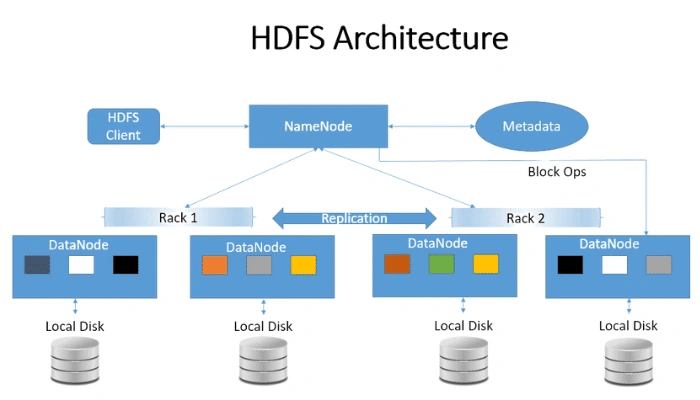
2. Le fonctionnement du NameNode et des DataNodes
Le fonctionnement de HDFS est orchestré par deux types de nœuds : le NameNode et les DataNodes. Le NameNode est le cerveau du système. Il maintient l’arborescence des fichiers, les métadonnées (qui possède quel fichier, quels sont les droits, où sont stockés les blocs) et gère l’état global du cluster. Il ne stocke pas les données réelles des fichiers, mais uniquement les informations de localisation. À l’inverse, les DataNodes sont les “bras” du système. Ils sont dispersés sur les différentes machines du cluster et assurent le stockage effectif des blocs de données. Ils sont également responsables de la lecture et de l’écriture de ces blocs, ainsi que des opérations de réplication, de création et de suppression ordonnées par le NameNode.
La communication entre ces composants est constante. Les DataNodes envoient régulièrement des rapports de santé (heartbeats) et des rapports de blocs au NameNode pour signaler leur activité et l’état des données qu’ils contiennent. Si un DataNode tombe en panne, le NameNode le détecte immédiatement et ordonne aux autres DataNodes de répliquer les données manquantes pour maintenir le facteur de réplication souhaité. Cette séparation des responsabilités entre métadonnées (NameNode) et données brutes (DataNodes) est une architecture classique qui a fait ses preuves en termes de robustesse. Cependant, cette centralisation des métadonnées sur le NameNode est aussi un point d’attention : c’est le point unique de défaillance. Chez DATAROCKSTARS, nous formons nos Data Engineers à mettre en place des mécanismes de haute disponibilité pour le NameNode, afin que votre infrastructure reste invincible face aux pannes matérielles.
3. La stratégie de réplication et la tolérance aux pannes
La tolérance aux pannes est l’ADN de HDFS. Dans un environnement distribué, la panne matérielle n’est pas une exception, c’est une certitude statistique. Le nombre de composants matériels étant très élevé, la probabilité qu’au moins un disque ou un serveur tombe en panne à un instant T est quasi de 100%. HDFS gère cela par la réplication. Lorsqu’un bloc est écrit, HDFS ne le stocke pas une seule fois, mais le réplique plusieurs fois (le facteur par défaut est de 3) sur différents nœuds.
Le placement de ces répliques suit une logique intelligente : la première réplique est placée sur le nœud local (si possible), la deuxième sur un autre nœud dans un rack différent, et la troisième sur un autre nœud dans ce même rack distant. Pourquoi cette complexité ? Pour se protéger contre la panne d’un rack entier (panne de switch ou d’alimentation électrique). Cette stratégie garantit que même si un serveur ou tout un rack s’éteint brutalement, les données restent accessibles et lisibles. C’est une résilience que nous analysons en profondeur dans nos cursus Data Engineer & AIOps. Pour un ingénieur, comprendre ce mécanisme est essentiel pour concevoir des systèmes de stockage où la perte de données est mathématiquement quasi impossible, ce qui est crucial lorsque vous manipulez les sets de données sensibles de vos modèles d’intelligence artificielle.
4. HDFS face aux systèmes de stockage objet dans le Cloud
L’arrivée du stockage objet dans le Cloud (comme Amazon S3, Google Cloud Storage ou Azure Blob Storage) a quelque peu bousculé le règne de HDFS. Contrairement à HDFS, le stockage objet ne gère pas de blocs et n’est pas un système de fichiers classique. Il expose une interface API (REST) pour stocker des objets. Ces systèmes sont extrêmement scalables, ne nécessitent aucune gestion de NameNode, et offrent une durabilité quasi infinie. Alors, HDFS est-il mort ? Loin de là. Si le stockage objet est supérieur pour le stockage à froid, le stockage de données hétérogènes ou les applications web, HDFS conserve un avantage compétitif majeur : la localité des données et la performance pour les accès intensifs.
