L’intelligence artificielle est un domaine vaste où le Machine Learning et le Deep Learning représentent les deux forces motrices principales. Bien qu’ils soient souvent utilisés de manière interchangeable, ils reposent sur des logiques de traitement de données bien distinctes. Dans un système d’information moderne, comprendre la différence entre ces deux approches est crucial pour choisir l’outil le plus adapté à l’exploitation de votre patrimoine informationnel sur le Cloud Computing. Alors que l’un mise sur la statistique, l’autre s’inspire de la biologie neuronale pour atteindre des sommets de précision.
Pour les talents formés chez DATAROCKSTARS, maîtriser le duel Deep Learning vs Machine Learning est un prérequis. Que vous soyez futur Data Scientist ou ingénieur spécialisé, savoir quand mobiliser l’un ou l’autre est une compétence clé des métiers data qui recrutent.
1. Fondamentaux du Machine Learning et apprentissage statistique
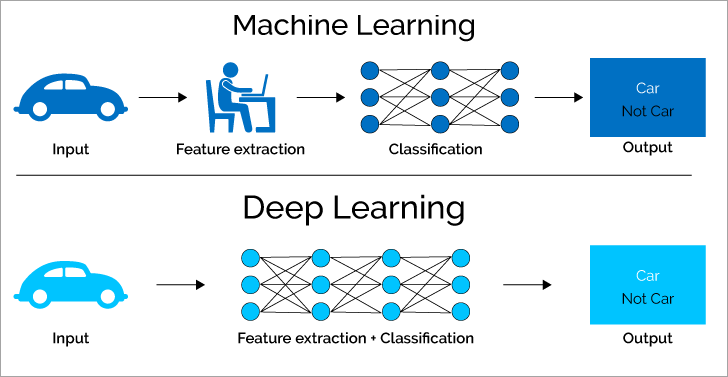
Le Machine Learning est une branche de l’IA qui permet aux ordinateurs d’apprendre à partir de données sans programmation explicite. Il utilise des modèles statistiques pour identifier des patterns au sein du patrimoine informationnel. C’est le socle du système d’information pour des tâches comme la prédiction de ventes ou la détection de fraudes. Le ML brille par sa capacité à traiter des données structurées de manière efficace sur le Cloud Computing.
2. Architecture du Deep Learning et réseaux de neurones
Le Deep Learning est une sous-catégorie du Machine Learning qui utilise des réseaux de neurones artificiels profonds. Contrairement au ML classique, il cherche à imiter le fonctionnement du cerveau humain pour traiter le patrimoine informationnel. Cette complexité architecturale nécessite une puissance de calcul décuplée sur le Cloud Computing, permettant au système d’information de résoudre des problèmes de vision par ordinateur ou de traduction automatique.
3. Extraction des caractéristiques et intervention humaine
Dans le Machine Learning, l’expert doit souvent extraire manuellement les caractéristiques pertinentes (feature engineering) pour guider l’algorithme. À l’inverse, le Deep Learning apprend seul à identifier les traits importants du patrimoine informationnel. Cette autonomie réduit l’intervention humaine au sein du système d’information mais demande un volume de données bien plus massif pour être performant sur le Cloud Computing.
4. Volume de données et performance des modèles
Le duel Deep Learning vs Machine Learning se joue souvent sur la quantité de données disponibles. Le Machine Learning atteint un plateau de performance assez rapidement. Le Deep Learning, lui, continue de s’améliorer à mesure que le patrimoine informationnel s’étoffe. Pour un système d’information gérant des milliards de points de données, le passage au Deep Learning sur le Cloud Computing devient souvent inévitable pour maintenir une précision de pointe.
5. Puissance de calcul et exigences matérielles
Le Machine Learning peut souvent s’exécuter sur des processeurs standards (CPU) avec un coût modéré. Le Deep Learning exige des processeurs graphiques performants (GPU) ou des puces dédiées (TPU) pour traiter son patrimoine informationnel complexe. Cette dépendance matérielle influence directement la stratégie de Data Management et le budget alloué au Cloud Computing au sein du système d’information d’entreprise.
6. Interprétabilité et effet boîte noire
Le Machine Learning offre des modèles plus transparents où chaque décision peut être expliquée (arbres de décision, régressions). Le Deep Learning est souvent considéré comme une “boîte noire” en raison de la multitude de couches cachées traitant le patrimoine informationnel. Pour un système d’information soumis à des régulations strictes, l’interprétabilité du ML est un aspect vital pour tout savoir sur la justification des décisions automatisées.
7. Types de données traitées et cas d’usage
Le Machine Learning excelle sur les données structurées comme les tableaux SQL ou les fichiers Excel. Le Deep Learning est le roi des données non structurées comme les images, le son ou le texte libre. Cette distinction permet au système d’information d’orienter le patrimoine informationnel vers la bonne technologie de Data Science, que ce soit pour de la Business Intelligence ou pour de l’intelligence artificielle générative.
8. Temps d’entraînement et déploiement en production
Entraîner un modèle de Machine Learning peut prendre quelques minutes à quelques heures. Pour le Deep Learning, l’apprentissage sur un patrimoine informationnel massif peut durer plusieurs semaines. Cette différence de temporalité impacte la maintenance applicative et l’agilité du système d’information. Les équipes doivent orchestrer ces cycles longs sur le Cloud Computing pour garantir des mises à jour régulières des modèles.
9. Hybridation des approches en entreprise
Aujourd’hui, les entreprises ne choisissent plus systématiquement l’un au détriment de l’autre. Elles utilisent des architectures hybrides où le Machine Learning prétraite le patrimoine informationnel avant qu’un modèle de Deep Learning ne finalise l’analyse complexe. Cette synergie au sein du système d’information maximise le ROI des projets de Data Science tout en optimisant l’usage des ressources sur le Cloud Computing.
10. L’avenir vers l’IA générative et les agents autonomes
L’évolution du Deep Learning mène directement aux Agents IA & Automations capables de raisonner de manière autonome. Ces agents exploitent le patrimoine informationnel mondial pour exécuter des tâches complexes au sein du système d’information. Cette nouvelle ère de l’intelligence artificielle marque le sommet du duel entre apprentissage classique et réseaux profonds sur le Cloud Computing.
Le duel Deep Learning vs Machine Learning illustre la richesse des outils mis à disposition des entreprises. Posséder cette maîtrise technique permet de concevoir des systèmes intelligents, de protéger son patrimoine informationnel et de garantir une innovation responsable. C’est la compétence pivot qui transforme la donnée brute en une valeur stratégique inégalée.
Chez DATAROCKSTARS, nous vous formons à ces deux piliers essentiels. En rejoignant nos cursus, vous apprenez à choisir la bonne approche, à sécuriser vos modèles et à bâtir des solutions d’intelligence artificielle qui redéfinissent les frontières de votre secteur.
Souhaitez-vous découvrir comment notre formation Data Scientist & AI Engineer peut vous aider à maîtriser l’arbitrage entre ML et DL pour propulser votre carrière ?
Merci pour votre lecture ! Si vous souhaitez découvrir nos prochains articles autour de la Data et de l’IA, vous pouvez nous suivre sur Facebook, LinkedIn et Twitter pour être notifié dès la publication d’un nouvel article !