Dans le vaste domaine de la statistique et de la Data Science, le coefficient de corrélation est l’outil fondamental qui permet de quantifier la relation entre deux variables. Il répond à une question simple mais cruciale : « Dans quelle mesure le changement d’une variable est-il lié au changement d’une autre ? ». Que ce soit pour corréler le budget publicitaire avec les ventes, ou la température avec la consommation d’énergie, ce coefficient offre une valeur mathématique précise qui évite de se fier à de simples intuitions.
Pour un analyste de données, un chercheur ou un décideur, comprendre la corrélation est le premier pas vers la modélisation prédictive. Cependant, il est impératif de garder en tête le mantra célèbre de la statistique : « Corrélation n’est pas causalité ». Deux phénomènes peuvent évoluer ensemble sans que l’un soit la cause de l’autre. Maîtriser ce concept, c’est savoir lire entre les lignes des données pour extraire des informations fiables et éviter les interprétations trompeuses au sein de votre système d’information.
1. Définition et fondements techniques : Le score de Pearson
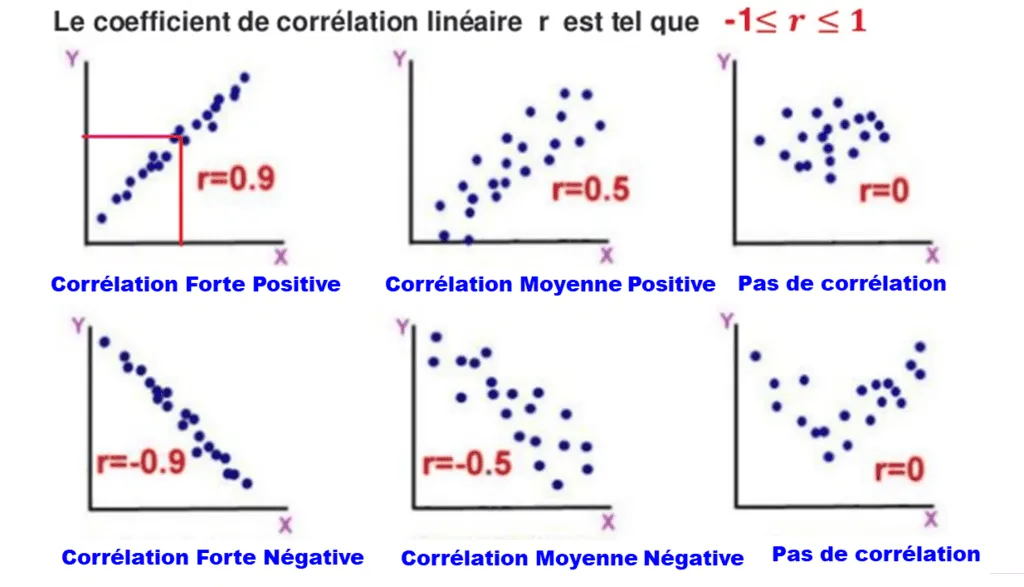
Le coefficient le plus utilisé est le coefficient de corrélation de Pearson, noté $r$. Il mesure la force et la direction d’une relation linéaire entre deux variables continues. Sa valeur est strictement comprise entre -1 et 1.
Voici comment interpréter le résultat :
- r = 1 : Corrélation positive parfaite. Les deux variables augmentent ensemble de manière proportionnelle.
- r = -1 : Corrélation négative parfaite. Quand l’une augmente, l’autre diminue exactement de la même façon.
- r = 0 : Aucune corrélation linéaire. Les variables semblent indépendantes l’une de l’autre.
Techniquement, le calcul repose sur la covariance des deux variables divisée par le produit de leurs écarts-types. Dans un environnement professionnel, on utilise rarement la calculatrice manuelle : le langage Python (avec la bibliothèque Pandas) ou des scripts SQL avancés permettent de calculer des matrices de corrélation sur des millions de lignes en quelques millisecondes. Ces traitements sont souvent orchestrés via des conteneurs Docker pour garantir la stabilité des calculs lors de la maintenance applicative.
2. À quoi sert ce domaine dans le monde professionnel ?
Le coefficient de corrélation est le moteur de l’analyse exploratoire dans presque tous les secteurs. Dans le Marketing et le E-commerce, il sert à identifier les leviers de croissance. Exemple concret : Un analyste calcule la corrélation entre le temps passé sur une page produit et le taux de conversion. Si $r = 0,85$, l’entreprise sait qu’améliorer l’engagement sur la page est une priorité stratégique pour booster les ventes.
Dans le domaine de la Finance et de l’Investissement, il permet de diversifier les portefeuilles. Cas d’usage technologique : Les gestionnaires d’actifs cherchent des actions qui ont une corrélation faible ou négative entre elles. Si le marché s’effondre dans un secteur, les actifs non corrélés protègent la valeur globale du portefeuille.