Dans un cluster HDFS, le framework de calcul (comme Spark) peut souvent localiser la tâche de calcul sur la même machine que celle où réside le bloc de données. Cela élimine le goulot d’étranglement du réseau. Dans le stockage objet, la donnée est obligatoirement transférée sur le réseau. C’est pourquoi, pour les traitements de données à ultra-haute performance et les environnements de calcul distribué très intenses, HDFS reste une référence. La tendance actuelle, enseignée chez DATAROCKSTARS, est au “Data Lakehouse” : on utilise le stockage objet pour la persistance à long terme, mais on garde des mécanismes proches de HDFS pour le cache et les calculs distribués haute performance. Comprendre cette nuance est ce qui sépare un Data Architect junior d’un expert confirmé.
5. Intégration dans l’écosystème Hadoop et le calcul distribué
HDFS n’est que la couche de stockage de l’écosystème Hadoop. Il a été conçu pour fonctionner en parfaite synergie avec d’autres frameworks, notamment YARN (le gestionnaire de ressources) et MapReduce (le moteur de calcul originel). Aujourd’hui, MapReduce est largement remplacé par Apache Spark, qui est beaucoup plus rapide car il travaille en mémoire. Spark s’intègre nativement avec HDFS, permettant de charger des jeux de données gigantesques en quelques instants.
Cette intégration est le cœur de la productivité du Data Engineer. Vous pouvez utiliser Hive pour interroger vos données stockées dans HDFS avec du SQL, ou utiliser HBase pour avoir un accès en temps réel à ces mêmes données. Cet écosystème forme un socle cohérent et intégré. Dans notre Bootcamp Data Scientist & AI, nous mettons en pratique ces intégrations. Apprendre à orchestrer ces outils n’est pas seulement apprendre à configurer des logiciels ; c’est apprendre à bâtir une “usine à données”. Vous découvrez comment passer du fichier brut dans HDFS à la table SQL queryable via Hive, et enfin au modèle prédictif entraîné par Spark. C’est cette chaîne de valeur complète que nous transmettons pour préparer nos étudiants aux réalités complexes des entreprises.
6. Optimisation de la performance et gestion des blocs
La performance dans HDFS n’est pas magique, elle est le résultat d’une configuration rigoureuse. La taille des blocs est votre premier levier. Si vos fichiers sont très petits (quelques kilo-octets), vous allez saturer la mémoire vive du NameNode, car chaque bloc, quelle que soit sa taille, nécessite une entrée dans la table des métadonnées du NameNode. Une saturation du NameNode est la mort assurée des performances. À l’inverse, des blocs trop grands peuvent freiner le parallélisme. L’équilibre est crucial.
En tant qu’ingénieur formé chez DATAROCKSTARS, vous apprendrez à analyser la typologie de vos données pour ajuster ces paramètres. Nous abordons également les stratégies de “data balancing”. Avec le temps, les DataNodes peuvent devenir inégalement remplis, créant des disparités de performance. Le HDFS Balancer est l’outil indispensable pour redistribuer intelligemment les blocs et garantir une utilisation homogène de votre infrastructure. L’optimisation, c’est aussi savoir limiter le nombre de répliques pour les données non critiques et maximiser le débit réseau par des configurations de switchs appropriées. Ce travail d’ajustement fin, ou “tuning”, est ce qui transforme une infrastructure lente en une machine de guerre capable de traiter des téraoctets de logs en quelques minutes.
7. Sécurité et gouvernance du patrimoine informationnel
Sécuriser HDFS est une tâche complexe qui demande une approche multicouche. HDFS, par défaut, n’est pas conçu pour une sécurité forte ; il fait confiance aux clients. Pour le rendre sécurisé, il faut intégrer des composants comme Kerberos pour l’authentification (pour que les utilisateurs prouvent leur identité) et Apache Ranger pour le contrôle d’accès (pour définir qui peut lire ou écrire quel dossier). Ranger permet une gouvernance fine : vous pouvez décider que l’équipe Data Science a accès en lecture aux données de logs, mais que seuls les administrateurs peuvent modifier les données de transactions.
Cette gouvernance est essentielle en 2026. Avec les exigences croissantes des régulations (RGPD, NIS2, AI Act), vous ne pouvez plus laisser vos données circuler sans traçabilité. Chaque accès doit être journalisé, chaque modification doit être auditée. C’est une discipline que nous intégrons à tous nos programmes chez DATAROCKSTARS. Apprendre à sécuriser HDFS, c’est apprendre à sécuriser la fondation de vos projets d’intelligence artificielle. Si vos données d’entraînement sont corrompues ou volées, votre modèle IA est compromis. Nous formons des ingénieurs qui intègrent la sécurité dès l’architecture de leurs clusters.
