Dans l’univers de l’analyse de données en 2026, prendre une décision sur une simple intuition est une faute professionnelle. L’ANOVA (Analyse de la Variance) est la méthode statistique de référence pour déterminer s’il existe des différences significatives entre les moyennes de trois groupes ou plus. Alors que le test de Student (t-test) se limite à deux groupes, l’ANOVA permet d’embrasser la complexité des scénarios réels sans augmenter artificiellement le risque d’erreur. C’est le juge de paix qui confirme si une variation observée est le fruit du hasard ou d’un véritable facteur d’influence.
Pour un professionnel de la tech, du marketing ou de l’industrie, maîtriser l’ANOVA est un gage de crédibilité scientifique. En 2026, alors que les entreprises sont submergées de données issues de tests A/B/C, savoir interpréter une “p-value” ou un “F-ratio” est ce qui permet de valider des investissements de plusieurs millions d’euros. Comprendre l’ANOVA, c’est passer de la simple observation à la démonstration statistique rigoureuse, garantissant que vos conclusions sont mathématiquement inattaquables.
1. Définition et fondements techniques du concept
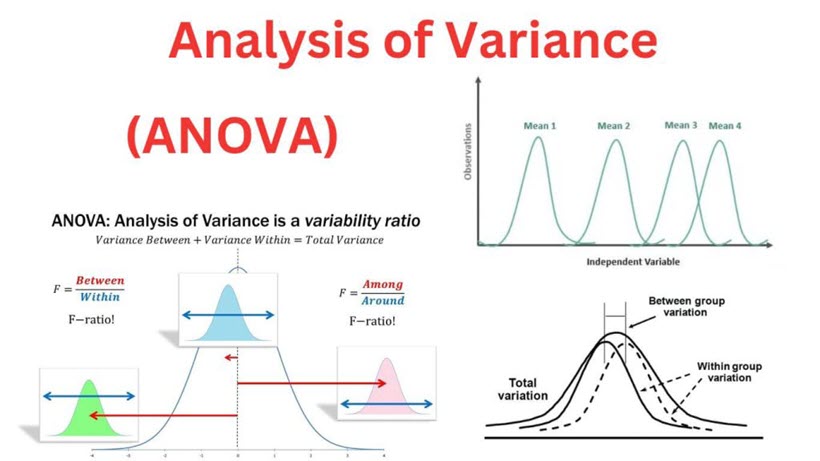
Pour vulgariser l’ANOVA, imaginez que vous testez trois types d’engrais différents sur des plants de tomates. À la récolte, vous remarquez que les poids moyens des tomates varient selon l’engrais. Mais attention : même avec le même engrais, deux tomates n’ont jamais exactement le même poids (c’est la variance naturelle). L’ANOVA va comparer la variation entre les groupes d’engrais à la variation à l’intérieur de chaque groupe. Si la différence entre les groupes est nettement plus grande que le “bruit” interne, alors l’engrais a un effet réel.
Techniquement, l’ANOVA repose sur le calcul de la statistique F. Ce ratio compare la variance inter-groupes à la variance intra-groupe (résiduelle).
- Si $F$ est proche de 1, les différences sont dues au hasard.
- Si $F$ est élevé, l’effet du facteur étudié est probable.Elle s’appuie sur trois hypothèses fondamentales : l’indépendance des échantillons, la normalité des distributions et l’homoscédasticité (égalité des variances entre les groupes).
En 2026, l’exécution de l’ANOVA ne se fait plus à la main, mais via le langage de programmation Python (bibliothèques SciPy ou Statsmodels) ou R. Les data scientists intègrent ces tests dans des pipelines automatisés hébergés sur le Cloud Computing pour traiter des volumes massifs. Pour garantir la reproductibilité des analyses, ces scripts tournent souvent dans des environnements isolés, ce qui rend crucial de savoir gérer ses outils avec Docker.
2. À quoi sert ce domaine dans le monde professionnel ?
L’ANOVA est le moteur de l’expérimentation moderne. Dans le Marketing Digital, elle permet d’optimiser les campagnes. Exemple concret : Une plateforme e-commerce comme Zalando teste quatre designs différents pour sa page de paiement. L’ANOVA permet de confirmer si l’un des designs génère réellement plus de ventes, ou si les différences observées sont simplement dues aux variations quotidiennes du trafic, évitant ainsi un changement d’interface inutile et coûteux.
