Le coefficient de corrélation linéaire (souvent noté $r$ ou coefficient de Pearson) est une valeur numérique qui exprime l’intensité et la direction de la relation linéaire entre deux variables continues. Dans un système d’information moderne, il est le pivot indispensable pour identifier des tendances et des causalités potentielles au sein du patrimoine informationnel. Que vous analysiez le lien entre le budget publicitaire et les ventes ou entre la température et la consommation d’énergie sur le Cloud Computing, ce coefficient permet de quantifier mathématiquement ce que l’œil ne fait qu’entrevoir sur un graphique. C’est un outil de base du Data Management pour valider la pertinence des variables avant d’entraîner des modèles de Data Science.
Pour les talents formés chez DATAROCKSTARS, la maîtrise de la corrélation est le premier pas vers la modélisation. Que vous soyez futur Data Scientist ou Analyste financier, interpréter ce coefficient est une compétence clé des métiers data qui recrutent.
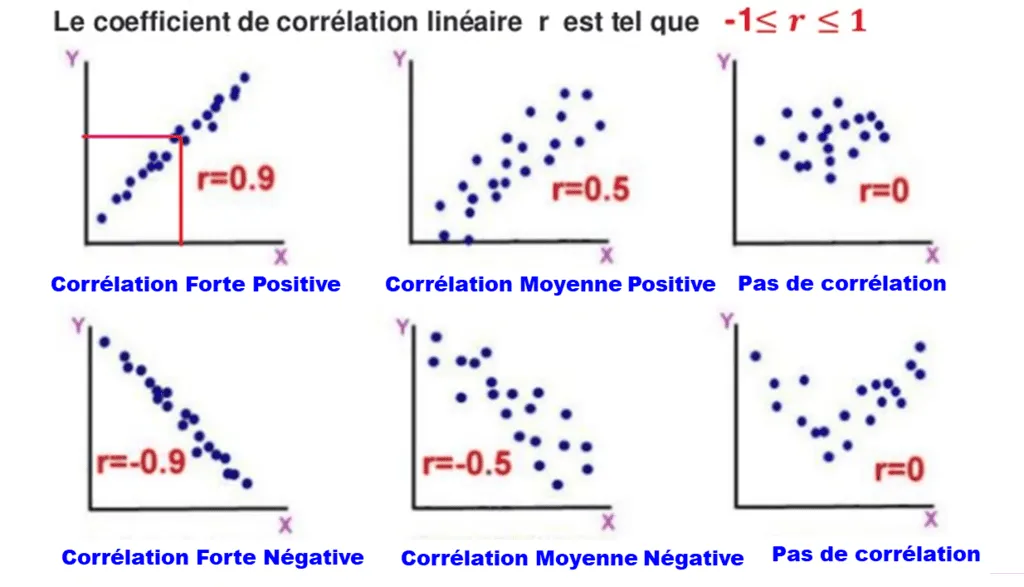
1. L’échelle de valeur : de -1 à +1
Le coefficient de corrélation se situe toujours dans l’intervalle $[-1, 1]$. Une valeur de $+1$ indique une corrélation positive parfaite, tandis que $-1$ indique une corrélation négative parfaite. Une valeur proche de $0$ signifie qu’il n’existe aucune relation linéaire entre les variables. Comprendre cette échelle est un aspect vital pour tout savoir sur la fiabilité de vos données : elle permet de filtrer le bruit au sein du patrimoine informationnel pour ne retenir que les signaux forts du système d’information.
2. Corrélation positive vs Corrélation négative
Une corrélation est dite “positive” lorsque les deux variables évoluent dans le même sens (si $X$ augmente, $Y$ augmente). Elle est “négative” lorsqu’elles évoluent en sens inverse (si $X$ augmente, $Y$ diminue). Dans le cadre du Data Management, identifier une corrélation négative peut être aussi précieux qu’une positive, par exemple pour détecter une baisse de satisfaction client liée à l’augmentation du temps d’attente, une donnée cruciale sur le Cloud Computing.
3. La force de la relation (Faible, Modérée, Forte)
Au-delà du signe, c’est la valeur absolue qui indique la force du lien. En général, un coefficient supérieur à $0,7$ est considéré comme fort, tandis qu’en dessous de $0,3$, la relation est jugée faible. Pour la Data Science, cette mesure permet de sélectionner les “features” (caractéristiques) les plus impactantes pour les algorithmes d’intelligence artificielle, optimisant ainsi la précision du patrimoine informationnel prédictif de l’entreprise.
