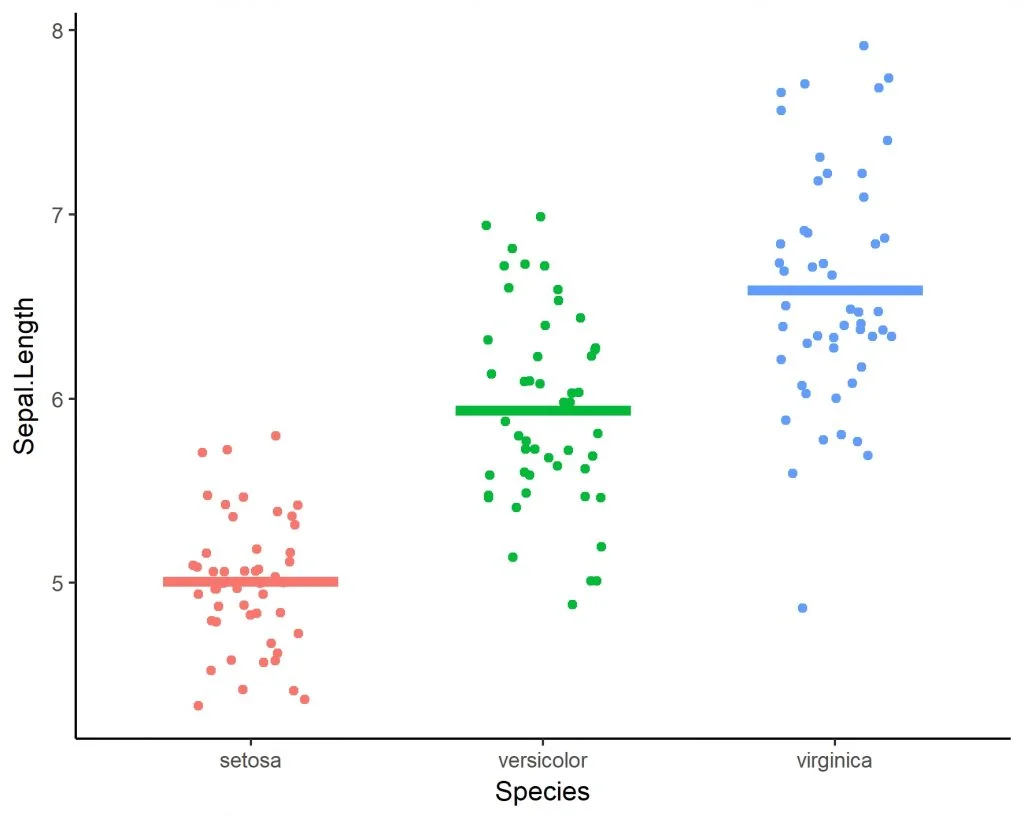
Le test anova (ANalyse Of VAriance) est une technique statistique utilisée pour déterminer s’il existe des différences significatives entre les moyennes de trois groupes indépendants ou plus. Contrairement au test de Student (t-test) qui se limite à deux groupes, l’ANOVA permet de traiter des structures de données plus larges sans multiplier le risque d’erreur. Dans un système d’information décisionnel, elle est le pivot indispensable pour valider l’impact d’une variable qualitative sur une variable quantitative, comme l’effet de différentes stratégies marketing sur le chiffre d’affaires stocké sur le Cloud Computing.
Pour les talents formés chez DATAROCKSTARS, maîtriser le test anova est essentiel pour garantir la rigueur des conclusions scientifiques. Que vous soyez futur Data Scientist ou analyste en Business Intelligence, comprendre la décomposition de la variance est une compétence clé des métiers data qui recrutent.
1. Principe fondamental de l’Analyse de la Variance
L’ANOVA repose sur une idée simple : pour savoir si les moyennes des groupes sont différentes, on compare la variabilité entre les groupes à la variabilité au sein des groupes. Si la variation entre les groupes est nettement supérieure à la variation interne, on conclut que les groupes ne sont pas issus de la même population. Ce traitement du patrimoine informationnel permet au système d’information de distinguer les vrais signaux du bruit aléatoire sur le Cloud Computing.
2. Les hypothèses de base du test
Pour que le test anova soit valide, trois conditions doivent être remplies au sein de votre patrimoine informationnel :
- Indépendance : les observations doivent être indépendantes les unes des autres.
- Normalité : les données de chaque groupe doivent suivre une loi normale.
- Homoscédasticité : les variances des groupes doivent être approximativement égales (test de Levene).Le respect de ces critères garantit la fiabilité du système d’information et la précision de la Data Science appliquée.