Dans le secteur de la Pharmacie et Santé, elle est vitale pour valider les dosages. Cas d’usage technologique : Lors d’un essai clinique, on compare l’efficacité d’un nouveau médicament à trois dosages différents (faible, moyen, fort) et un placebo. L’ANOVA détermine si la dose influence la guérison. Ce processus est strictement encadré par des protocoles de cybersécurité pour protéger les données des patients, car une erreur de calcul ou une fuite de données compromettrait l’homologation du traitement.
Pour l’Industrie 4.0, elle optimise la maintenance applicative et matérielle. Exemple en entreprise : Une usine automobile compare l’usure de pièces produites par cinq machines différentes. L’ANOVA identifie si une machine dévie de la norme de qualité. Couplé à un dashboard piloté par Power BI, ce test statistique permet de déclencher une maintenance préventive uniquement sur l’équipement défaillant, optimisant ainsi les coûts de production.
3. Classement des 10 points clés ou composants essentiels en 2026
- L’Hypothèse Nulle ($H_0$) : Le postulat de départ selon lequel il n’y a aucune différence entre les groupes.
- La Somme des Carrés (SS) : La mesure de la dispersion totale des données.
- Les Degrés de Liberté (df) : Le nombre de valeurs indépendantes dans le calcul statistique.
- Le Carré Moyen (MS) : La variance estimée (SS divisée par df).
- La Statistique F : Le ratio final qui détermine la significativité du test.
- La P-value : La probabilité que les résultats soient dus au hasard (généralement significative si < 0,05).
- L’ANOVA à un facteur (One-way) : Pour comparer des groupes basés sur une seule variable (ex: l’engrais).
- L’ANOVA à deux facteurs (Two-way) : Pour étudier l’effet de deux variables et leur interaction (ex: engrais + ensoleillement).
- Les Tests Post-hoc (Tukey, Bonferroni) : Réalisés après l’ANOVA pour identifier précisément quels groupes diffèrent entre eux.
- L’Indice de taille d’effet (Eta-carré) : Pour mesurer l’ampleur réelle de la différence, au-delà de sa simple existence statistique.
4. Guide de choix selon votre projet professionnel
L’utilisation de l’ANOVA demande une rigueur méthodologique qui dépend de votre rôle dans la chaîne de valeur de la donnée.
| Profil | Stratégie recommandée | Outils à privilégier | Objectif métier |
| Étudiant | Comprendre la logique de variance | Excel (Data Analysis), JASP | Valider ses premières hypothèses |
| Reconversion | Focus interprétation et reporting | Power BI, SPSS | Devenir Data Analyst Junior |
| Expert IT | Automatisation des tests | Python (Pandas, Statsmodels) | Architecte de pipelines de données |
| Data Scientist | Modélisation complexe (MANOVA) | R (Ggplot2), Jupyter Notebooks | Maîtriser la data science prédictive |
Pour ceux qui souhaitent monter en compétence, les bootcamps en data science et statistiques sont essentiels. Exemple technologique : Apprendre à coder une ANOVA en Python pour analyser les performances de différents frameworks de développement Web permet de choisir la technologie la plus rapide sur des bases purement scientifiques.
5. L’impact de l’intelligence artificielle sur l’ANOVA
En 2026, l’IA ne remplace pas l’ANOVA, elle l’automatise et la fiabilise. Cas technologique : Les outils de “Auto-Stats” utilisent l’intelligence artificielle générative pour vérifier automatiquement si vos données respectent les conditions de l’ANOVA (normalité, variance). Si une condition n’est pas remplie, l’IA suggère instantanément une transformation de données ou un test non-paramétrique alternatif (comme le Kruskal-Wallis).
En entreprise, l’IA facilite l’interprétation des résultats. Exemple en entreprise : Un chef de produit chez Ubisoft analyse l’engagement des joueurs sur trois versions d’un niveau. L’IA exécute l’ANOVA, réalise les tests post-hoc et rédige un compte-rendu en langage naturel : “La version B est statistiquement supérieure avec une confiance de 99%, principalement grâce à la mécanique de saut”. Cela démocratise la data science pour les décideurs non-mathématiciens.
Enfin, l’IA permet d’étendre l’ANOVA à des dimensions massives. On parle d’ANOVA à grande échelle où l’IA peut isoler l’impact de centaines de facteurs simultanément dans des environnements de Big Data. Cela permet d’identifier des micro-tendances invisibles à l’œil nu, transformant le SI de l’entreprise en un laboratoire d’expérimentation continue et ultra-précis.