4. Corrélation n’est pas Causalité
C’est le piège le plus célèbre en statistique : deux variables peuvent être fortement corrélées sans que l’une ne soit la cause de l’autre (variable cachée). Par exemple, les ventes de glaces et les coups de soleil sont corrélés, mais l’un ne cause pas l’autre ; c’est la chaleur qui cause les deux. Garder cette distinction à l’esprit est crucial pour la Business Intelligence, évitant des décisions stratégiques erronées basées sur une mauvaise interprétation du patrimoine informationnel.
5. La Matrice de Corrélation
Dans un projet de Data Science comportant des dizaines de variables, on utilise une matrice de corrélation pour visualiser tous les liens simultanément. Souvent représentée sous forme de “Heatmap” (carte de chaleur), elle permet de détecter instantanément les redondances au sein du patrimoine informationnel technique. Cette vue d’ensemble sur le Cloud Computing facilite la maintenance applicative des modèles en éliminant les variables colinéaires qui alourdissent le système d’information.
6. Sensibilité aux valeurs aberrantes (Outliers)
Le coefficient de Pearson est extrêmement sensible aux valeurs extrêmes. Un seul point très éloigné de la tendance peut faire chuter ou exploser le coefficient artificiellement. Un bon Data Management nécessite donc un nettoyage préalable du patrimoine informationnel. Identifier et traiter ces anomalies est un aspect vital pour tout savoir sur l’intégrité de vos analyses au sein du système d’information.
7. Limite de la linéarité : le cas des relations non linéaires
Le coefficient de corrélation linéaire ne détecte, comme son nom l’indique, que les relations en ligne droite. Si la relation est courbe (parabolique ou exponentielle), le coefficient peut être proche de $0$ alors qu’un lien fort existe. Pour contourner cela, les experts en Data Science utilisent d’autres mesures comme le coefficient de Spearman. Cette nuance technique est essentielle pour ne pas passer à côté de découvertes majeures cachées dans le patrimoine informationnel.
8. Utilisation dans le langage Python (Pandas & Seaborn)
En 2026, calculer un coefficient de corrélation se fait en une ligne de code avec la fonction .corr() de Pandas. Couplé à Seaborn pour la visualisation, le langage Python transforme des milliards de lignes stockées sur le Cloud Computing en insights visuels immédiats. Cette automatisation de la Business Intelligence permet de surveiller la santé du système d’information et les performances du patrimoine informationnel en temps réel.
9. Corrélation et Cybersécurité
En cybersécurité, l’analyse de corrélation est utilisée pour détecter des attaques complexes (SIEM). En corrélant des événements apparemment isolés (échec de connexion, scan de port, pic de CPU) au sein du patrimoine informationnel, le système d’information peut identifier une tentative d’intrusion. Cette application de la Data Science protège les actifs numériques sur le Cloud Computing par une surveillance intelligente des relations logiques.
10. L’avenir : Corrélation dynamique et IA
Les Agents IA & Automations sont désormais capables de surveiller les coefficients de corrélation en continu. Si un lien historique entre deux variables du patrimoine informationnel se rompt soudainement, l’IA génère une alerte. Cette détection de “dérive de données” (data drift) marque le sommet du Data Management moderne, assurant que le système d’information reste toujours aligné sur la réalité changeante du marché.
Le coefficient de corrélation linéaire est le thermomètre de la donnée. Posséder cette maîtrise technique permet de valider vos hypothèses, de sécuriser vos modèles et de valoriser votre patrimoine informationnel avec une rigueur scientifique. C’est la compétence pivot qui transforme une intuition floue en une certitude statistique pour l’entreprise.
Chez DATAROCKSTARS, nous vous formons à cette excellence analytique. En rejoignant nos cursus, vous apprenez à dompter les statistiques, à automatiser vos analyses et à bâtir des solutions d’intelligence artificielle fondées sur des bases mathématiques irréprochables. Ne vous contentez pas d’observer les données, apprenez à mesurer leurs liens pour devenir un leader de la révolution technologique.
Aspirez-vous à maîtriser les rouages de la Data Science et à concevoir des modèles prédictifs performants ? Notre formation Data Scientist & AI Engineer vous apprend à exploiter l’écosystème Python et le traitement intelligent des flux sémantiques, afin de propulser votre expertise vers les frontières de l’innovation moderne.
Merci pour votre lecture ! Si vous souhaitez découvrir nos prochains articles autour de la Data et de l’IA, vous pouvez nous suivre sur Facebook, LinkedIn et Twitter pour être notifié dès la publication d’un nouvel article !