3. Comprendre la statistique F (F-Value)
Le résultat principal de l’ANOVA est la statistique F, qui est le rapport des variances. Mathématiquement, elle s’exprime ainsi :
F = (Variance entre les groupes) / (Variance à l’intérieur des groupes)
Une valeur F élevée, associée à une p-value faible (généralement $< 0,05$), indique que vous pouvez rejeter l’hypothèse nulle ($H_0$) au sein de votre système d’information. Cela prouve qu’au moins une moyenne de votre patrimoine informationnel est statistiquement différente des autres sur le Cloud Computing.
4. ANOVA à un facteur (One-Way ANOVA)
Il s’agit de la forme la plus courante du test, où l’on étudie l’effet d’une seule variable explicative (le facteur) sur une variable cible. Par exemple, tester si le temps passé sur un site web dépend du navigateur utilisé. Cette analyse simple du patrimoine informationnel technique est un aspect vital pour tout savoir sur l’optimisation de l’expérience utilisateur au sein du système d’information.
5. ANOVA à deux facteurs (Two-Way ANOVA)
L’ANOVA à deux facteurs permet d’étudier simultanément l’influence de deux variables indépendantes et leur éventuelle interaction. On peut ainsi analyser l’effet combiné de la région et du type de produit sur les ventes. Cette approche multidimensionnelle du Data Management offre une vision plus riche du patrimoine informationnel stratégique hébergé sur le Cloud Computing.
6. L’importance de l’interaction entre les facteurs
Dans une ANOVA à deux facteurs, l’interaction se produit lorsque l’effet d’un facteur dépend du niveau de l’autre. Comprendre ces interactions est crucial pour la Data Science complexe. Si le système d’information détecte une interaction significative, cela signifie que le patrimoine informationnel ne peut pas être analysé de manière isolée, demandant une expertise plus poussée sur le Cloud Computing.
7. Tests Post-Hoc (Tukey, Bonferroni)
L’ANOVA vous dit s’il y a une différence, mais elle ne vous dit pas où elle se trouve. Pour identifier précisément quels groupes diffèrent, on réalise des tests Post-Hoc. Ces tests ajustent le patrimoine informationnel pour éviter l’inflation du risque d’erreur. C’est une étape indispensable de la Business Intelligence pour transformer un résultat global en une action concrète au sein du système d’information.
8. Logiciels et bibliothèques pour l’ANOVA
En 2026, le calcul du test anova est automatisé. Le langage Python propose des bibliothèques puissantes comme SciPy ou Statsmodels. Ces outils permettent d’intégrer des analyses statistiques dans vos Agents IA & Automations, facilitant la validation continue du patrimoine informationnel technique sur le Cloud Computing.
9. Interprétation des résultats et prise de décision
Un résultat de test anova doit toujours être interprété avec prudence. Une p-value significative ne signifie pas nécessairement que la différence est importante en pratique (taille de l’effet). Le Data Management doit donc coupler les statistiques à une connaissance métier pour valoriser intelligemment le patrimoine informationnel au sein du système d’information.
10. L’avenir de l’ANOVA et l’intelligence artificielle
Bien que l’ANOVA soit une méthode classique, elle reste la base de l’expérimentation moderne (A/B testing à grande échelle). L’intelligence artificielle utilise désormais des variantes de l’ANOVA pour expliquer la variance des modèles de Deep Learning. Le patrimoine informationnel est ainsi décortiqué pour garantir la transparence du système d’information et la robustesse de l’intelligence artificielle sur le Cloud Computing.
Le test anova est l’outil de référence pour valider vos hypothèses de comparaison. Posséder cette maîtrise technique permet de sécuriser vos conclusions, d’optimiser vos processus et de valoriser le patrimoine informationnel de votre entreprise. C’est la compétence pivot qui transforme une simple observation en une preuve statistique irréfutable.
Chez DATAROCKSTARS, nous vous formons à la rigueur de l’analyse statistique. En rejoignant nos cursus, vous apprenez à manipuler les tests complexes, à interpréter les résultats avec précision et à bâtir des solutions d’intelligence artificielle fondées sur un socle mathématique solide.
Souhaitez-vous découvrir comment notre formation Data Scientist & AI Engineer peut vous aider à maîtriser le test ANOVA pour propulser vos projets de recherche ?
Merci pour votre lecture ! Si vous souhaitez découvrir nos prochains articles autour de la Data et de l’IA, vous pouvez nous suivre sur Facebook, LinkedIn et Twitter pour être notifié dès la publication d’un nouvel article !