6. Comprendre les paradigmes et concepts avancés
Un concept fondamental souvent négligé est l’Interaction. Dans une ANOVA à deux facteurs, l’interaction se produit quand l’effet d’une variable dépend du niveau de l’autre. Exemple technologique : Un nouveau mode “nuit” sur une application peut augmenter le temps d’utilisation sur smartphone mais le réduire sur tablette. Sans l’analyse de l’interaction, vous pourriez conclure à tort que le mode nuit n’a aucun effet global.
Un autre paradigme avancé est l’ANOVA à mesures répétées. On l’utilise quand les mêmes sujets sont testés plusieurs fois (ex: avant, pendant, après une formation). Cela permet de supprimer la variabilité individuelle pour se concentrer uniquement sur l’évolution temporelle. C’est la méthode reine pour évaluer l’efficacité des bootcamps de formation tech sur la progression réelle des étudiants.
L’intégration de l’ANOVA dans des micro-services via Docker pour standardiser les calculs permet une scalabilité horizontale. Une entreprise peut lancer des milliers de tests ANOVA en parallèle sur des serveurs Cloud pour valider des hypothèses sur différents segments de clientèle simultanément, garantissant une agilité décisionnelle totale.
7. L’évolution historique : de l’agriculture à la Data Science
L’ANOVA est le fruit d’une nécessité pragmatique devenue standard mondial :
- 1920s : Ronald Fisher développe l’ANOVA pour optimiser les récoltes agricoles en Angleterre. Il cherchait à isoler l’effet des sols et des engrais.
- 1950s : L’ANOVA se répand dans les sciences sociales et la psychologie pour valider les comportements de groupes.
- 1980s : L’informatique permet de traiter des ANOVA complexes (MANOVA, ANCOVA) qui prenaient auparavant des jours de calcul manuel.
- 2010s : L’ANOVA devient un outil standard du marketing digital (A/B testing) et de l’optimisation industrielle (Six Sigma).
- 2026 : L’ANOVA s’intègre aux moteurs d’IA pour fournir une validation statistique en temps réel aux décisions automatisées des entreprises “Data-Driven”.
8. Idées reçues, limites et défis techniques
L’idée reçue la plus courante est que “si la p-value est < 0,05, alors l’effet est important”. C’est faux. Une p-value indique seulement que la différence est probable, pas qu’elle est grande. Le défi de 2026 est de toujours coupler l’ANOVA à un calcul de la “taille d’effet” pour savoir si la différence, bien que réelle, justifie l’investissement nécessaire pour changer de stratégie.
Une limite technique majeure est la sensibilité aux “Outliers” (valeurs aberrantes). Exemple en entreprise : Si un seul utilisateur dépense un million d’euros par erreur sur votre site, il va fausser la moyenne de son groupe et rendre l’ANOVA invalide. Le défi de la Data Science en amont est de nettoyer rigoureusement les données avant de lancer le test.
Enfin, le défi de la Multiplicité : si vous faites 100 tests ANOVA à la suite, vous finirez par trouver un résultat “significatif” par pur hasard (le problème des comparaisons multiples). La maîtrise des corrections statistiques (comme celle de Bonferroni) est donc le seul rempart pour éviter de fausses découvertes qui pourraient induire la direction de l’entreprise en erreur.
9. Conclusion et perspectives d’avenir
L’ANOVA en 2026 reste la boussole de la vérité scientifique dans un océan de données incertaines. En permettant de comparer objectivement plusieurs stratégies, elle transforme le management en une discipline de précision. À l’heure de l’IA, elle apporte la couche de validation humaine et mathématique nécessaire pour s’assurer que les algorithmes ne nous emmènent pas sur de fausses pistes.
L’avenir se dessine vers une intégration totale de la statistique fréquentiste (ANOVA) et bayésienne au sein d’interfaces naturelles. Nous nous dirigeons vers un monde où poser une question à son système d’information déclenchera automatiquement les tests de variance les plus adaptés. Maîtriser l’ANOVA aujourd’hui, c’est s’assurer d’être l’arbitre éclairé des performances de demain.
Aspirez-vous à maîtriser les rouages du Big Data et à concevoir des architectures de données massives ? Notre formation Data Engineer & Ops vous apprend à explorer l’écosystème distribué et le traitement de flux à grande échelle, afin de propulser votre expertise vers les frontières de l’ingénierie des données.
Merci pour votre lecture ! Si vous souhaitez découvrir nos prochains articles autour de la Data et de l’IA, vous pouvez nous suivre sur Facebook, LinkedIn et Twitter pour être notifié dès la publication d’un nouvel article !