8. La place de HDFS dans les architectures d’IA modernes
Où se situe HDFS dans le monde de l’IA générative et du Deep Learning ? On pourrait penser qu’ils sont éloignés. Pourtant, les modèles de fondation (LLMs) ont besoin de quantités massives de données textuelles pour leur entraînement. Ces datasets (comme le Common Crawl) sont souvent stockés sur des systèmes distribués de type HDFS ou stockage objet S3. HDFS offre une interface de lecture très rapide pour les serveurs de calcul qui effectuent l’entraînement des modèles.
Plus encore, pour les entreprises qui entraînent des modèles sur leurs propres données (Fine-tuning), HDFS sert de stockage pour ces données privées, garantissant que les données ne quittent jamais le périmètre sécurisé du réseau interne. Il sert de “Source of Truth” (Source de Vérité). Chez DATAROCKSTARS, nous montrons comment connecter vos clusters de calcul GPU directement à vos data lakes HDFS. C’est le pont entre l’ingénierie des données et la science des données. Savoir manipuler ces données au sein de HDFS pour les transformer en vecteurs, puis les stocker dans des bases de données vectorielles pour du RAG (Retrieval-Augmented Generation), est une compétence clé qui vous distinguera dans vos missions en entreprise. L’IA ne fonctionne que sur de la donnée propre et accessible : HDFS reste, pour beaucoup, le garant de cette accessibilité.
9. Stratégies de migration et modernisation des Data Lakes
De nombreuses entreprises se retrouvent aujourd’hui avec des clusters HDFS vieillissants, coûteux à maintenir et difficiles à faire évoluer. La tentation est forte de tout migrer vers le Cloud. Mais attention : une migration “lift and shift” (copier-coller) vers le Cloud peut s’avérer catastrophique sur le plan des coûts. Le stockage objet est peu cher, mais le transfert de données (egress) et les requêtes API peuvent chiffrer très vite. La modernisation d’un Data Lake HDFS demande une stratégie réfléchie.
Dans nos formations Data Engineer, nous analysons les scénarios de migration. Parfois, la solution optimale est hybride : garder les données froides sur S3 et utiliser un cluster HDFS pour le calcul intensif temporaire. Parfois, il faut migrer vers des solutions modernes de Data Lakehouse comme Databricks ou Snowflake qui offrent des performances proches de HDFS mais avec une gestion simplifiée. La compétence clé ici est l’analyse d’architecture. Vous devez être capable d’auditer l’existant, de quantifier les coûts, d’évaluer les performances et de proposer un chemin de migration qui respecte les contraintes budgétaires et techniques de votre organisation. C’est le rôle de l’architecte de données moderne, un rôle que nous préparons avec une approche pragmatique et orientée résultats.
10. Pourquoi maîtriser HDFS reste crucial pour votre carrière d’ingénieur
Malgré l’essor du tout-Cloud, HDFS n’a pas dit son dernier mot. La raison est simple : les concepts qu’il a introduits (distribution, réplication, cohérence, scalabilité horizontale) sont les fondements de tous les systèmes distribués modernes, qu’il s’agisse de bases de données NoSQL, de systèmes de messaging comme Kafka, ou même de l’architecture interne des services Cloud. Un ingénieur qui comprend HDFS comprend comment les données circulent dans les systèmes distribués à grande échelle. Il ne voit pas la donnée comme un fichier, mais comme un flux réparti qui doit être géré avec soin.
C’est une compétence qui vous donne une profondeur technique rare. Là où d’autres se contentent d’utiliser des outils de haut niveau, vous comprenez le “sous le capot”. Chez DATAROCKSTARS, nous formons des techniciens et des ingénieurs qui ne sont pas des utilisateurs de solutions prêtes à l’emploi, mais des bâtisseurs de solutions robustes. Votre maîtrise de ces concepts vous rendra précieux pour toute entreprise gérant des données à l’échelle, car vous serez ceux qui peuvent diagnostiquer les pannes les plus complexes, optimiser les performances les plus récalcitrantes et concevoir les architectures les plus résilientes. Le chemin vers l’expertise est exigeant, mais avec DATAROCKSTARS, vous avez le guide et les ressources nécessaires pour vous hisser parmi les meilleurs. Prêt à bâtir l’avenir de la donnée ? Découvrez notre Bootcamp Data Engineer & AIOps pour transformer votre expertise technique et propulser votre carrière.
Merci pour votre lecture ! Si vous souhaitez découvrir nos prochains articles autour de la Data et de l’IA, vous pouvez nous suivre sur Facebook, LinkedIn et Twitter pour être notifié dès la publication d’un nouvel article !