Pour la Maintenance Industrielle, il aide à prévenir les pannes. Exemple en entreprise : En corrélant les données de vibration d’une machine avec sa température de fonctionnement, les ingénieurs peuvent identifier des patterns précurseurs de casse. Ces analyses, souvent traitées sur le Cloud Computing, permettent de passer d’une maintenance réactive à une stratégie proactive.
3. Classement des 10 points clés de la corrélation
- Direction : Positive (montante) ou négative (descendante).
- Force : Plus la valeur absolue est proche de 1, plus le lien est solide.
- Linéarité : Pearson ne détecte que les relations en ligne droite.
- Coefficient de Spearman : Une alternative pour les relations non-linéaires mais monotones.
- Outliers (Valeurs aberrantes) : Une seule donnée extrême peut fausser totalement le coefficient.
- Nuage de points (Scatter Plot) : La visualisation indispensable avant tout calcul.
- Causalité vs Corrélation : Le lien mathématique ne prouve pas le lien de cause à effet.
- P-value : Mesure si la corrélation observée est statistiquement significative ou due au hasard.
- Matrice de corrélation : Un tableau croisé pour comparer plusieurs variables d’un coup.
- Standardisation : Le coefficient est indépendant des unités de mesure (mètres, euros, etc.).
4. Guide de choix : Pearson, Spearman ou Kendall ?
Le choix du coefficient dépend de la nature de vos données.
| Type de lien | Type de données | Coefficient recommandé |
| Linéaire | Continues (ex: Taille, Prix) | Pearson |
| Non-linéaire (Courbe) | Ordinales (ex: Classement) | Spearman |
| Petits échantillons | Données avec beaucoup d’exos | Kendall |
Pour ceux qui souhaitent devenir experts, les bootcamps en data science enseignent comment utiliser ces outils pour nettoyer les données avant d’entraîner des modèles d’intelligence artificielle. Savoir interpréter une corrélation est une compétence clé dans les métiers data qui recrutent, car elle permet de ne pas surcharger les modèles avec des variables redondantes.
5. L’impact de l’IA sur l’analyse de corrélation
L’intelligence artificielle a démultiplié la puissance de la corrélation. Cas technologique : Là où un humain peut corréler deux ou trois variables, les algorithmes de Machine Learning peuvent analyser des corrélations croisées entre des milliers de variables simultanément. Cela permet de découvrir des “signaux faibles” invisibles à l’œil nu.
En entreprise, l’IA facilite le nettoyage automatique. Exemple en entreprise : Un logiciel de Data Science identifie deux colonnes corrélées à 99 % (par exemple, le prix HT et le prix TTC). L’IA suggère d’en supprimer une pour optimiser les performances des bases de données SQL et éviter le phénomène de multicolinéarité qui dégrade les prédictions.
Enfin, l’IA permet de détecter des corrélations temporelles complexes via le NLP (Natural Language Processing) en analysant si des pics de discussions sur les réseaux sociaux sont corrélés à des variations de prix. Pour maîtriser ces outils d’IA, il est crucial de comprendre la base mathématique du coefficient de corrélation pour valider les découvertes de la machine.
6. Les pièges classiques : Attention aux erreurs !
Le piège le plus redoutable est celui de la variable cachée (ou facteur de confusion). Par exemple, il existe une forte corrélation entre les ventes de glaces et les coups de soleil. Pourtant, manger des glaces ne cause pas de coups de soleil : c’est le soleil (la variable cachée) qui cause les deux.
Un autre défi technique est la corrélation illusoire sur de petits jeux de données. La veille technologique recommande de toujours vérifier la signification statistique. Un coefficient de 0,9 sur 5 données n’a aucune valeur réelle. Il est donc indispensable d’utiliser des outils comme Python pour calculer l’intervalle de confiance du coefficient, garantissant ainsi la robustesse de votre analyse au sein du système d’information.
7. Conclusion et perspectives d’avenir
Le coefficient de corrélation en 2026 reste le socle de toute analyse rigoureuse. En transformant le chaos des données en une échelle de -1 à 1, il offre une clarté indispensable pour la prise de décision. À l’heure du Big Data, il est le filtre qui permet de séparer le bruit de l’information utile.
L’avenir se dessine vers des “Corrélations Dynamiques” calculées en temps réel sur des flux de données continus issus de l’IoT. Nous nous dirigeons vers un monde où les entreprises ne regarderont plus seulement le passé, mais utiliseront les corrélations instantanées pour ajuster leurs prix et leurs stocks à la seconde près. Maîtriser le coefficient de corrélation aujourd’hui, c’est s’assurer de posséder la boussole nécessaire pour naviguer dans l’océan de données de demain.
Aspirez-vous à maîtriser les rouages du Big Data et à concevoir des architectures de données massives ? Notre formation Data Analyst vous apprend à explorer l’écosystème distribué et le traitement de flux à grande échelle, afin de propulser votre expertise vers les frontières de l’ingénierie des données.
Merci pour votre lecture ! Si vous souhaitez découvrir nos prochains articles autour de la Data et de l’IA, vous pouvez nous suivre sur Facebook, LinkedIn et Twitter pour être notifié dès la publication d’un nouvel article !